CUDA编程
简介
- CUDA是NVIDIA于2006年发布的一个基于NVIDIA的GPU的通用并行计算平台和编程模型;
- CUDA可以利用GPUs的并行计算引擎来更加高效地解决复杂的计算难题;
架构
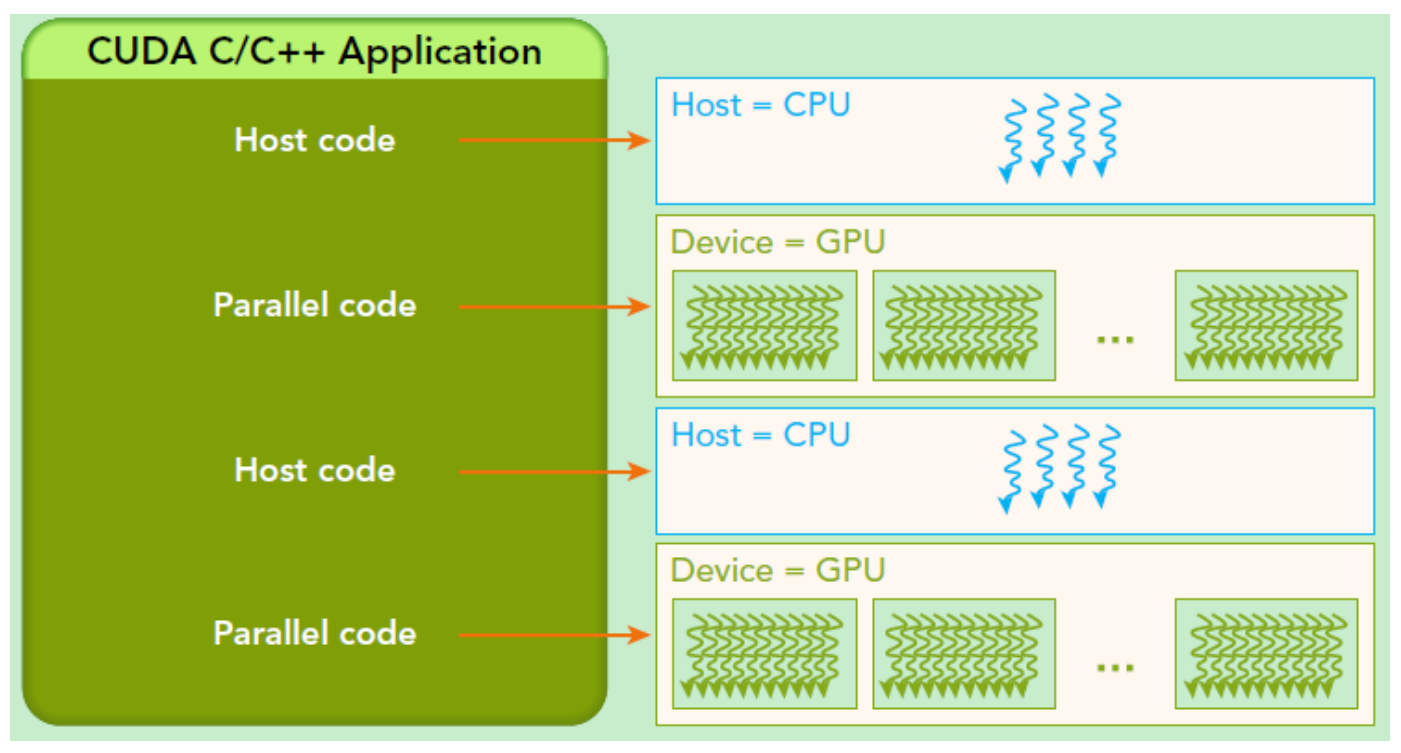
- CUDA是基于CPU+GPU的异构计算架构, 此时, GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)

编程模型
- CUDA中有2个重要的概念host和device,host: 指代CPU及其内存,device指:GPU及其内存。
- CUDA程序中的host与device之间可以进行通信,进行数据拷贝;
- 典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
函数限定符
CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
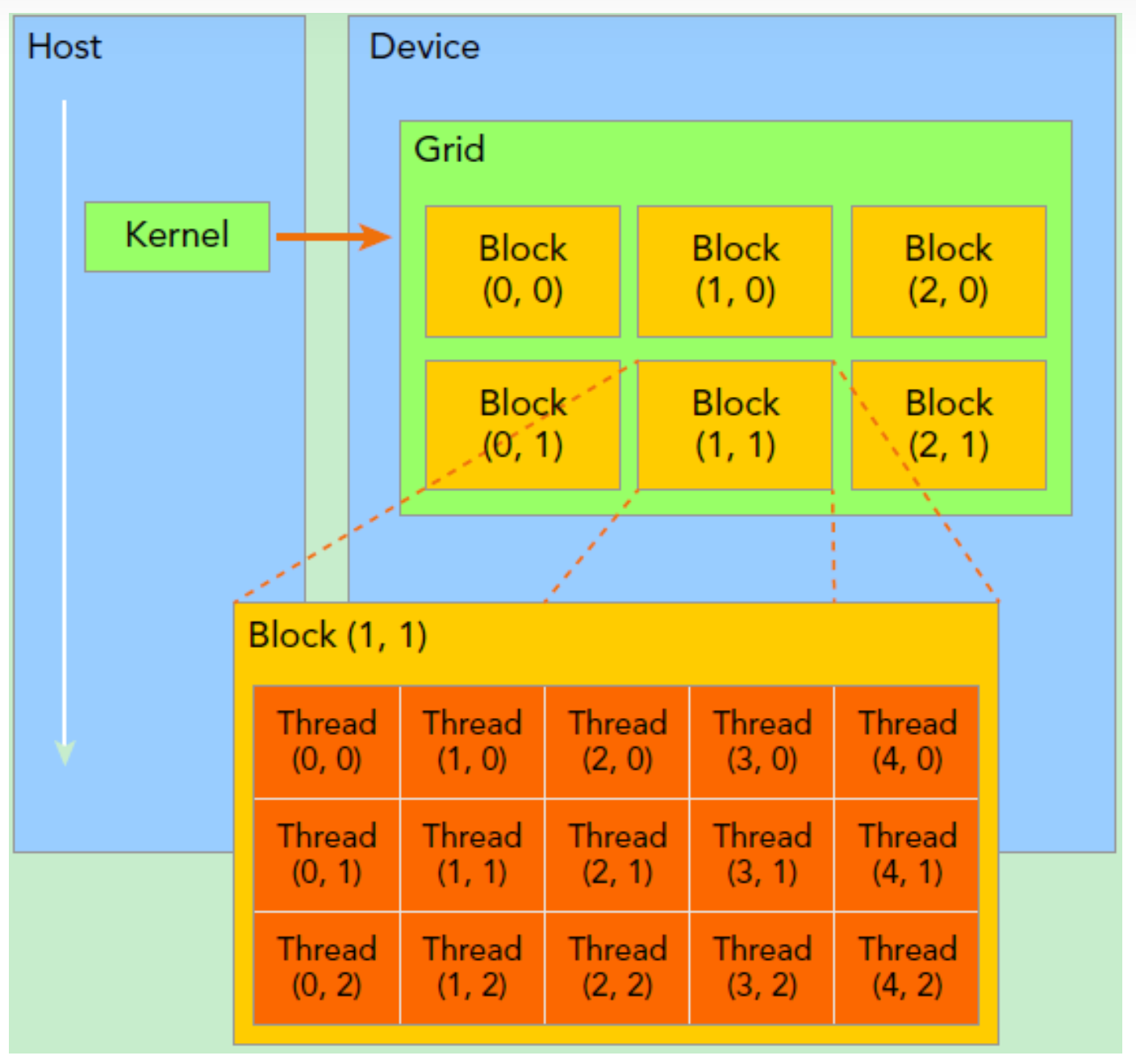
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
内存模型
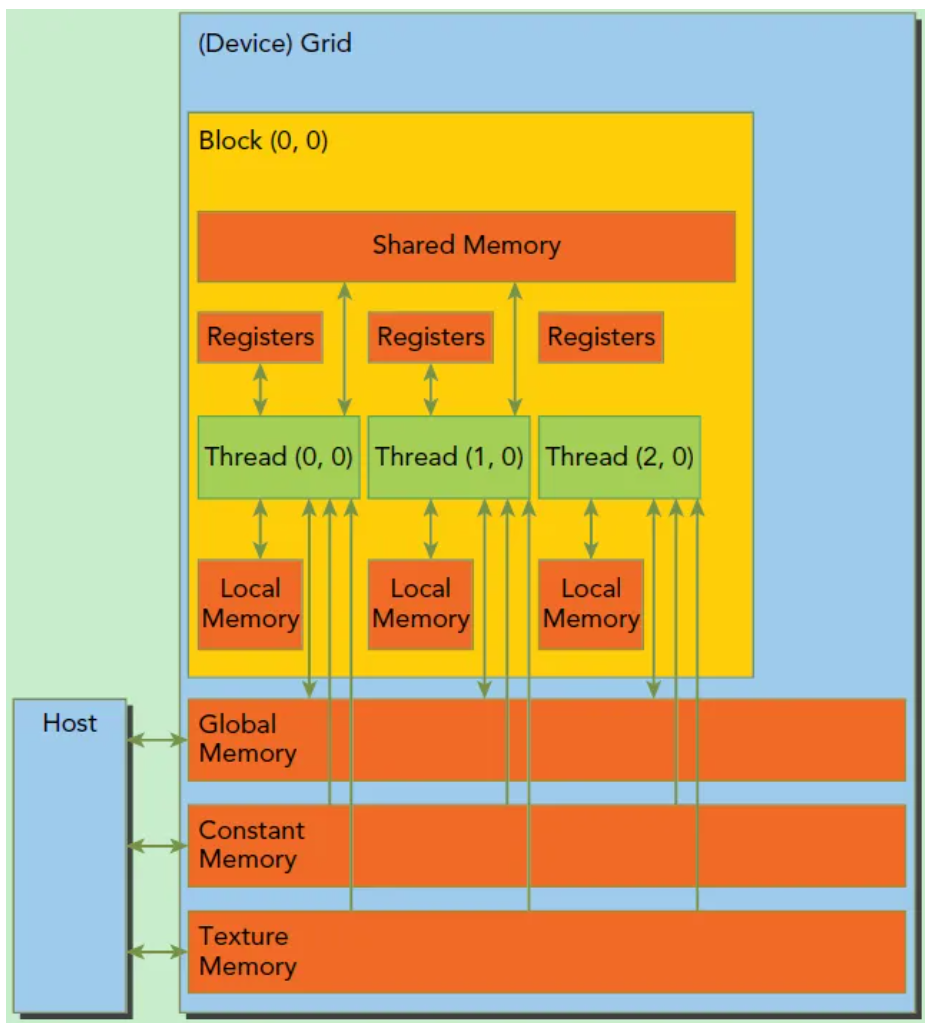
每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)
实例
| |
矩阵乘法实例
| |