Prometheus基础
简介
Prometheus(普罗米修斯)受启发于Google的Brogmon监控系统,是继Kubernetes之后成为第二个正式加入CNCF基金会的项目。
2012年,由前Google工程师在Soundcloud以开源软件的形式进行研发;
2015年,对外发布早期版本;
2016年5月,加入CNCF基金会;
2016年6月,发布1.0版本;
2017年底,发布2.0版本,基于全新存储层,能更好地与容器平台、云平台配合。

特点
Prometheus作为新一代的云原生监控系统,基于中央化的规则计算、统一分析和告警的模型,特点如下:
- 易于部署:单一二进制文件,无第三方依赖,不会有潜在级联故障的风险,部署简单;
- 强大数据模型:监控指标以时序序列保存在存储中,并可灵活设置标签来对数据不同维度进行区分;
- 强大查询语言PromQL:内置的PromQL支持查询、聚合、过滤等复杂操作,可实现高效的查询;
- 易于扩展:支持分区和联邦集群部署,并可结合thano实现分布式部署;
- 易于集成:支持多种语言SDK,拥有大量第三方集成模块,可方便与第三方系统进行集成;
- 可视化:自带web ui, 与grafana很好的集成;
架构
Prometheus 的主要模块如下:
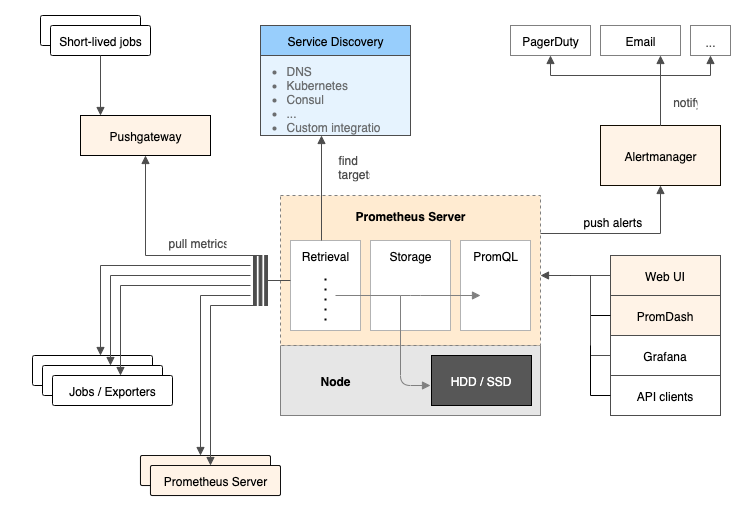
工作流程
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
数据模型
Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列,如:
| |
该时序的名字为 api_http_requests_total,标签为 path、status、method 和 instance,只有时序名字和标签键值完全相同的时序才是同一个时序。事实上,时序名字就是一个隐藏标签:
| |
指标类型
四种类型:
- Counter: 用于累计计数,例如用来记录请求次数。Counter的特点是一直增加不会减少。
- Gauge:用于记录常规数值,可以增加或减少。例如用来记录CPU、内存的变化
- Histogram:可理解为直方图,常用于跟踪事件发生的规模,如请求耗时、响应大小。可对记录的内容分组和聚合(count,sum等),例如响应时间小于500毫秒的多少次、500毫秒~1000毫秒之间多少次、1000毫秒以上的多少次
- Summary:与Histogram类似,但支持按百分比跟踪结果
存储模型
prometheus是一个时序型KV数据库,时序数据拥有垂直写,水平读的特点,在此基础上
第1代: Prototype:直接利用LevelDB进行kv存储;
第2代: Prometheus V1:chunk file,压缩存储;
第3代: Prometheus V2:合并的chunk+index 文件;
服务发现
Prometheus基于Pull模式, 无法主动发现新的监控节点,Prometheus引入**SD(Service Discovery)**服务发现机制来解决。
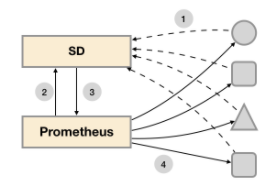
支持服务发现的组件类型:
Static
DNS
Consul
K8s
…
服务发现支持Relabeling机制,可对默认label进行map、replace、filter等操作。
扩展高可用
HA + LB
HA + remote storage
联邦(federate)集群
每一个Prometheus Server都包含一个/federate的接口,可用来获取当前节点中的监控数据。因此可通过该接口对整个prometheus集群进行拆分组合,建立分级节点,以做到集群的扩展,此模式称为联邦模式。
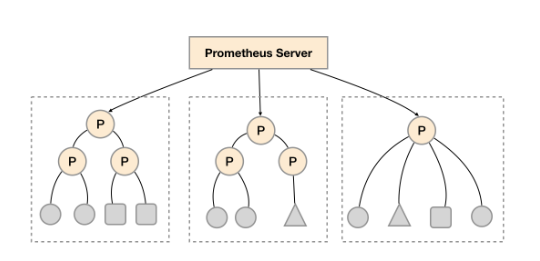
- Thanos(灭霸):是一个专门用于prometheus的高可用方案,可以一次查询多个 Prometheus 实例,并且能够对来自多个实例的相同指标进行去重
AlertManager
alertmanger是promtheus的独立组件,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
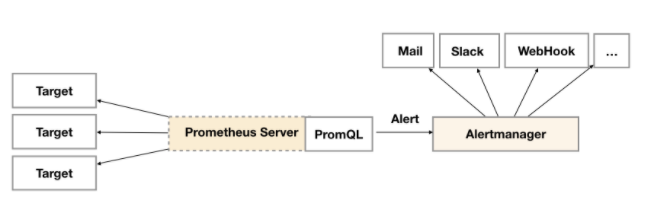
告警规则
告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
告警处理
