Spark 基础
简介
Spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校 AMPLab,2010 年开源,2013 年 6 月成为 Apache 孵化项目,2014 年 2 月成为 Apache 顶级项目。项目是用 Scala 进行编写。
Spark 是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。
特性
基于内存,高性能;
同时支持流批两种方式;
拥有多种算子;
多语言支持;
架构
Spark 架构采用了分布式计算中的 Master-Slave 模型,支持Yarn、Mesos、K8S进行资源调度,主要组件包括:
Driver Node:
Cluster Manager:
Worker Node:
运行
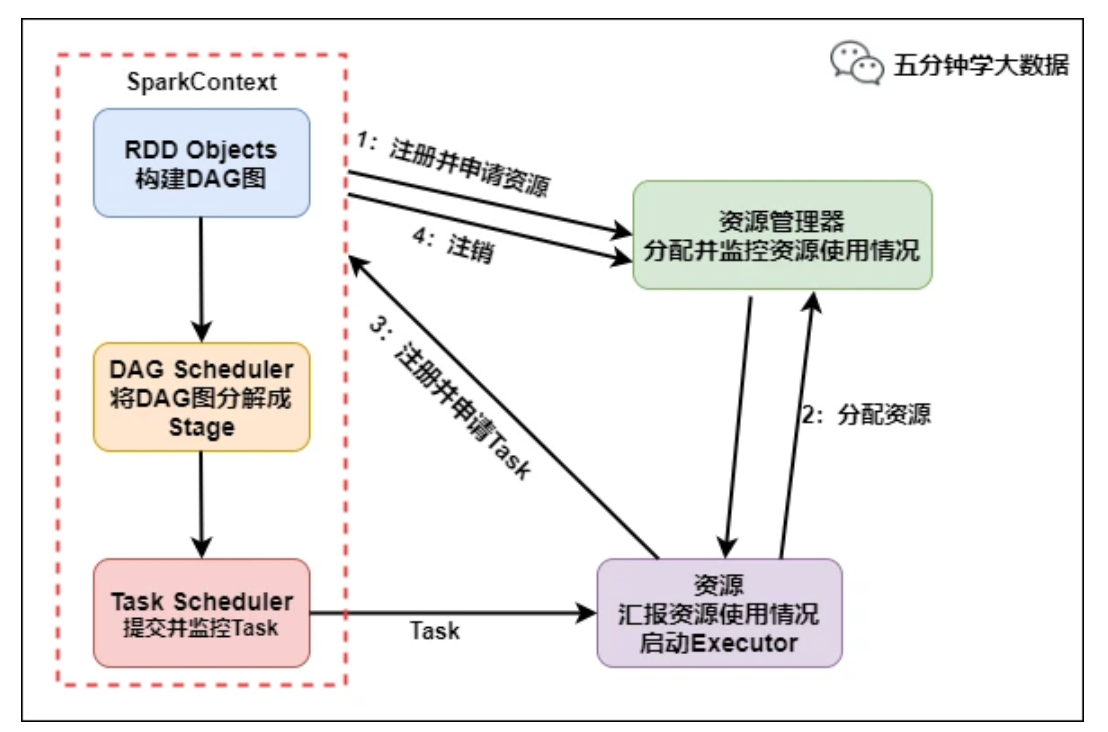
运行流程如下:
- SparkContext 向资源管理器注册并向资源管理器申请运行Executor
- 资源管理器分配Executor,然后资源管理器启动Executor
- Executor 发送心跳至资源管理器
- SparkContext 构建DAG有向无环图
- 将DAG分解成Stage(TaskSet)
- 把Stage发送给TaskScheduler
- Executor 向 SparkContext 申请 Task
- TaskScheduler 将 Task 发送给 Executor 运行
- 同时 SparkContext 将应用程序代码发放给 Executor
- Task 在 Executor 上运行,运行完毕释放所有资源
核心概念
- RDD: Resilent Distributed DataSets,弹性数据集。
Stage
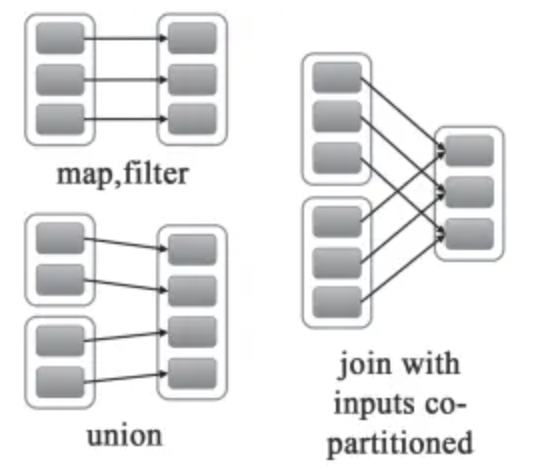
窄依赖(Narrow Depency):
- 父RDD的每个分区只被一个子RDD分区使用,子RDD分区通常只对应常数个父RDD分区
- child RDD 只依赖于 parent RDD(s)固定数量的 partition;
- 窄依赖的函数有:
map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
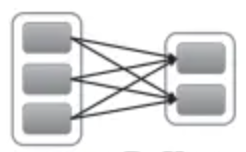
宽依赖(Wide Depency):
父RDD的每个分区都有可能被多个子RDD分区使用,子RDD分区通常对应父RDD所有分区;
子RDD的每一个 partition 都依赖于 父RDD(s)的所有 partition;
宽依赖往往对应着shuffle操作;
宽依赖的函数有:
groupByKey
join(父RDD不是hash-partitioned );
partitionBy;
stage: 根据宽依赖和窄依赖,
- 从后往前回溯/反向解析,遇到窄依赖加入本Stage,遇见宽依赖进行Stage切分。
stage 分为两种, ResultStage 和 ShuffleMapStage,
spark job 中产生结果最后一个阶段生成的 stage 是 ResultStage ,
中间阶段生成的 stage 是 ShuffleMapStage
Partition
Spark RDD 是一种分布式的数据集,由于数据量很大,因此要它被切分并存储在各个结点的分区当中。从而当我们对 RDD 进行操作时,实际上是对每个分区中的数据并行操作。