CubeFS-BlobStore
简介
CubeFS-BlobStore是一个高可靠、高可用、低成本、支持超大规模(EB)的分布式存储系统。
采用纠删码中的Reed-Solomon编码,对比三副本,以更低的存储成本提供更高的数据耐久性保障,支持多种纠删码模式和多可用区部署,
同时针对小文件做了专门优化,可满足不同业务场景的存储需求。
架构
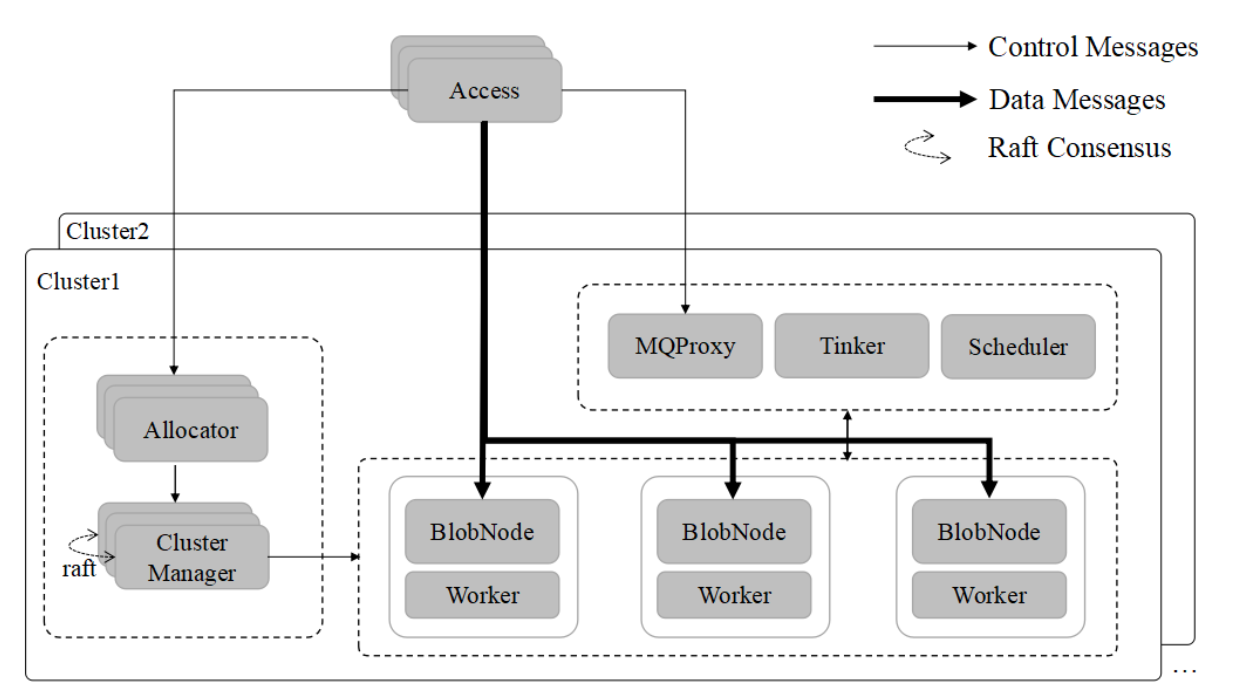
组件
blobstore包含如下组件:
| 模块 | 描述 | 功能 | 依赖组件 | 本地存储 | 部署 | 部署数量 |
|---|---|---|---|---|---|---|
| ClusterMgr | 集群管理 | 负责集群管理和卷的生成 | consul | 有 | 可跨机房部署,多机房 | >=3 |
| Allocator | 集群管理代理 | 提供数据写入资源id的分配 | ClusterMgr | 无 | >=1 | |
| Access | 接入模块 | 对外提供数据读、写和删除接口 | Redis,consul | 无 | 单节点部署,一个机房部署一个, | >=1 |
| BlobNode | blob存储 | 提供存储资源 | ClusterMgr | 有 | ||
| Worker | blob任务执行模块 | 卷修补、迁移和回收任务执行模块 | BlobNode,Scheduler | 无 | >=1 | |
| Scheduler | 异步任务调度中心 | 卷修补、迁移和回收任务的生成和调度 | mongodb | 无 | 一个cluster至少一个 | >=1 |
| MQProxy | 异步消息代理 | 修补和删除操作消息保存模块,用于后续异步执行 | kafka | 无 | >=1 | |
| Tinker | 后台数据整理管理模块 | 修补和删除操作异步执行模块 | kafka,mongodb | 无 | >=1 | |
| Cli | cli工具 | 提供cli管理操作 | consul,redis | 无 | >= | |
| Consul | 注册管理 | 提供节点、组件注册; | 必选 | |||
| MongoDB | mongodb | 为scheduler提供存储 | 必须 | |||
| Kafaka | 消息队列服务 | scheduler任务调度消息队列 | 必须 | |||
| Redis | 缓存服务 | 为access,cli访问clustermgr提供缓存加速 | 可选 | |||
| Zookeeper | 为kafka提供注册服务 |
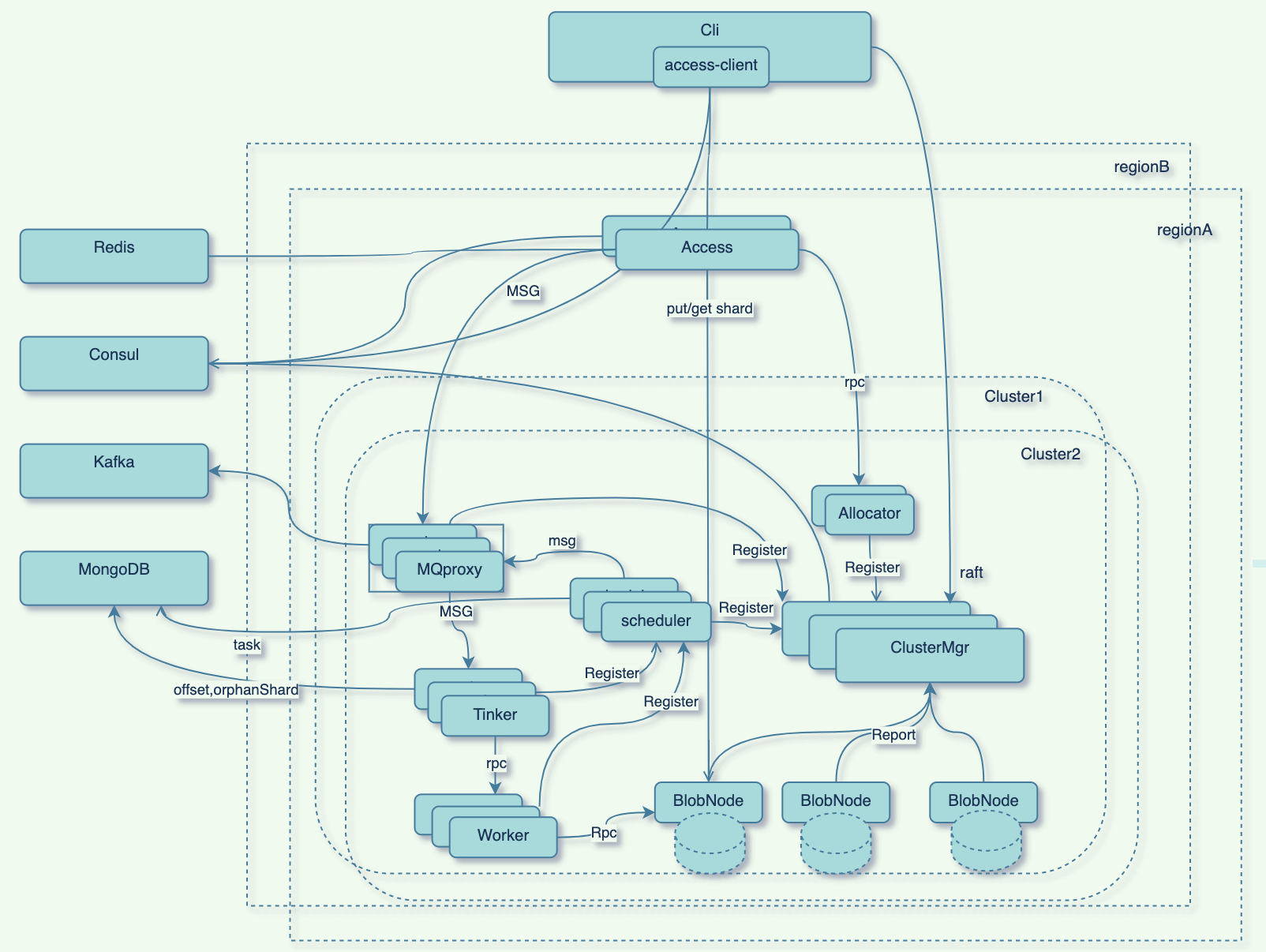
资源
Region(区域): 一个region可包含多个cluster;
Cluster(集群):一个Cluster是由多个相同cluster_id的clustermgr组成,可以提供完整的Blobstore服务的单位。cluster可以跨机房部署,多个跨机房clustermgr通过raft组成一个cluster;
Idc(数据中心/机房): 一个cluster可以跨多个idc部署;
Rack(机架):机房内一个机柜; 同一机架内的机器在一个交换机内,可以拥有很低的网络访问延迟和很高的网络带宽;
AZ(Available Zone):EC 中数据块的有效分区数,一个集群中,AZ的数量要和 IDC个数匹配;
Node(节点): 对应一台物理机或容器实例;
Disk(物理磁盘): 一块已格式化好,并被挂载到某一目录的物理磁盘或一个目录;
Chunk(数据簇):每个Disk的空间被划分为多个Chunk,Chunk对应一个Chunk File;
Volume(逻辑卷): 逻辑卷是面对用户的存储资源管理抽象视图,一个Volume包含多个Unit;
Unit(逻辑卷数据单元): 逻辑卷的数据组织单元。Unit主要包含了Vuid和bid两个字段;
Location(定位):数据在blobstore中的定位,一个location中的数据由多个blob组成;
Blob(数据段): Blob是location中的一段数据,每个Blob是EC编解码的一个数据块, Blob最大默认:4MB;
Shard(数据分片):一块Blob数据在ec encode时,根据编码策略,切分成多个分片Shard,每个分片称为一个shard;
EraserCode
| |
Table
| |
组件详情
Access(访问接入点)
access是面向client,提供访问api接口的组件;
access为无状态节点;
一个access为一个
region下的所有cluster提供访问接入点;access主要提供如下rpc:
/put: put数据,动态分配location, 默认最大size:5GB;
/putAt: 将数据put到指定的location;
/get: 根据location读取数据;
/delete:删除指定location的数据;
/deleteblob: 删除指定blob;
/alloc: 分配blob;
/sign: 签名;
启动时,会从
consul_agent_addr获取配置region的cluster信息加载到当前节点内存中;
| |
- 配置文件
| |
Access Client
access client 为访问access 提供api;
access client api通过配置文件中的
PriorityAddrs或consul 来连接access;每次api发送请求时,会从发现的所有access中随机选择
MaxHostRetry(默认:3)个依次给access发送api请求,如果一个请求发送成功,则成功返回;access client 主要 提供3个api:
Put(): 写入数据, 返回数据location;
Get(): 根据location,获取数据内容;
Delete(): 删除指定location的数据;
| |
Allocator(资源分配器)
allocator主要为accessor提供volume/alloc, list两个接口,负责vid,bid的分配;
allocator启动时,将自身组成到clustermgr的服务中;
allocator内置了
volumeMgr,bidmgr;volumeMgr:负责volume的分配的管理。启动时,开启后台线程,将clusterMgr上的所有
volInfo加载到allocate内存中;bidMgr:负责volume 的bid range分配;
rpc:
/volume/alloc:
/volume/list:
配置文件:
| |
ClusterMgr(集群管理器)
clustermgr用于集群相关信息的管理;
clustermgr内部由多个管理器组成,包括:
ServiceMgr(服务管理):管理集群中的各个Service, 包括:allocator,mqproxy, tinker;
ConfigMgr(配置管理): cluster_config, 集群的全局配置;
VolumeMgr(逻辑卷管理):负责volume的allocate,状态监测等, ;
DiskMgr(磁盘管理):管理集群内所有blobnode磁盘;
ScopeMgr(Bid管理):id分配管理;
clustermgr内置kvdb(目前为rocksdb)来保存各种管理器的相关数据;
多个clustermgr通过raft保证kvdb数据在多个节点的同步以保证高可用;
clustermgr周期性(参数
cluster_report_interval_s,默认:60s)的将clusterinfo汇报给consul_agent_addr上,以ebs/<region>/clusters/<clusterID>:<clusterInfo>;leader clustermgr周期性的(默认: 10s)检查并更新disk状态;
| |
Cluster(集群)
一个cluster由多个cluster_id相同的多个clustermgr节点组成;
一个cluster中的多个clustermgr通过raft组成一个raft group进行数据复制同步;
一个region中可包含多个cluster,同一region下的cluster注册为consul下的多个服务;
数据put时,access根据配置的region,会随机在region下选择一个cluster来put数据,返回的location中包含cluster_id用以指明所在cluster;
Volume(卷)
Volume是数据管理逻辑单元,是面向客户端的数据视图;
基本信息
vid(32bits)
CodeMode: 编码模式
Status: 状态
HealthScore: 健康分
Total: 总空间
Free: 可用空间
Used: 已使用空间
CreateByNodeID: 创建NodeID
Volume Status
idle: volume刚创建时,尚未被分配的volume状态;
active: volume分配给某一个allocator后的状态;
lock:
unlocking
| |
BlobNode
BlobNode是blob管理节点,提供数据的blob存储管理;
blobnode启动时,将扫描并加载配置文件下的disk,然后后
clusterMgr上已有的disk进行对比,如果clusterMgr中not found,则AddDisk到clusterMgr的管理器中;启动时开启如下全局协程:
loopHeartbeatToClusterMgr(): 周期性(默认:30s)维持和
clusterMgr间的心跳;loopReportChunkInfoToClusterMgr():周期性(默认:57s)向
clusterMgr汇报chunkInfo;loopGcRubbishChunkFile(): 周期(默认:60min)检查chunkfile,执行垃圾回收任务;
loopCleanExpiredStatFile(): 周期()清理过期stat文件(/tmp/shm/目录下的iostat文件);
blobnode中disk
blobnode中disk由配置文件中
disks项指定,一个blobnode可以包含多个disk;blobnode启动时,先通过rpc从
clusterMgr获取该host所有已经注册的disk;然后根据配置文件, 逐个加载disk;
每个disk包含.sys, meta等子目录,
.sys目录里面保存disk的格式相关信息;
.meta里面使用rocksdb来记录chunk相关的元数据信息;
.data目录包含chunkfile;
blobnode disk加载流程:
通过配置文件获取disk根目录;
加载磁盘format信息。通过读取.sys目录下的format.json内获取disk format信息(包括DiskID), 如果该文件不存在,则从
clusterMgr分配一个新的DiskID, 并注册disk到clusterMgr的table中;打开meta目录下的rocksdb,初始化化superblock;
从meta db中读取
diskinfo来加载diskinfo;设置disk iostat 相关数据结构;
启动loop相关后台协程
ds.loopCleanChunk: 清理已released 的chunk;ds.loopCompactFile: compact chunk file;ds.loopDiskUsage:ds.loopCleanTrash:ds.loopMetricReport:
加载好的diskStorage记录在map[diskID]
Disks中;
blobnode rpc:
/chunk/create
/chunk/release
/chunk/compact
…
/shard/get/…
/shard/put/….
/shard/delete/…
配置文件
| |
存储格式
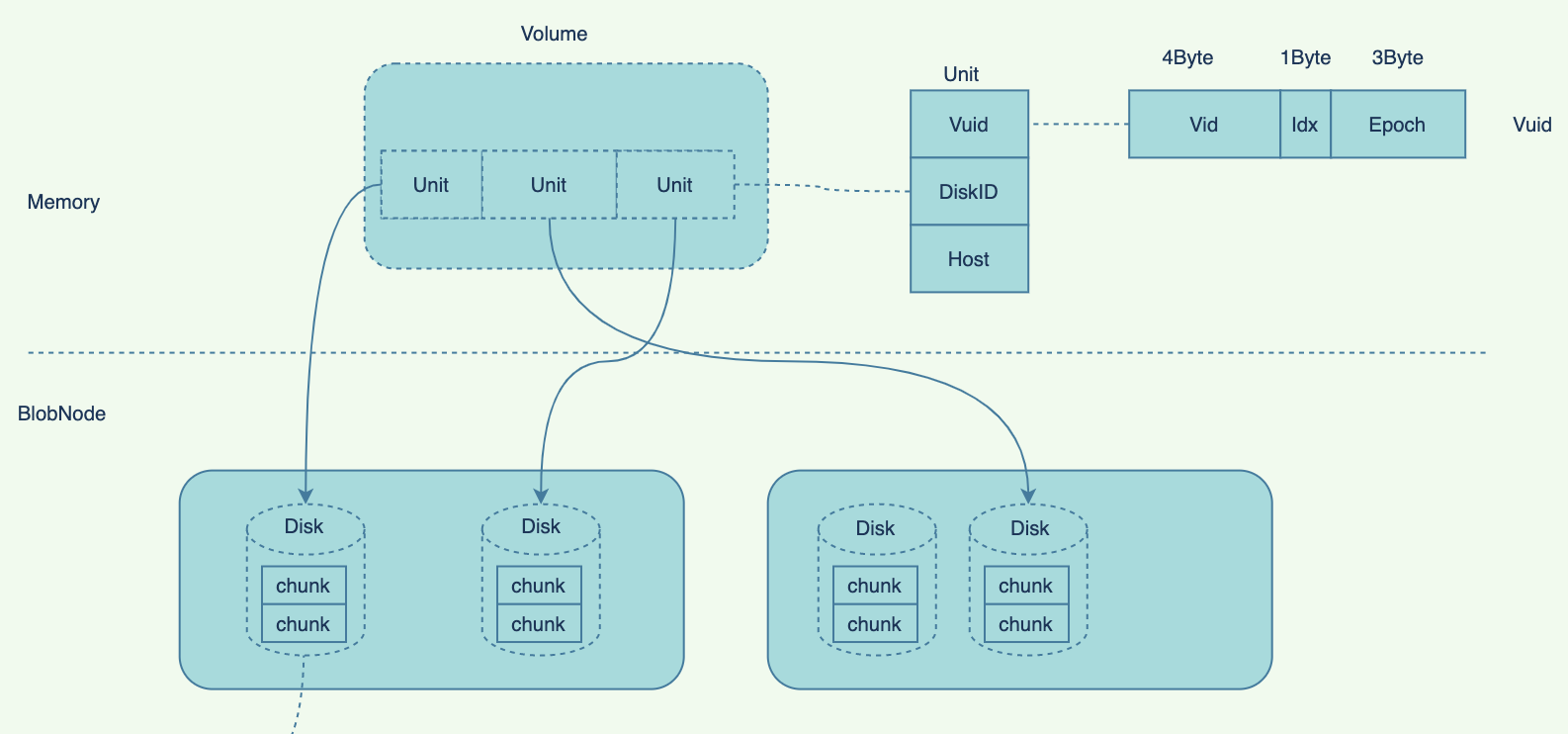
- volume->chunk
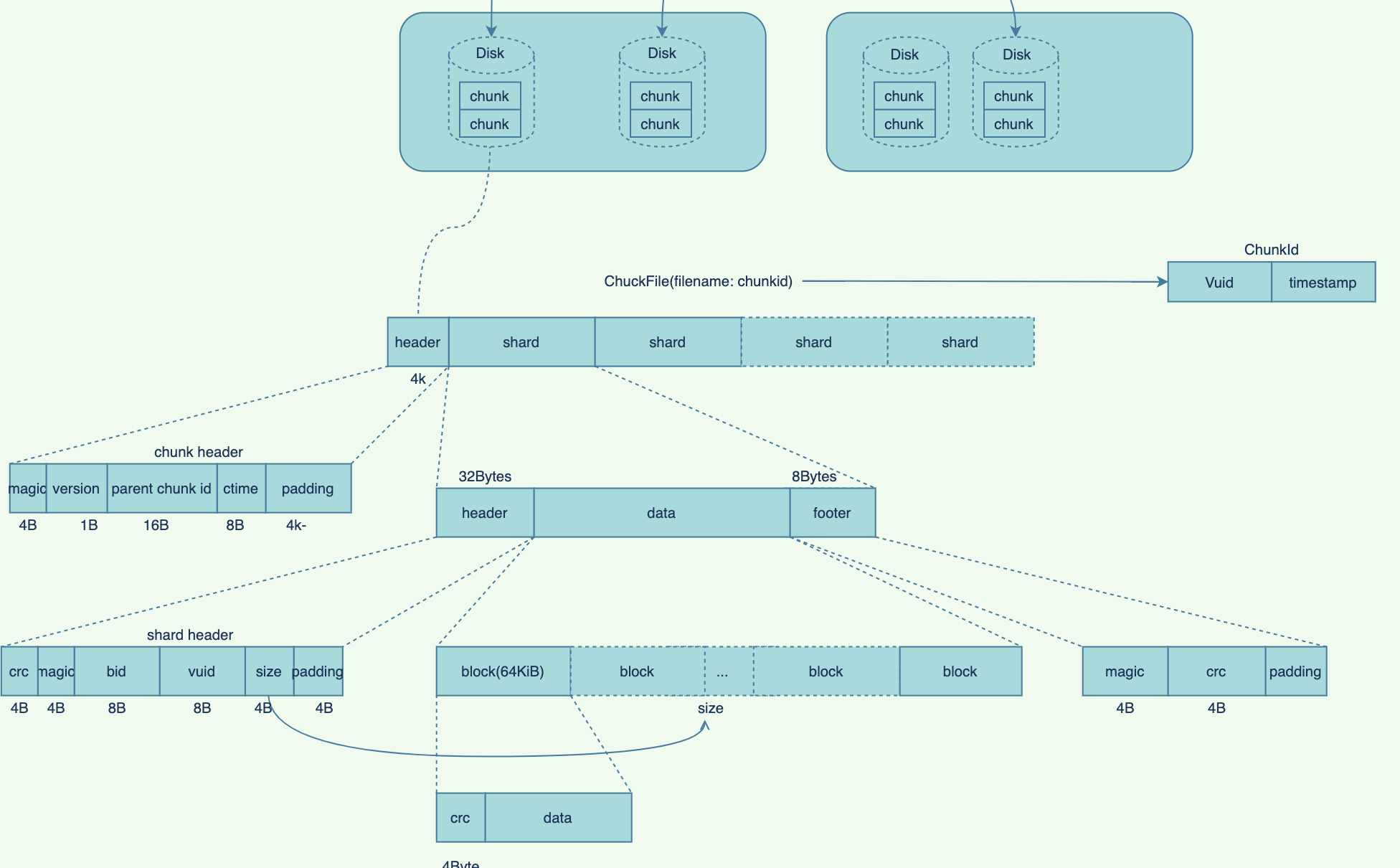
- chunk->shard
Disk(磁盘)
Disk是BlobNode节点上一个格式化后挂载到某一目录的物理磁盘,用来存储具体的数据;
Disk基本信息包括:
DiskID: 磁盘ID(uint32), 1~1^31-1;
ClusterID: 所属ClusterID(uint32);
Idc: Idc
Path:
Host:
Status
ReadOnly: 是否只读
Disk Status包括:
Normal: 正常
Broken:
Repairing
Repaired
Droped
| |
Chunk
Chunk是对Disk上具体数据的一种抽象,当前的chunk实现为一个file;
chunk file 位于disk的data目录下, 以chunkID为名的file;
chunkID组成:
vuid+<创建chunk时的时间戳>;每个chunk由多个连续的shard组成,
一个disk默认最多chunk数
DefaultMaxChunks:8192;一个chunk默认最大size
DefaultMaxChunk: 1TiB;默认chunk size
DefaultChunkSize:16GiB;
chunk status:
Default:
Normal:
ReadOnly:
Release:
| |
Shard
shard是chunk中用于存储一个ec编码
shard status:
Default:
Normal:
MarkDelete:
MQProxy(消息代理)
- mqproxy为kafka mq代理,作为异步消息传输通道;
- 启动时,将自身作为 service注册到
clustermsg中的service table中; - mqproxy接收
access下发的shardRepardMsg和blobDeleteMsg消息,发送到kafka中,最后被scheduler消费; - scheduler中的
inspectMgr在巡检时,如果发现丢失的shard,将给mqproxy发送shardRepairedMsg; - 提供rpc接口:
- /repairmsg: shard修复消息;
- /deletemsg: blob删除消息;
| |
Scheduler(任务调度器)
scheduler提供所在cluster后台任务调度服务;- 内置多种管理器,来对各种任务进行管理:
- ClusterTopoMgr: 集群拓扑管理器, 周期性(默认:5min)的从
clustermgr获取配置集群的disk信息,然后构建拓扑信息; - BalanceMgr:数据平衡管理器, 周期性(默认:5s)收集disk分布情况,构建MigrateMgr任务,使数据自动保证平衡;
- MigrateMgr: 迁移管理器, 分为自动、手动迁移管理器两种。自动迁移管理器由BalanceMgr管理;手动迁移管理器由api调用触发:
- DiskDropMgr:下线磁盘管理器,负责;
- RepairMgr:shard修复任务管理器,管理下发shardreapirmsg task;
- InspectMgr: 巡检管理器, 巡检vol,发现坏的blob时,给mqproxy发送
ShardRepairMsg;
- ClusterTopoMgr: 集群拓扑管理器, 周期性(默认:5min)的从
- 启动时,先根据配置文件初始化各个管理器 ,再从mongo中加载已有的task,最后使各个mgr run起来;
- scheduler内置service table, tinker和worker组件在启动时,会将自身注册到scheduler的service table中;
- 各管理器生成task,并插入到相应的mongdb task table中;
| |
- rpc:
| |
Tinker(修补器)
- 启动时,将自身注册到
scheduler的service服务列表中; - 内置
shardRepairMgr,BlobDeleteMgr, 执行shard repair,blob delete任务; - 从kafka mq中消费相应的消息, 并通过rpc通知
worker执行相应的任务; - tinker使用mongodb保存kafka offset和
orphanShard; - rpc:
- /update/vol:
- /stats:
| |
Worker()
执行tinker下发(rpc api)的shard repair, blob delete任务;
启动时,将自身注册到
scheduler的service 列表中;周期性(默认: 500ms)的从
scheduler获取task(调用scheduler rpc:/task/acquire), 并执行task(包括: Repair, Balance, DiskDrop, ManualMigrate, Inspect);rpc api:
/shard/repair
/stats
| |
Cli
cli是blobstore提供的一个命令行工具,用于对blobstore进行管理操作;
cli通过
access-clinetapi 提供和access交互的能力;cli可配置redis来缓存;
| |
外部组件
Consul
- 提供cluster信息注册,查询服务;
| |
MongoDB
mongodb用于存储scheduler模块调度信息;
| db | dafault table | config key | 说明 | 模块 |
|---|---|---|---|---|
| scheduler | “database:db_name” | scheduler.conf | ||
| balance_tbl | ||||
| disk_drop_tbl | ||||
| repair_tbl | ||||
| inspect_checkpoint_tbl | ||||
| manual_migrate_tbl | ||||
| svr_register_tbl | ||||
| tasks_tbl |
Kafka
用于组件间异步 任务消息传递, mqproxy对其相关操作进行封装;
主要用来传递
shardRepair和blobDelete两类消息;
Redis
为access访问cm volume提供缓存;
缓存expires:30-60min;
| |
参数
BlobNode
一个disk默认最多chunk数
DefaultMaxChunks:8192;一个chunk默认最大size
DefaultMaxChunk: 1TiB;默认chunk size
DefaultChunkSize:16GiB;
| |
关键流程
创建卷(CreateVolume)
ClusterMgr启动后,会根据配置为每种ec策略预先创建一定数量的Volume用于分配;入口为clusterMgr中volumeMgr的
createVolume()函数;先通过
scopMgr.Alloc分配一个新vid;根据mode获取unitCount(为tactic的N+M+L);
初始化volume units信息vuInfos;
初始化volInfo;
通过raft执行initCreateVolume指令,将volume信息记录到transitedTable中;
通过
allocChunkForAllUnits为vol所有的units分配chunk;allocChunkForAllUnits会根据vol的编码策略,将chunk随机分布到不同idc上;
通过blobnode ChunkCreate rpc调用在blobnode上创建chunk;
通过raft执行CreateVolume指令,删除transitedTbl中的volume units,将volume units相关信息记录到volumeTbl中 ;
写入(Put)
put提供将数据写入到blobstore中的能力;
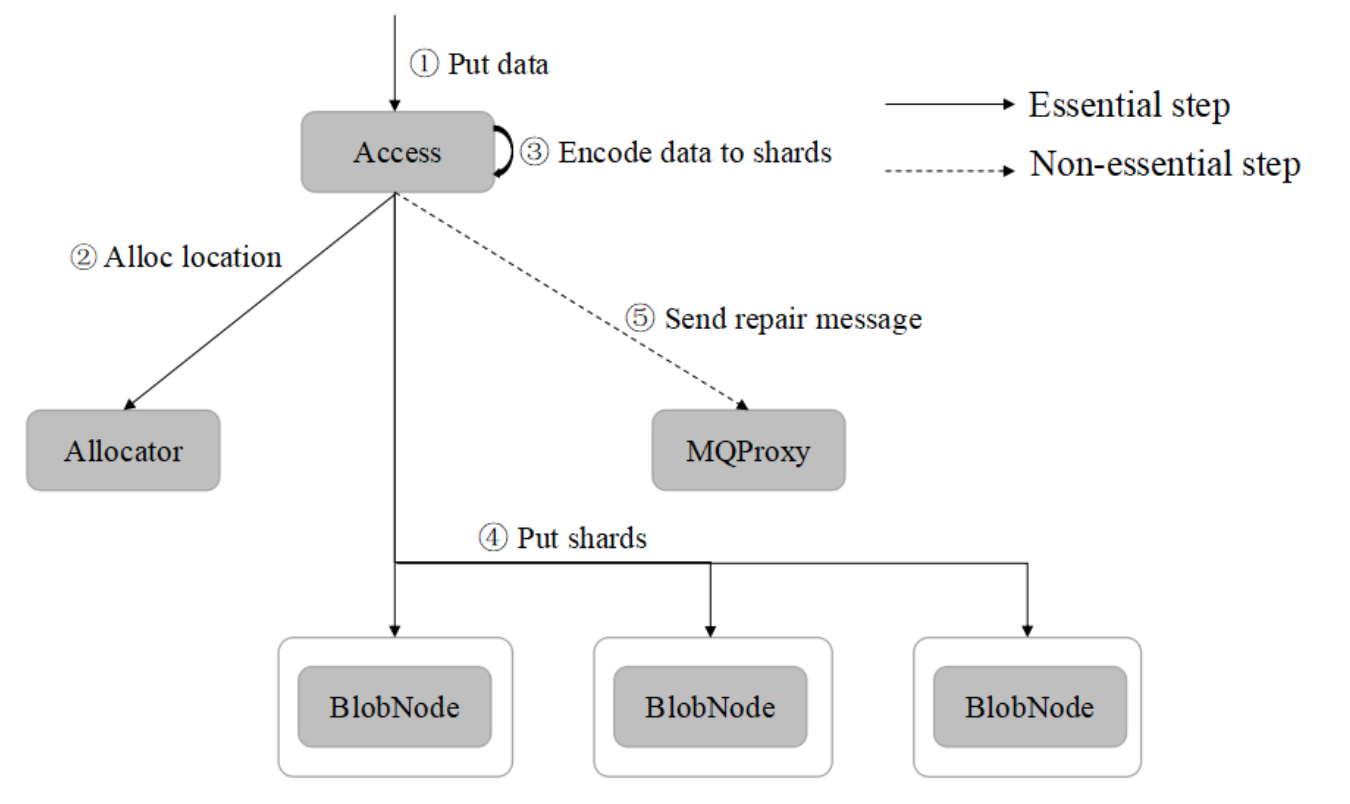
Put流程从access-client中的Put()方法开始:
access-client
access-client
Put()流程:根据数据判断,如果size == 0, 返回空location;
Size <= MaxSizePutOnec(默认:256MB) ,通过
putObject()单个对象上传;否则,通过
putParts分块上传:
putObject流程:
数据size小于PutOnce缓存(默认: 8MB),把数据一次读入buffer中;
调用access put rpc将数据put上去;
返回location;
putParts流程:
通过rpc 从access中alloc一个location和tokens
启动一个后台goroutine,将数据按
config.PartConcurrenc(默认:4)读取到buffer中;将buffer中的数据增加token,cid,vid等相关信息组装为一个parts;
通过
putPartsBatch将parts批量上传;
access
access put rpc的入口为
service.Put, 其处理流程如下:ParseArgs(args)解析参数;
args.IsValid()判断参数是否有效;
根据args中的hashes设置hasherMap;
调用
streamHandler.Put()通过hasherMap计算返回的hashSumMap;
stream_put Put()流程:
如果size>maxObjectSize(默认:256MB), 返回错误;
如果hasherMap个数>0; 复制一个reader用于计算hash;
调用SelectCodeMode(size),根据大小选择一个合适的纠删码策略;
根据access配置
MaxBlobSize,设置blobSize(默认: 4MB);调用
allocFromAllocatorWithHystrix(), 根据纠删码、size, blobSize,从allocator分配clusterID,blobs, blob个数由size, blobSize计算而来;根据要读取blob的大小和纠删码策略,在编码器encoder中
ec.NewBuffer()一块ec.Buffer;通过
ec.Split()将ec.Buffer中数据缓存切分为对应编码的shards;依次处理各个blob:
读取blob数据填充到ec.Buffer的dataBuf中;
调用对应编码器的
Encode()将shards进行编码;通过
writeToBlobnodesWithHystrix()将shards写入到blobnode中;如果有写入出错的个数>0, 则调用
RepairMsgBg(),往mqproxy发送repair消息sendRepairMsgBg;
上传过程如果不成功,通过
clearGarbage()清理无用垃圾数据;
ec.NewBuffer()建立编码缓冲区流程:根据dataSize和编码策略数据分片数shardN,计算每个分片的大小
shardSize=(dataSize+shardN-1)/shardN;根据分片大小shardSize和策略参数,计算编码总缓冲大小
ecSize=shardSize*(N+M+L);从内存池中申请ecSize大小的缓存buf;
根据参数设置buf中的不同部分;
返回设置好的Buffer;
writeToBlobnodes()数据写入到blobnode流程:- 根据clusterID、vid参数获取volume;
- 获取volume中的ec相关参数(包括:tactic,putQuorum等);
- 根据volume中的units, 开启goroutine,通过
h.blobnodeClient.PutShard()往blobnode节点同时发送写入shard请求; - 等待请求发送完后,如果写入成功的个数
writtenNum>=putQuorum成功写入标准(),则写入成功; - 否则, 判断当AZCount >=3时,如果一个AZ down掉,判断剩下的AZ是否每个shard都写入成功,如果是,则也可以判断写入成功;
- 否则写入不成功,返回错误;
blobnode
blobnode
ShardPut_():- ShardPut_接收
access节点发送的PutShard Rpc调用,执行shard put 写入shard数据操作;
- ShardPut_接收
datafile Write():
根据
Shard.Size大小, 计算(Alignphysize)写入到chunkfile中的编码后物理大小phySize(Shard 包含header,footer和block crc);根据phySize在datafile中分配待写入空间(allocSpace), 更新变量(cd.wOff)写入偏移(偏移需和4k对齐),并获取旧的(cd.wOff)作为
shard.Offset本次shard写入偏移;写入shard header数据到chunk file;
crc32block.NewEncoder新建一个crc编码写入器,通过编码器将数据编码,并写入到chunkfile的shard header数据区后面;写入shard footer数据到 chunk file;
读取(Get)

access-client
access-client 中get入口为
api/access/client.go (c *client)Get();先检查get参数有效性,如果size 为0,直接返回空;
然后随机顺序向多个access发送get rpc请求,返回第一个成功的请求;
access
access 由
access/stream_get.go (h *Handler)Get()负责get rpc 入口;先调用
genLocationBlobs根据参数location,offset,readSize获取location中需要读取的blobs;在根据location获取clusterMgr controller sc;
如果
len(blobs)== 1, 如果大小较小,直接调用getDataShardOnly()读取blob数据;开启一个后台协程,依次通过
readOneBlob从blobnode读取blobs中的每个blob的数据,通过chan传送个主流程主流程依次接收读取的数据,并写入到get结果的buffer中;
读取一个blob数据
access/readOneBlob():根据BlobSize和编码策略,分配一块新的EC buffer
GetBufferSizes();// 1. try to min-read shards byte
// 2. if failed try to read next shard to reconstruct
// 3. write the the right offset bytes to writer
blobnode
ShardGet_:
删除(Delete)
删除调用了punch hole来是否被删除的data;
通过compact异步对碎片化过多的chunkfile进行整理;
合并(Compact)
compact用于在后台整理chunkfile,由blobnode提供了rpc api;
chunkfile 是否需要compact(
NeedCompact):- chunk file size >=
conf.CompactTriggerThredshold(默认:1TiB),return true; - chunk file size >
conf.CompactMinSizeThreshold(默认: 16GB)且chunkfile 稀疏率>=80%(CompactEnptyRateThreshold参数);
- chunk file size >=
blobnode/core/chunk/chunk.doCompact():
IOType
| |
安全
- uptoken
| |