Raft算法
简介
Raft算法是2013年由斯坦福大学的Diego Ongaro、John Ousterhout 共同提出的一种共识算法1;与
Paxos相比,Raft 易理解、易实现;Raft 和 Paxos 一样, 只要保证超过半数的节点正常就能够提供服务;
Raft是基于状态机+日志复制的一致性模型;
原理
raft算法模型分为3个部分:
领导人选举:从若干奇数N(N>=3)个节点组成的复制组中,选举出一个在一段时间内称为
Leader的节点,在这段时间内,由该Leader节点负责外部请求日志的复制;日志复制:在成功选举出
Leader后,由Leader驱动,接收外部请求,并通过状态机+日志复制的方式执行请求;安全性要求:在选举和日志复制两个阶段中,为保证一致性而设置的算法规则,以及在集群配置改变时的操作;
关键概念
- Log(日志):记录raft一系列操作的有序序列;
- Election(选举):Raft 的选举由定时器来触发,每个节点的选举定时器时间都是不一样的,开始时状态都为 Follower 某个节点定时器触发选举后 Term 递增,状态由 Follower 转为 Candidate,向其他节点发起 RequestVote RPC 请求
- Term(任期):在 Raft 中使用了一个可以理解为周期(第几届、任期)的概念,用 Term 作为一个周期,每个 Term 都是一个连续递增的编号,每一轮选举都是一个 Term 周期,在一个 Term 中只能产生一个 Leader
- Index(日志序号):
基本流程
Raft将整个时间划分为一个个的小周期, 称为任期(
Term);每个任期又分为
选举和选举后日志复制两个阶段;选举阶段为每个周期开始的阶段,目的是通过投票选出一个Leader;一个Term任期内只能有一个合法的
Leader;选举阶段,整个Raft集群不处理外界客户端的请求;
成功选举出
Leader后,进入日志复制阶段;日志复制阶段,只有Leader节点能正常接收并处理客户端请求。其他节点如果接收客户端请求,只能转发给Leader,由Leader进行处理;Leader接收到客户端请求后,先将请求追加到本地日志中,然后将请求发送给各个Follower节点;Follower接收到请求后,将请求写入本地日志,并给Leader发送响应;Leader收到多数Follower写入成功响应后,给客户端发送响应,告知状态机执行后结果;
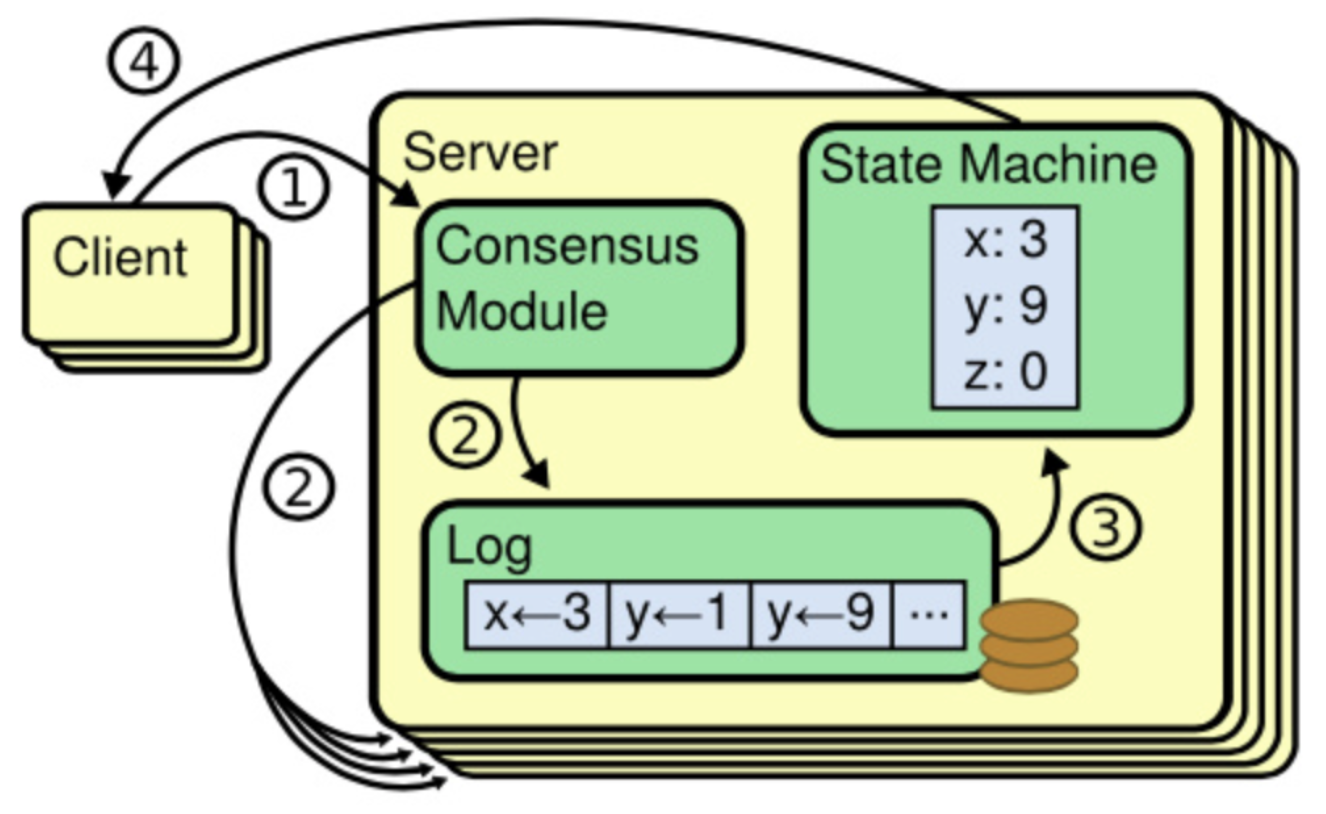
角色
基础Raft集群的节点分为以下三种角色:
- Candidate(候选者):负责发起选举,发起投票及接收投票。Raft 刚启动时由一个节点从 Follower 转为 Candidate 发起选举,选举出 Leader 后从 Candidate 转为 Leader 状态;
- Leader(领导者):负责日志的同步管理,处理来自客户端的请求,与 Follower 保持这 heartBeat 的联系;
- Follower(跟随者):负责响应来自 Leader 或者 Candidate 的请求;
改进Raft集群另外提供如下几种角色:
- Learner(学习者):只读节点,不参与选举投票及日志复制过程,只被动复制 follower 日志;
- PreCandidate(预选者):
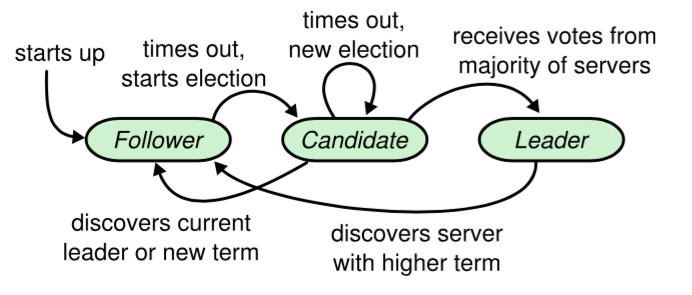
角色转换
- raft各节点的角色通过状态机进行转换;
- 节点启动时,初始角色为
Follower; - 节点转换为
Follower后,将等待Leader发送的心跳消息; Follower在心跳超时时间超时后,将转入选举流程,转换为Candidate;Candidate在选举超时时间内收到大多数节点的选票则转换为Leader, 如果超过选举超时时间仍未获得大多节点的投票,则继续保持Candidator状态,并发起新一轮选举投票;Candidate发现合法的Leader或者收到更高term的请求,则转换为Follower;Leader在收到更高term的请求后转换为Follower;
| |
计时器
raft算法中有以下计时器:
心跳间隔时间(heartbeat_interval):
Leader节点周期性的以heartbeat_interval时间间隔向其他节点发送心跳消息,以维护自己在当前任期内的领导权。默认值: 100ms ~ 200ms;心跳超时时间(heartbeat_timeout):
Follower节点维护的心跳超时时间计数,如果在该超时时间内接收到合法Leader的心跳消息,则计数器重置;否则,此时该节点将转入选举流程。默认值:10 * heartbeat_interval;选举间隔时间(election_interval):
Follower节点在进入选举流程(或Candidate重新发起新一轮选举流程)后,要先休眠一个随机时间后,才正式发起选举,该时间即为选举间隔时间。该间隔时间主要用于避免各节点同时发起选举操作而引起的冲突。默认值:rand(10 * heartbeat_interval, 20 * heartbeat_interval ); 选举间隔时间必须要> 5 倍心跳间隔时间,建议是 10 倍关系;选举超时时间(election_timeout):
Candidate节点在进行选举后,向各个节点发送拉票请求后,会等待一个选举超时时间election_timeout,如果在该超时时间内,获取多数投票,则本次选举成功;否则,超过该时间,还未获得多数选票,则该Candidate节点将重新发起下一轮选举。 默认值:10 * heartbeat_interval;
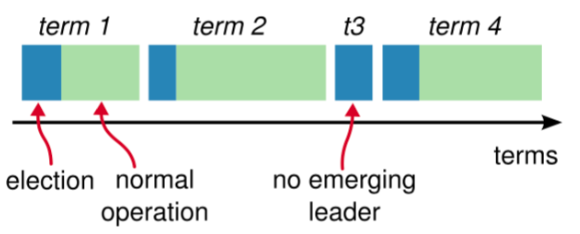
任期
raft将整个工作流程划分为一个一个的任期
term,用一个递增的整数表示;每个term分为
选举和日志复制两个阶段;选举阶段:发生在每一个term的开始部分, 其通过选举算法选出该term中的唯一节点作为Leader, 其他节点将变为Follower(或Learner);日志复制阶段:每个term的选举完成后,进入日志复制阶段。
日志
raft的日志用于记录顺序的指令序列。

firstLogIndex:标识当前日志序列的起始位置,如果日志不做压缩处理,也就是没有快照模块的话,那么 firstLogIndex 就是零值。
lastLogIndex:
commitIndex:表示当前已经提交的日志,也就是成功同步到 majority 的日志位置的最大值
applyIndex:是已经 apply 到状态机的日志索引,它的值必须小于等于 commitIndex,因为只有已经提交的日志才可以 apply 到状态机
日志存储
为了保证日志的快速和可靠这两个,raft日志存储分为内存和物理存储2个部分。
日志压缩
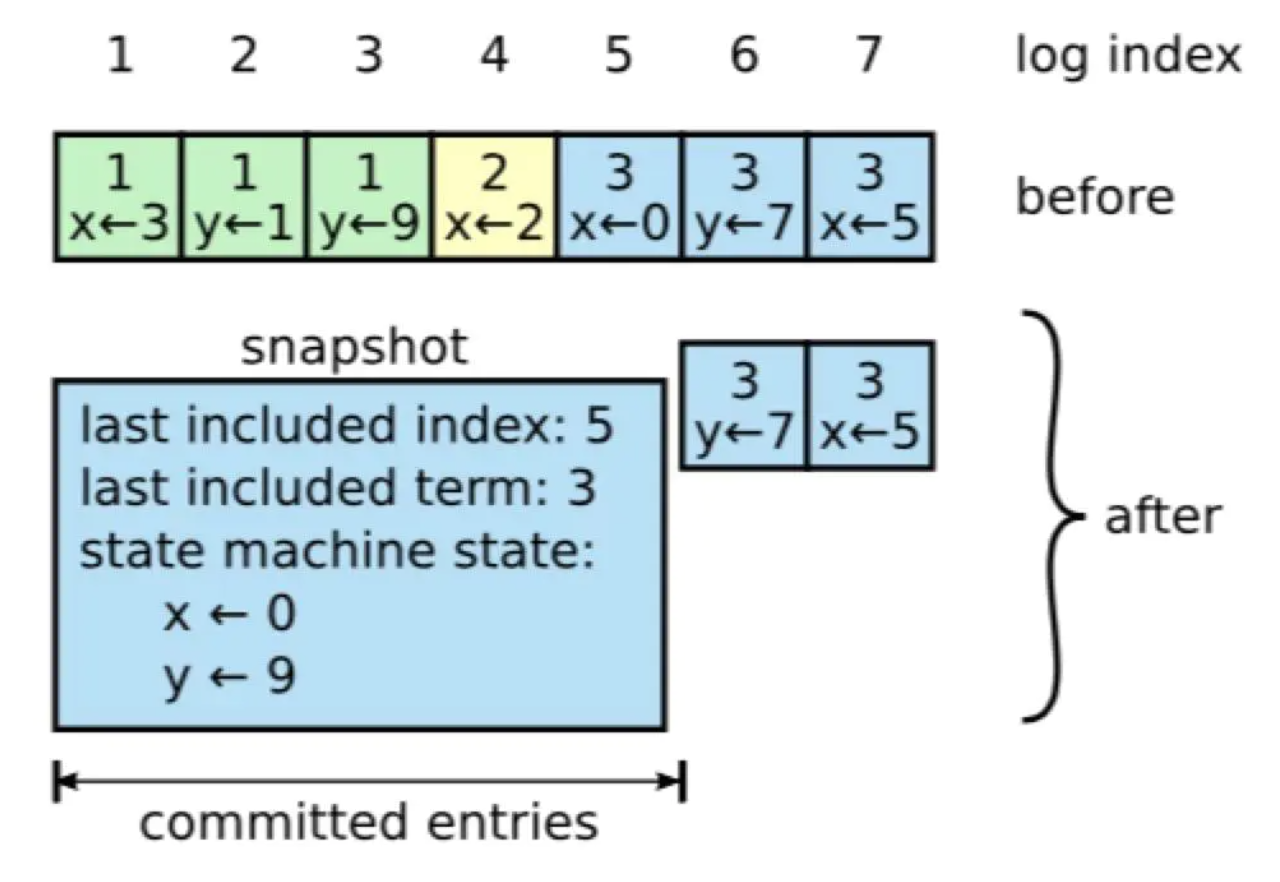
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响可用性。
Raft 采用对整个系统进行 snapshot 来解决,snapshot 之前的日志都可以丢弃。
每个副本独立的对自己的系统状态进行 snapshot,并且只能对已经提交的日志记录进行 snapshot。
当 Leader 要发给某个日志落后太多的 Follower 的 log entry 被丢弃,Leader 会将 snapshot 发给 Follower。或者当新加进一台机器时,也会发送 snapshot 给它。发送 snapshot 使用 InstalledSnapshot RPC。
指令状态机(StateMachine)
raft节点将收到的指令按序记录到日志后,通过一致性复制协议保证了各节点日志序列(committed前)的一致性;
在各节点初始状态一致的情况下,,raft通过日志执行状态机来依次执行日志中的指令,就能保证各个节点raft驱动的业务系统最终状态的一致性;
raft通过复制状态机来操作日志,保证日志按序应用(Apply)到实际的系统中;
执行状态机定义了raft和业务系统执行日志的操作接口;
算法流程
Raft 算法流程分为以下几个步骤:
启动:系统启动阶段;
选举:通过投票,产生leader的阶段;
日志复制:当选举成功产生 Leader 后,系统进入日志复制阶段,Leader 持续将收到的客户端日志按顺序复制到 Follower:
变更:

启动
初始启动时,所有节点(Node)均为
Follower状态,任期term置为 1;如果
Follower节点在选举超时时间内未收到其他节点的 append/hearbeat/snapshot 消息,则状态变为Candidate,进入选举状态;重启时,需load 以下状态:
term;
选举
- raft的选举发生在每一个term的前个阶段;
- 选举的目的是为了选出本term内的唯一
leader节点;
选举发生
- 只有
Follower节点才能发起选举操作; Follower节点超过心跳超时间隔时间后,未收到Leader节点的消息,则启动选举流程;
选举流程
- 选举由
Follower节点发起选举; Follower发起选举后,先执行如下操作:- 先将本节点当前的
term+1; - 角色变为
Candidate; - 给自己投一票(投票计数设为1);
- 先将本节点当前的
- 再等待一个随机的时间(选举间隔时间election_interval);
- 然后并发地向其他节点发送投票请求消息
RequestVote RPC,其中投票请求消息中包含:- leader_id:本节点id,用于指明其他节点选择自己作为下一任期的
Leader; - term: 当选的下一任任期;
- lastest_committed_log_id:本节点最新已提交的日志id;
- leader_id:本节点id,用于指明其他节点选择自己作为下一任期的
- 设置选举超时时间(election_timeout),等待其他节点的投票回复,并计算获取的赞成票数;
- 如果在选举超时时间以内,收到一半以上节点的投票,则
投票规则
Follower节点可以投票;- 每个节点在任期内,只能投一票;
- 候选人知道的信息不能比自己的少;
- first-come-first-served 先来先得;
选举结束
Candidate节点:如果在选举超时时间内,收到超过一半(majority)节点(包括自己投自己的1票)的投票,则赢得选举,当选为
Leader;否则,超过了选举超时时间外,还未收到超过一半的赞成票,则此轮选举未当选,继续开始下一轮竞选;
Follower节点:
选举阶段主要在Candidate和Follower节点之间进行:
Follower节点的心跳计时器如果超时,将转入Candidate状态;Candidate节点先给自己投一票,然后给其他节点发送拉票请求SolictVoteReq,该请求包含本节点最后一条log的(term,index);Leader,Candidate节点将忽略的拉票请求;Follower节点收到SolictVoteReq(拉票请求)后,按如下规则处理:- 已投过票(voteFor!=0),忽略该Req(一个任期内(term), 每个follower至多投一票);
- 比较
SolictVoteReq拉票请求中的term或index和本节点最后一条日志的term和index; - 如果
req.term<self.log.last_term|| ( req.term==self.log.last_term&&req.index<self.log.last_index),忽略请求(candidate的日志比当前节点的日志要旧); - 否则, 该节点发送
GrantVoteAck(投票消息)给拉票节点,并记录投票信息到voteFor; - 上述规则保证了新当选的leader一定拥有所有committed的log;
Candidate节点收到GrantVoteAck(投票响应)后:- 计算获得票数,如果票数达到多数赞成票(>一半投票者),则自身当选为
Leader,转为领导人状态, 同时向其他节点发送心跳消息, 并将缓存的客户端请求立即执行; - 如果收到其他节点的 Leader 心跳包,且该心跳包的任期要>=自身节点,则表明该其他节点已成功当选为 leader,自身节点将转为
Follower状态; - 否则,选举计数器超时,表明该选举周期内没有任何节点当选,接下来将
term加 1 后,重新进行选举;
- 计算获得票数,如果票数达到多数赞成票(>一半投票者),则自身当选为
心跳(heartbeat)
当选举成功后,raft集群通过心跳维护一个任期;
心跳由Leader发起,给所有
Follower定期发送心跳消息;心跳消息中包含了
Leader最新已提交日志条目的(index, term);Follower如果在心跳超时时间内接收到心跳消息,则根据规则对消息进行响应;如果
日志复制
每个term在选举成功后,进入日志复制阶段。日志复制阶段整个系统可以接收外部指令,并通过状态机进行执行,同时保证系统的一致性。日志复制分为写流程和读流程两个。
写流程
写日志的流程如下:
- 日志复制阶段存在一个
Leader节点,其他都是Follower(或Learner)节点; - 只有
Leader节点可以处理外部指令,其他节点接收到外部指令后,先将指令转发给Leader,通过Leader节点执行; Leader接收到指令后,将消息增加上(index, term)作为Entry,追加到Logs中;Leader通过AppendEntriesRPC调用将日志Commit到所有Follower,日志复制的范围是;Follower收到AppendEntriesRPC,记录Log并返回ACK给Leader;Leader收到大多数Follower节点的Ack后,通过指令状态机apply消息,并将结果返回给 client;Follower上的所有已提交log被异步有序的apply到指令状态机中;
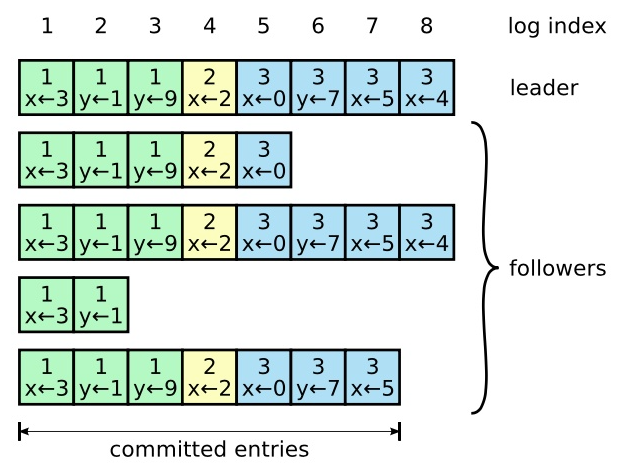
读流程
Log提交
Raft 不会通过计算副本数目的方式去提交一个之前任期内的日志条目;
只有leader当前任期里的日志条目通过计算副本数目可以被提交;
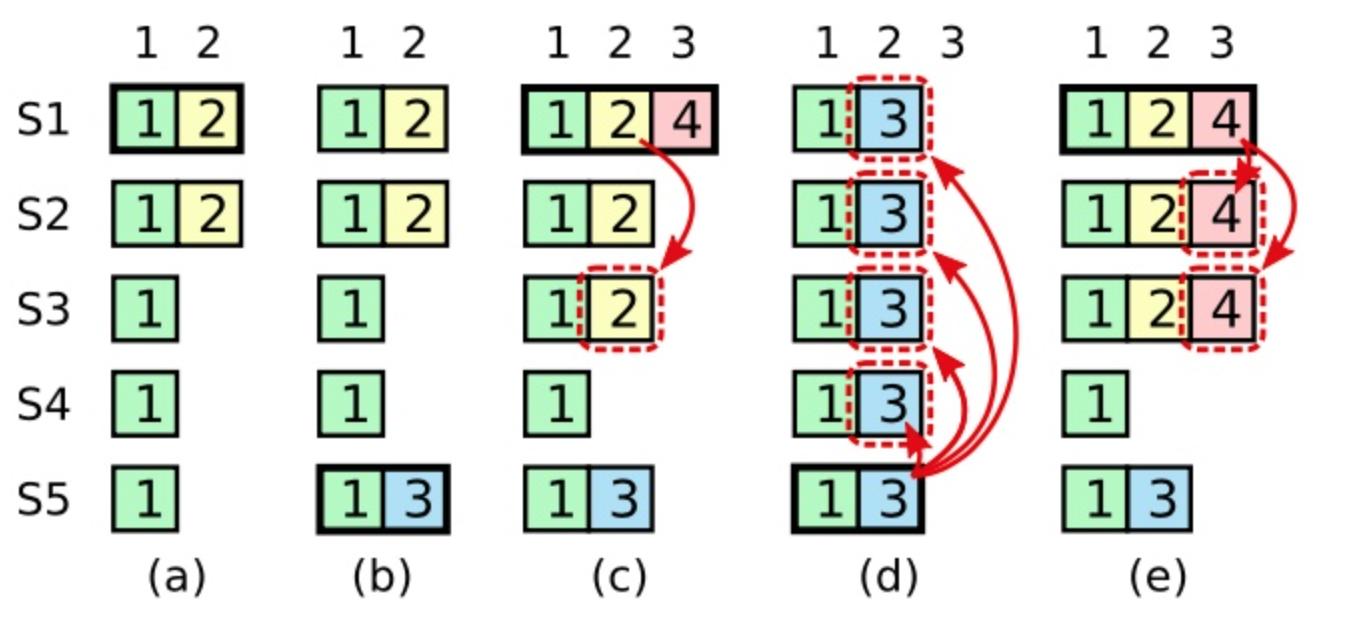
为什么领导人无法决定对老任期号的日志条目进行提交?
(a) , S1 是Leader,部分Follower(S2)复制了索引位置 2 的日志条目;
(b) , S1 崩溃了, S5在Term 3 赢得选举(S5, S3, S4赞成),然后从Client收了一条日志条目放在了索引 2 处;
(c),S5 崩溃了, S1 重新启动,选举(Term4)成功(S1,S2,S3,S4赞成),后开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。
(d), S1 又崩溃了,S5 可以重新被选举(Term5)成功(S2,S3 和 S4 赞成),然后覆盖了他们在索引 2 处的日志。
反之,如果S1在崩溃之前,把自己主导的新任期里产生的日志条目复制到了大多数机器上,
(e) ,那么在后面任期里面这些新的日志条目就会被提交(因为 S5 就不可能选举成功)。 这样在同一时刻就同时保证了,之前的所有老的日志条目就会被提交。
复制状态机的执行
Leader节点收到外部指令封装为entry(包括Follower接收并转发的外部指令)后:将消息append到日志末尾中;
并行将entry封装为
Commit消息,发送到所有Follower节点;等待节点的回复;
Follower节点接收到Commit消息后,检查消息的合法性(term, index),将有效消息中的entryappend到本节点日志末尾,并回复Leader;Leader收到多数节点成功ack后,提交消息(commitIndex),并向本节点的指令状态机发送Apply指令,让指令状态机执行消息,执行成功后,向客户端返回;follower节点收到hb消息后, 会对比hb中的commitIndex和本节点的oldCommitIndex, 然后将所有在该范围内的[oldCommittedIndex+1, committedIndex]日志都apply到本节点的指令状态机中;
配置改变
配置变更包括节点数量的改变,配置参数的变更等。
最简单的方式是:停止集群、改变成员、启动集群。这种方式在执行时会导致集群整体不可用;
Raft集群成员配置作为一个特殊日志从 leader 节点同步到其它节点去;
Raft 使用一种两阶段方法平滑切换集群成员配置来避免遇到前一节描述的问题,具体流程如下:
安全性
Raft 增加了如下两条限制以保证安全性:
拥有最新的已提交的 log entry 的 Follower 才有资格成为 Leader。
Leader 只能推进 commit index 来提交当前 term 的已经复制到大多数服务器上的日志,旧 term 日志的提交要等到提交当前 term 的日志来间接提交(log index 小于 commit index 的日志被间接提交)。
成员变更
- 成员变更是在集群运行过程中副本发生变化,如增加/减少副本数、节点替换等。
因为各个服务器提交成员变更日志的时刻可能不同,造成各个服务器从旧成员配置(Cold)切换到新成员配置(Cnew)的时刻不同。成员变更不能影响服务的可用性,但是成员变更过程的某一时刻,可能出现在 Cold 和 Cnew 中同时存在两个不相交的多数派,进而可能选出两个 Leader,形成不同的决议,破坏安全性。
为了解决这一问题,Raft 提出了两阶段的成员变更方法。
集群先从旧成员配置 Cold 切换到一个过渡成员配置,称为共同一致(joint consensus),共同一致是旧成员配置 Cold 和新成员配置 Cnew 的组合 Cold U Cnew,一旦共同一致 Cold U Cnew 被提交,系统再切换到新成员配置 Cnew。
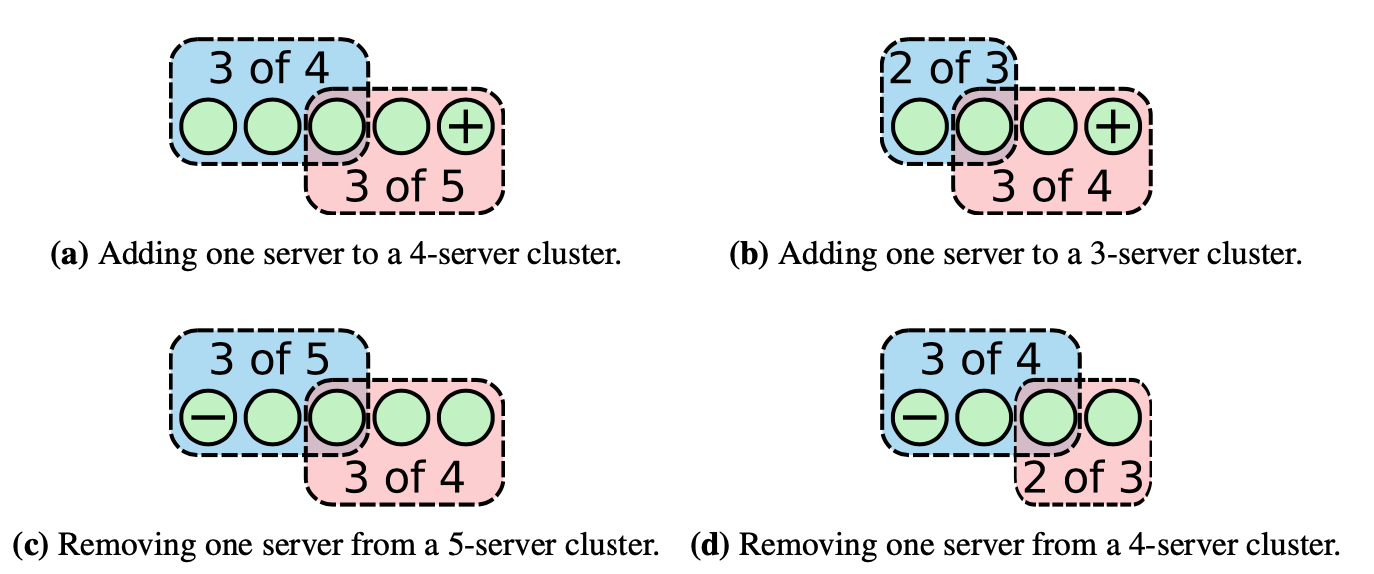
如果一次只增加或减少一个节点,那么并不会出现上面说的两个多数派的问题
当主节点收到对当前集群(C_old)新增/移除节点的请求时,它会将新的集群配置(C_new)作为一条新的日志加入到队列中,并用上文提到的机制复制到其它各个节点。
当一个节点收到新的日志时,日志中的 C_new 会立即生效,即该节点的日志会被复制到 C_new 中配置的其它节点,且日志是否被提交也以 C_new 中指定的节点作为依据。
这意味着节点不需要等 C_new 日志被提交后才开始启用 C_new,且每个节点总是使用它的日志中最新的配置。
当主节点提交 C_new 日志后,新增/移除节点的操作就算结束。此时,主节点能确定至少 C_new 中的多数节点已经启用了 C_new 配置,同时,那些还没有启用 C_new 的节点也不再可能组成新的“多数节点”。
实现要点
Batch and Pipeline
并行 Append Log
异步 Apply log
Snapshot
异步 Lease Read
ReadIndex
预投票(PreVote)
问题:当一个 Follower 节点(A)与其他节点网络隔离时,由于心跳超时,将会变成候选人并发起选举,这时会递增 Term。由于网络隔离,其选举将无法成功,于是会持续选举,导致 Term 不断增大。当网络恢复后,该 A 节点会把其 Term 发送给其他节点,由于该 Term 很大概率大于其他节点 Term,从而引发其他节点进入选举流程。但此时,由于 A 节点的被隔离很久,日志不可能为最新的,所以其不会成为 Leader,导致集群一直在选举。Raft 论文中提出了PreVote算法来解决该问题。
主要思想:
在发起正式投票前,先进行预投票(pre-vote),预投票时自身 term 不变,但投票 tern+1。
确认自己能获得集群大多数节点的投票时,才将自己的 term+1,然后正式进行投票。
由此就可以避免在网络分区的时孤立节点的 term 持续增大,导致后续选举的反复。
预投票是一个典型的 2PC 事务,
为此,需要增加一个新的 PreCandidate 状态。
Write
Read
为保证 Read 操作的一致性,最简单的方法是将 Read 也走一遍 raft log(Log Read),这样性能将很差。
因为 leader 节点能保证已经 committed 的 log 是最新的 log,所以可以直接从 leader 读取,为此需保证 leader 的有效性,有两种方式:
ReadIndex
- Leader 将当前自己的 commit index 记录到一个 local 变量 ReadIndex 里面。
- 向其他节点发起一次 heartbeat,如果大多数节点返回了对应的 heartbeat response,那么 leader 就能够确定现在自己仍然是 leader。
- Leader 等待自己的状态机执行,直到 apply index 超过了 ReadIndex,这样就能够安全的提供 linearizable read 了。
- Leader 执行 read 请求,将结果返回给 client。
注意:
leader 刚通过选举成为 leader 的时候, commit index 并不能够保证是当前整个系统最新的 commit index,此时首先提交一个 no-op 的 entry,保证 leader 的 commit index 成为最新的。
https://jin-yang.github.io/post/golang-raft-etcd-sourcode-consistent-reading.html
Lease Read
虽然 ReadIndex 比原来的 Raft log read 快了很多,但毕竟还是有 Heartbeat 的开销,在 Raft 论文里面,提到了一种通过 clock + heartbeat 的 lease read 优化方法。
也就是 leader 发送 heartbeat 的时候,会首先记录一个时间点 start,当系统大部分节点都回复了 heartbeat response,那么我们就可以认为 leader 的 lease 有效期可以到 start + election timeout / clock drift bound 这个时间点。
为什么能够这么认为呢?主要是在于 Raft 的选举机制,因为 follower 会在至少 election timeout 的时间之后,才会重新发生选举,所以下一个 leader 选出来的时间一定可以保证大于 start + election timeout / clock drift bound。
虽然采用 lease 的做法很高效,但仍然会面临风险问题,也就是我们有了一个预设的前提,各个服务器的 CPU clock 的时间是准的,即使有误差,也会在一个非常小的 bound 范围里面,如果各个服务器之间 clock 走的频率不一样,有些太快,有些太慢,这套 lease 机制就可能出问题。
Follower Read
先去 Leader 查询最新的 committed index;
然后拿着 committed Index 去 Follower read,从而保证能从 Follower 中读到最新的数据;
当前 etcd 就实现了 Follower read
幽灵复现
参考
- https://www.usenix.org/conference/atc14/technical-sessions/presentation/ongaro
- 寻找一种易于理解的一致性算法(扩展版)
- 分布式一致性与共识的前世今生
- Raft 共识算法深度解析
- 线性一致性和 Raft
- Raft 的 PreVote 实现机制
- Etcd 之 Lease read
- Raft 协议精解
- TiKV 源码解析系列 - Lease Read
- Raft TLA+形式化验证
- 分布式系统一致性协议 Raft 理解 - Jefferywang 的烂笔头
- 「图解 Raft」让一致性算法变得更简单 - ZingLix Blog
- 条分缕析 Raft 算法
- Raft 为什么是更易理解的分布式一致性算法 - mindwind - 博客园
- 全面理解Raft协议
- Raft 协议实战系列(五)—— 集群成员变更与日志压缩
- 浅谈分布式存储之raft
- https://segmentfault.com/a/1190000022248118
- https://www.sofastack.tech/projects/sofa-jraft/raft-introduction/
- https://pingcap.com/zh/blog/building-distributed-db-with-raft
- 深入浅出etcd/raft