一致性Hash算法
一致性哈希算法在 1997 年由麻省理工学院的 Karger 等人在解决分布式 Cache 中提出;
设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和 CARP 十分类似;
一致性哈希修正了 CARP 使用的简单哈希算法带来的问题,使得 DHT 可以在 P2P 环境中真正得到应用;
Hash 算法的指标
- 平衡性(Balance):哈希的结果能够尽可能均匀的分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用
- 单调性(Monotonicity):是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区
- 分散性(Spread):
- 负载(Load):
- 平滑性(Smoothness):
一致性 Hash 算法原理
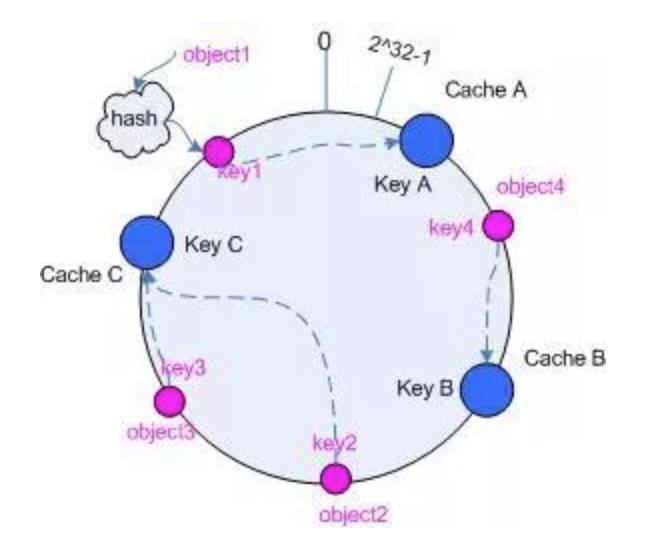
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数 H 的值空间为 0-2^32-1(即哈希值是一个 32 位无符号整形),整个哈希空间环如下:
Jump 一致性哈希算法
jump consistent hash 是一种一致性哈希算法, 此算法零内存消耗,均匀分配,快速,并且只有 5 行代码。
| |
Kademlia 算法
Kademlia 算法在 2002 年由 Petar Maymounkov 和 David Mazières 所设计,以异或距离来对哈希表进行分层是其特点。Kademlia 后来被 eMule、BitTorrent 等 P2P 软件采用作为底层算法。
- 对于任意一个有[ 2(n−1) ,2𝑛)个节点的网络,最多只需要 n 步搜索即可找到目标节点;
- K-bucket 的更新机制一定程度上保持了网络的活性和安全性。