Spark 文件 IO 分析
1. Spark 简介
Spark 是一种是基于内存计算的大数据并行计算框架,主要分为 Driver、Worker 两个组件,可通过 yarn,mesos、k8s 进行调度。其主要架构如下:

其中:
DriverNode:复制任务的提交及任务上下文相关的处理;
WorkerNode:复制任务的执行,每个 workerNode 可并行执行多个 executor,每个 executor
2. Spark 计算模型
Spark 将数据抽象为RDD(弹性数据集),并根据数据的依赖关系将RDD计算过程划分为一个个stage,RDD随着计算在各个stage中随着计算,在计算过程中需要处理大量数据,其涉及的 IO 主要包括以下几个:
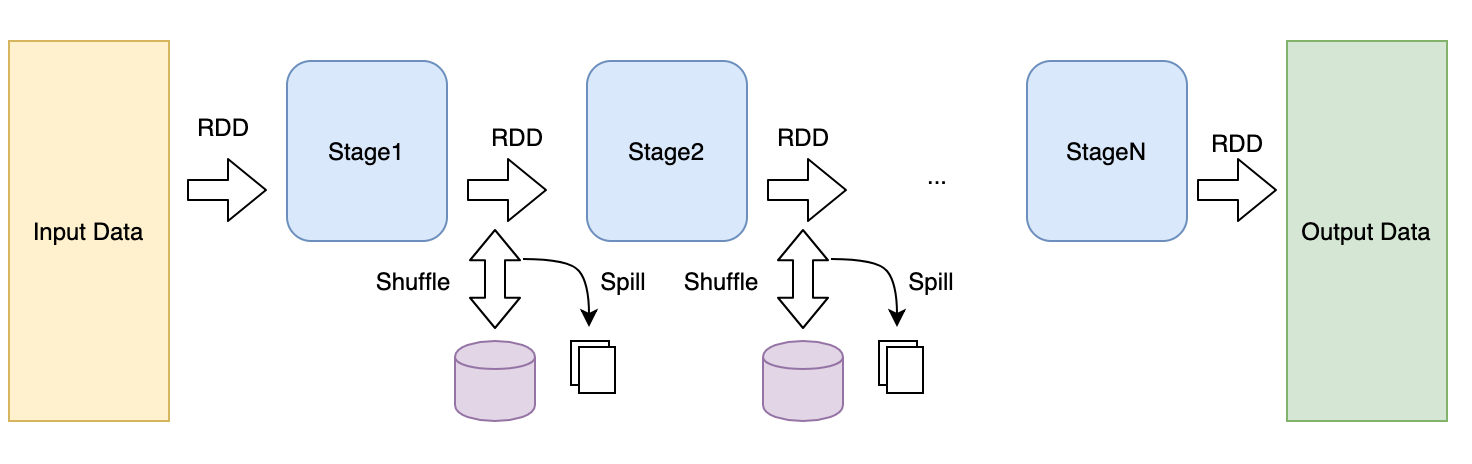
输入:任务开始从外部数据源读取以构建输入 RDD,支持多种实现接口:hdfs, file, s3 等;
输出:计算任务结束后的数据输出,写入到外部存储;
Shuffle:两个 stage 之间的数据操作,包括可分为 shuffle write,shuffle read 两个阶段;
Spill:Shuffle 过程中有些操作需要大量的内存,为避免 jvm 的 oom,需要将缓存数据临时存入磁盘中,这个过程称为 spill;
3. Spark Shuffle
Spark 2 个 Stage间需要对所有中间数据进行重排,这个过程称为Shuffle。Shuffle 过程需要操作大量的数据,无法全部在内存中完成,因此数据需要进行存储到磁盘中。Shuffle过程分为Shuffle Write 和 Shuffle Read两个阶段。
Shuffle Write将上一个 stage 的 输出数据写入磁盘中,并且把数据位置元信息上报到 driver 的中, Shuffle Read在下一个 stage 开始,根据数据位置元信息,拉取对应的数据作为该stage的输入。
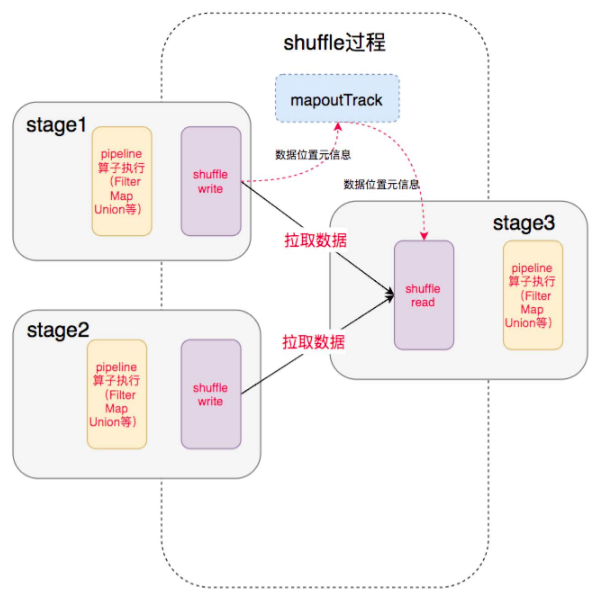
Shuffle Write
shuffle write 由上一个 stage 的 ShuffleMapTask 执行,基本过程是将上一个 stage 的数据重新按下一个 stage 的 Reduce 任务重新分区,便于下一个 stage 处理。
spark 中 shuffle write 有 3 种具体的实现,基本流程如下:
shuffleMapTask 将数据(records)写入根据 key 做到内存缓冲区中(每个 partition 对应一个 bucket 缓存区),如果开启了 spill,则检查是否需要 spill。
若需要 spill,将集合中的数据根据 partitionId 和 key(若需要)分区和顺序溢写到一个临时的磁盘文件,并释放内存新建一个 map 放数据,每次溢写都是写一个新的临时文件。
写完后,需要将所有的临时文件进行合并(merge),此时需要将所有的临时文件读取出来,并合并写入最终磁盘文件中,并根据索引文件记录分区映射关系;
最后 executor 将文件地址封装到 MapStatus,通过 MapOutputTrackerWorker 发送给 Driver 的 MapOutputTrackerMaste;
在 SortShuffleWriter 中,文件合并前,需要先使用 externalsort 对数据进行排序,此时可能会触发 spill 生成很多的临时小文件。
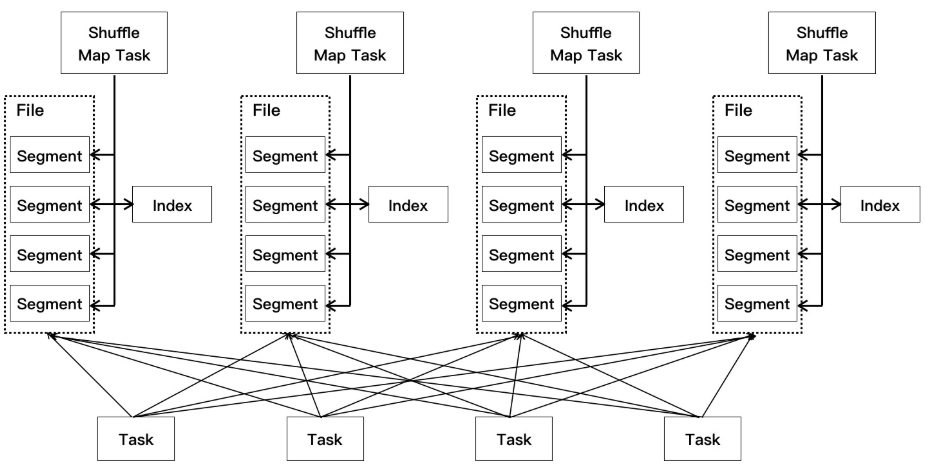
shuffle write 默认有三种实现:
BypassMergeSortShuffleWriter:通过hash将map先按partition输出到不同的临时文件中,最后按分区合并到一个data文件中,并生成一个index文件记录每个分区在data文件中的位置;
SortShuffleWriter:先在内存中对数据进行排序(堆排,中间可能spill许多临时文件),;
UnsafeShuffleWriter:SortShuffleWriter 的改进,使用序列化后的数组进行排序
Shuffle Read
shuffle read 是在下一个 stage 的开始之前的 ResultTask 中执行,主要作用是获取前一个 stage 各个节点的对应分区的数据数据,以供 reduce 处理。

Shuffle Read 主要分为 fetch 和 aggreation 两个步骤:
- fetch
shuffle read 开始后,通过 BlockTransferService 从 Driver 获取 ShuffleMapTask 上报的 write mapOut 生成的文件,
根据文件是否在同一个节点分别调用 getRemoteValues 和 getLocalValue 拉取对应分区的 FileSegment;
拉取的数据放着内存缓冲区中,根据
spark.shuffle.spill参数判断是否需要 spill 到磁盘。缓冲区大小由spark.reducer.maxMbInFlight(默认:5MB)设置。
- aggregate
spark shuffle write 后的数据不一定是全局有序的,在合并时,使用 hashmap 来处理从 filesegment 反序列化后生成的 record。
4. Spark Shuffle 改进
shuffle 作为连接 spark stage 中间的过程,涉及大量的数据操作,是整个计算过程的一大瓶颈,为此对 shuffle 问题及改进一直在进行。
4.1 External Shuffle Service
Spark 支持单独的服务来处理读取请求。这个单独的服务叫做 ExternalShuffleService,运行在每台主机上,管理该主机的所有 Executor 节点生成的 shuffle 数据。
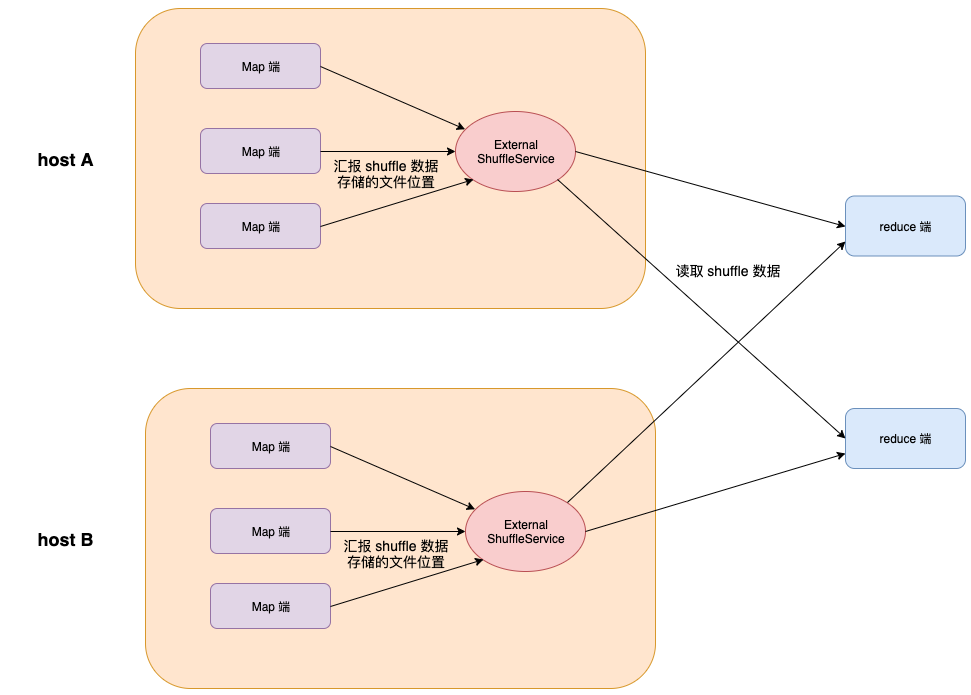
ESS 存在的问题:
External Shuffle Service 存在失效问题;
与 executor 节点紧密部署,不利于隔离,尤其在容器环境;
计算与存储未分离
4.2 [SPARK-1529]([SPARK-1529] Support DFS based shuffle in addition to Netty shuffle - ASF JIRA)
扩展了 shuffle 的文件系统接口,在 localFileSystem 上增加了 DistributedFileSystem,支持 HDFS 来存储 shuffle 数据,未实现,问题:spill 过程中可能产生很多小文件,hdfs 小文件写性能差( ~15%)
4.3 https://issues.apache.org/jira/browse/SPARK-25299
讨论了现有 external shuffle service 的不足,提出了几种使用远程存储的改进方案;
在官方 Spark Issue 中提到了用分布式文件系统代替本地磁盘进行 shuffle 数据存取的提案。
4.4 Splash
https://github.com/MemVerge/splash
支持不同存储插件的 shuffle 管理组件,支持 hdfs、nfs、s3 等多种存储接口。
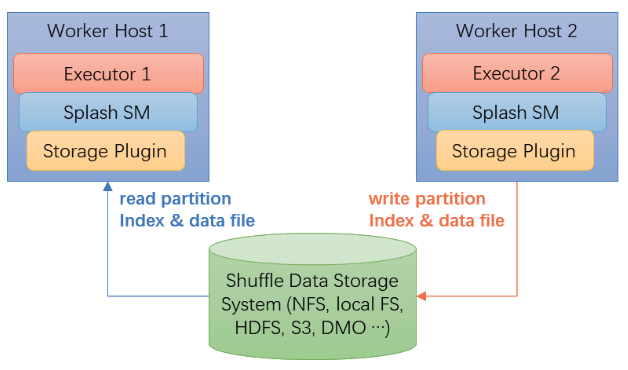
4.5 Alluxio for Shuffle
搜狗使用 alluxio 来存储 shuffle 数据实践# 搜狗实战案例:基于 Alluxio 优化 Spark Shuffle 性能

效果:
ReduceTask 可以直接从 Alluxio 获取所需 shuffle 数据,无需重算,避免原生的 Spark 会报 shuffle fetch failure 从而导致出现重算错误;
性能能够得到了比较大的提升;
5. Spark Shuffle with ChubaoFS
chubaofs 作为分布式文件系统,同时支持顺序写、随机写,支持大文件批量写的同时对小文件进行有比较好的优化性能,为解决 spark shuffle 的问题提供了很好的选择
方案 1:FuseClient/CSI
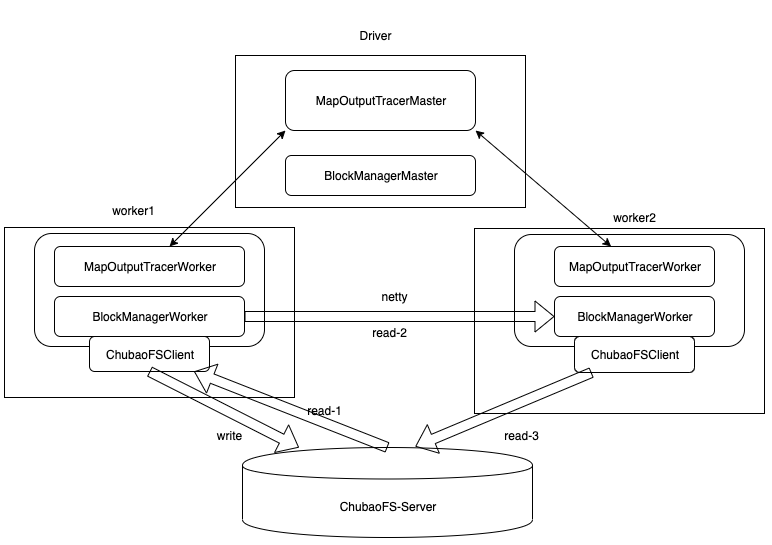
该方案主要使用 chubaofs 的 fuseclient 挂载 chubaofs 共享目录到 spark 的spark.local.dir本地目录上,使用 chubaofs fuseclient 为 spark shuffle 提供分布式共享存储
优点:
- 可直接在现有 spark 平台使用,无开发量;
缺点:
- shuffle read 阶段,存在间接重复传输问题,占用网络带宽;
- fuse client / csi 部署
方案 2:Native SDK 接口
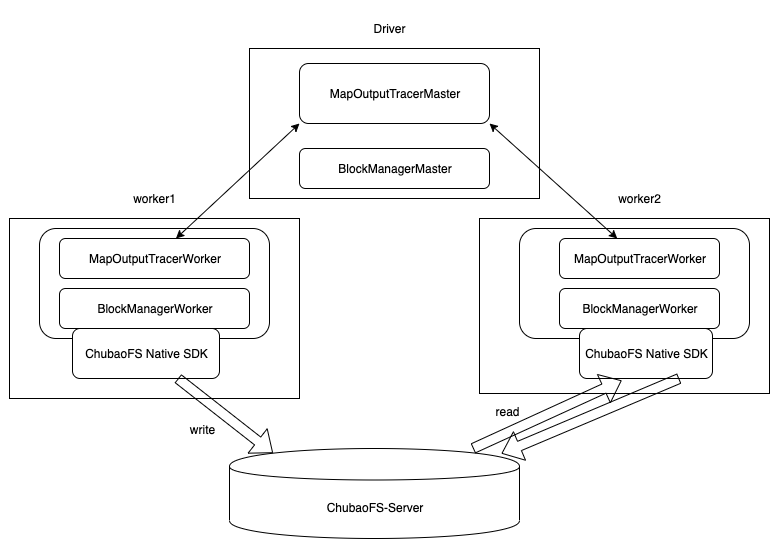
该方案通过在 Spark 中集成 ChubaoFS native SDK 方式使用 ChubaoFS,Spark 的 driver,worker 通过 native sdk 获取数据。
优点:
避免 shuffle read 数据重复传输;
支持 shuffle 文件合并选项,优化性能;
缺点:
需要开发 chubao fs native sdk 接口;
需要开发 spark chubaofs shuffle filestore 接口;
方案 3:Splash + FuseClient/NativeSDK
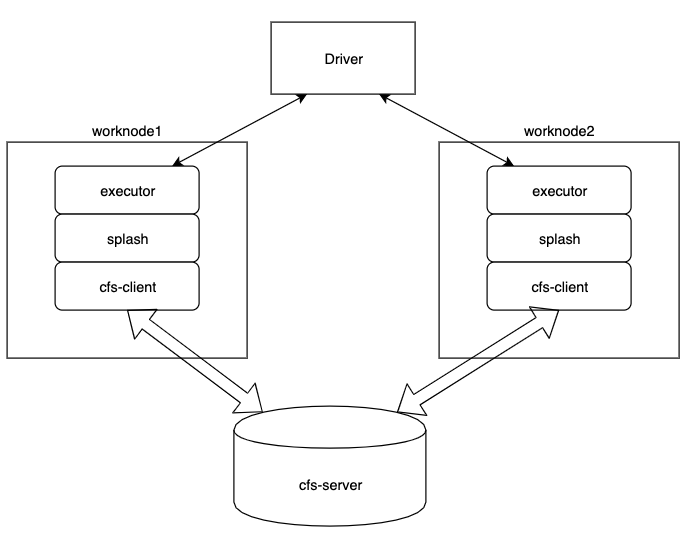
该方案使用 splash 提供的共享存储目录接入 chubaofs,提供 spark shuffle 提供共享存储
优点:
splash 作为插件,和 spark 源码相对独立;
fetch 不存在两次读问题;
开发工作量少;
缺点:
- splash 没有经过验证,不够成熟;
RSS
remote shuffle service, 是 JD 大数据 spark 团队自研的 shuffle service,是针对 spark 官方 ESS 的不足做的一个改进,其改进有如下几点:
将 ess 原来的每个 executor node 部署独立出来,成为单独的服务集群,并提供 shuffle write/shuffle read 功能(原 ess 主要提供 shuffle read);
优化 reduce 流程;
实现 executor 的存储计算分离,有利于容器化部署及资源调度;
其后端存储初期使用本地文件系统,后期将使用分布式存储(alluxio,cfs 等);

优点:
- 只需与 rss 适配,开发量少;
缺点:
- 依赖 rss;
参考
https://xuechendi.github.io/2019/04/15/Spark-Shuffle-and-Spill-Explained
http://chengfeng96.com/blog/2019/03/20/Spark-Shuffle%E8%B0%83%E7%A0%94%E7%AC%94%E8%AE%B0/
[SPARK-25299][DISCUSSION] Improving Spark Shuffle Reliability - Google 文档
https://www.waitingforcode.com/apache-spark/external-shuffle-service-apache-spark/read
https://zhmin.github.io/2019/08/05/spark-external-shuffle-service/
http://jerryshao.me/2014/01/04/spark-shuffle-detail-investigation/
[SPARK-1529] Support DFS based shuffle in addition to Netty shuffle - ASF JIRA
[SPARK-25299][DISCUSSION] Improving Spark Shuffle Reliability - Google 文档
[SPARK-16817][CORE][WIP] Use Alluxio to improve stability of shuffle by replication of shuffle data by Chopinxb · Pull Request #22005 · apache/spark · GitHub: alluxio shuffle manager, Use Alluxio to improve stability of shuffle by replication of shuffle dataloyiit
Spark Shuffle Read 阶段里的 fetch block 源码分析_大数据_don_chiang709的专栏-CSDN博客