Loki简介
简介
整体架构
Loki的架构如下:
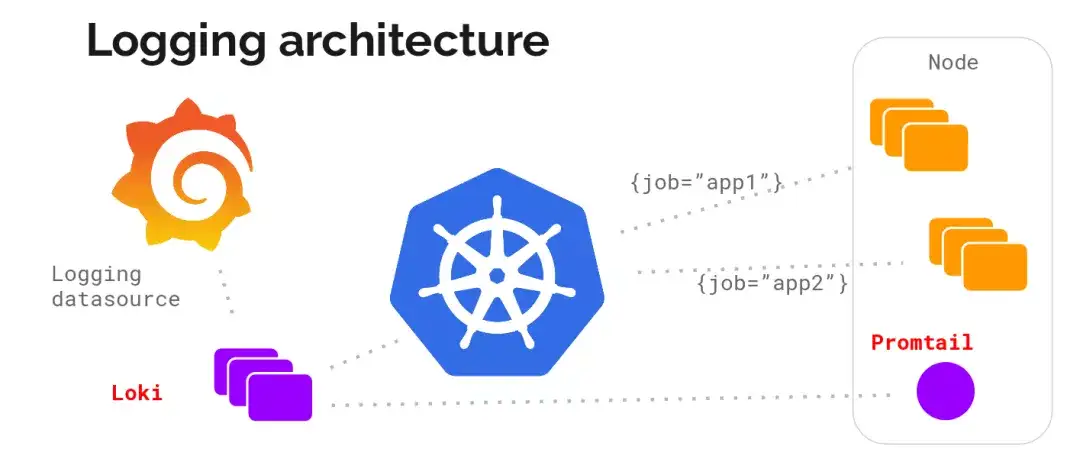
不难看出,Loki的架构非常简单,使用了和prometheus一样的标签来作为索引,也就是说,你通过这些标签既可以查询日志的内容也可以查询到监控的数据,不但减少了两种查询之间的切换成本,也极大地降低了日志索引的存储。
Loki将使用与prometheus相同的服务发现和标签重新标记库,编写了pormtail, 在k8s中promtail以daemonset方式运行在每个节点中,通过kubernetes api等到日志的正确元数据,并将它们发送到Loki。下面是日志的存储架构:
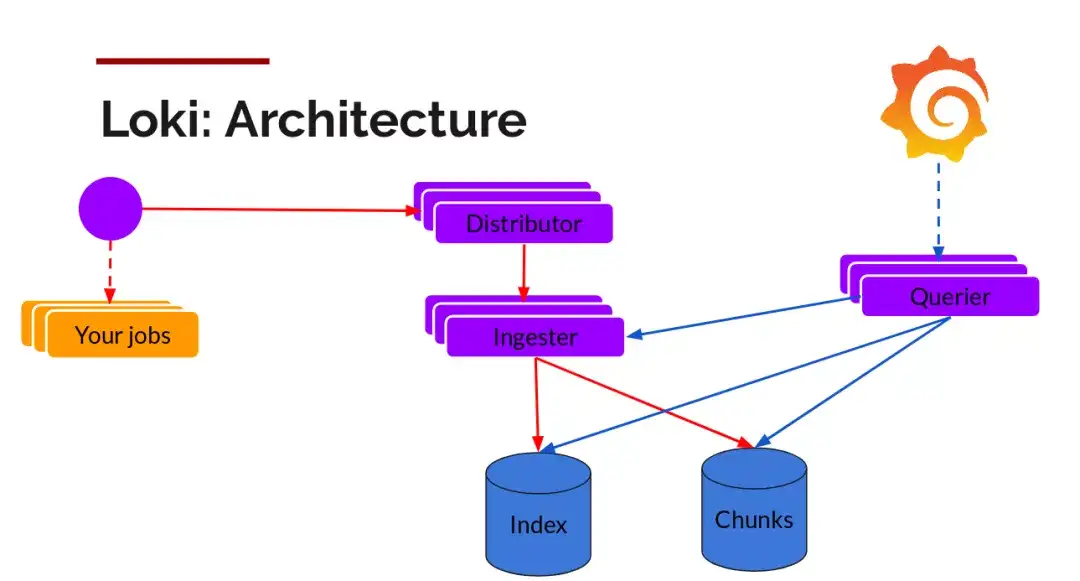
读写
日志数据的写主要依托的是Distributor和Ingester两个组件,整体的流程如下:

Distributor
一旦promtail收集日志并将其发送给loki,Distributor就是第一个接收日志的组件。由于日志的写入量可能很大,所以不能在它们传入时将它们写入数据库。这会毁掉数据库。我们需要批处理和压缩数据。
Loki通过构建压缩数据块来实现这一点,方法是在日志进入时对其进行gzip操作,组件ingester是一个有状态的组件,负责构建和刷新chunck,当chunk达到一定的数量或者时间后,刷新到存储中去。每个流的日志对应一个ingester,当日志到达Distributor后,根据元数据和hash算法计算出应该到哪个ingester上面。
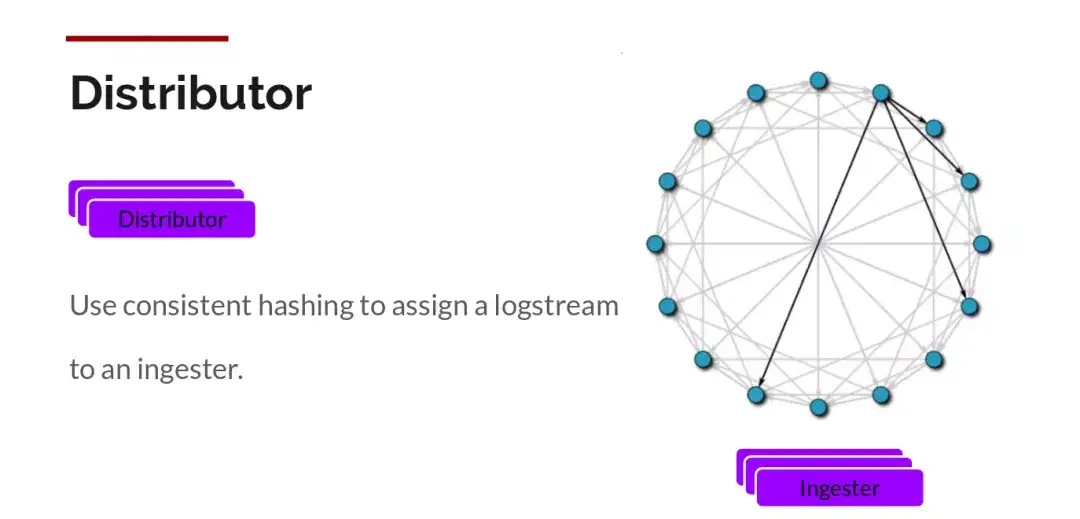
此外,为了冗余和弹性,我们将其复制n(默认情况下为3)次。
Ingester
ingester接收到日志并开始构建chunk:
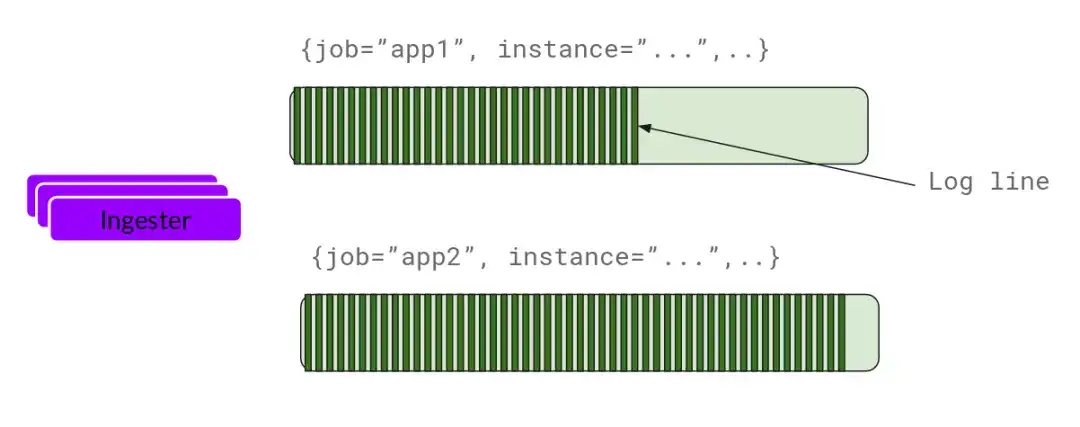
基本上就是将日志进行压缩并附加到chunk上面。一旦chunk“填满”(数据达到一定数量或者过了一定期限),ingester将其刷新到数据库。我们对块和索引使用单独的数据库,因为它们存储的数据类型不同。

刷新一个chunk之后,ingester然后创建一个新的空chunk并将新条目添加到该chunk中。
Querier
读取就非常简单了,由Querier负责给定一个时间范围和标签选择器,Querier查看索引以确定哪些块匹配,并通过greps将结果显示出来。它还从Ingester获取尚未刷新的最新数据。
对于每个查询,一个查询器将为您显示所有相关日志。实现了查询并行化,提供分布式grep,使即使是大型查询也是足够的。
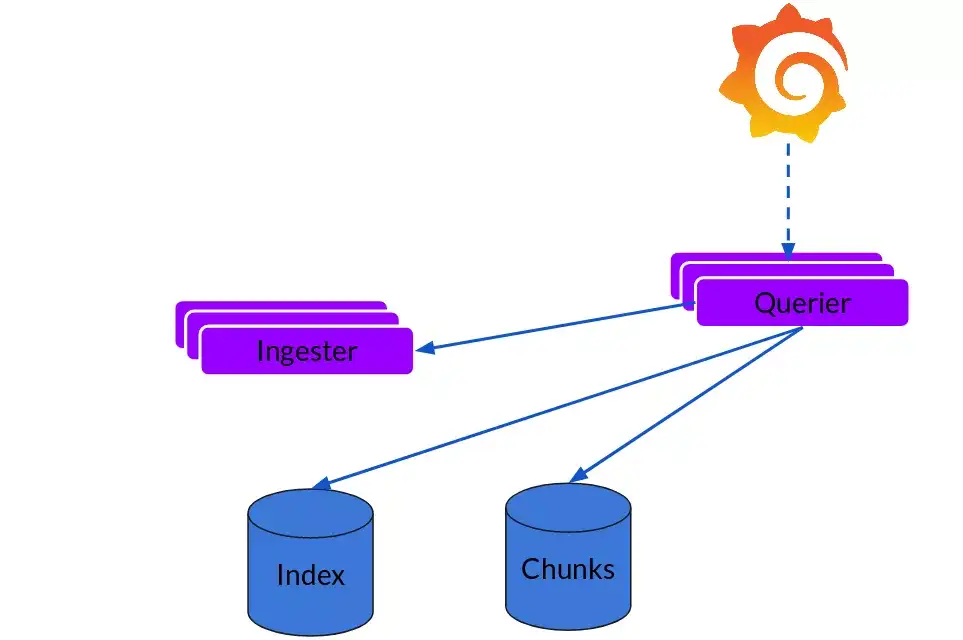
可扩展性
Loki的索引存储可以是cassandra/bigtable/dynamodb,而chuncks可以是各种对象存储,Querier和Distributor都是无状态的组件。对于ingester他虽然是有状态的但是,当新的节点加入或者减少,整节点间的chunk会重新分配,已适应新的散列环。而Loki底层存储的实现Cortex已经 在实际的生产中投入使用多年了。有了这句话,我可以放心的在环境中实验一把了。
LogQL:日志查询语言
基本的LogQL查询由两部分组成:log stream selector、filter expression
Log stream selector
它由一个或多个键值对组成,每个键是一个日志标签,值的话是标签的值,例如
| |
在这个例子中,记录具有的标签流app,其值是mysql 和的一个标签name,它的值mysql-backup将被包括在查询结果。注意,这将匹配其标签至少 包含mysql-backup其名称标签的任何日志流;如果有多个包含该标签的流,则所有匹配流的日志将显示在结果中。
支持以下标签匹配运算符:
- =:完全相等。
- !=:不相等。
- =~:正则表达式匹配。
- !~:正则表达式不匹配。
适用于Prometheus标签选择器的相同规则也适用 于Loki日志流选择器。
Filter expression
写入日志流选择器后,可以使用搜索表达式进一步过滤生成的日志集。搜索表达式可以只是文本或正则表达式:
- {job=“mysql”} |= “error”
- {name=“kafka”} |~ “tsdb-ops.*io:2003”
- {instance=~“kafka-[23]”,name=“kafka”} !=
kafka.server:type=ReplicaManager
运算符说明
- |=:日志行包含字符串。
- !=:日志行不包含字符串。
- |~:日志行匹配正则表达式。
- !~:日志行与正则表达式不匹配。
指标查询
范围向量
LogQL 与Prometheus 具有相同的范围向量概念,不同之处在于所选的样本范围包括每个日志条目的值1。可以在所选范围内应用聚合,以将其转换为实例向量。
注:对于此种查询,需要添加数据源,选择promethes,但是地址为loki的地址,并在最后添加/loki即可
当前支持的操作功能为:
- rate:计算每秒的条目数
- count_over_time:计算给定范围内每个日志流的条目。
//对fluent-bit作业在最近五分钟内的所有日志行进行计数。
| |
获取fluent-bit作业在过去十秒内所有非超时错误的每秒速率。
| |
集合运算符
与PromQL一样,LogQL支持内置聚合运算符的一个子集,可用于聚合单个向量的元素,从而产生具有更少元素但具有集合值的新向量:
- sum:计算标签上的总和
- min:选择最少的标签
- max:选择标签上方的最大值
- avg:计算标签上的平均值
- stddev:计算标签上的总体标准差
- stdvar:计算标签上的总体标准方差
- count:计算向量中元素的数量
- bottomk:通过样本值选择最小的k个元素
- topk:通过样本值选择最大的k个元素
可以通过包含a without或 by子句,使用聚合运算符聚合所有标签值或一组不同的标签值:
| |
举例:
统计最高日志吞吐量按container排序前十的应用程序
| |
获取最近五分钟内的日志计数,按级别分组
| |