Pulsar
简介
Pulsar 是一个用于服务器到服务器的消息系统,具有多租户、高性能等优势。
Pulsar 最初由 Yahoo 开发,目前由 Apache 软件基金会管理。
架构
- Pulsar采用存储计算分离的架构,pulsar使用了bookkeeper做消息的存储,bookkeeper保证了消息存储的可靠性和高效性,bookkeeper为pulsar提供了存储的扩展能力
- Pulsar使用zk做元数据存储
- 多租户,pulsar最初的设计就是支持多租户的
- 命名空间:一个租户可以有多个命名空间,一个topic属于一个命名空间,pulsar中的配置都是以命名空间为单位配置的
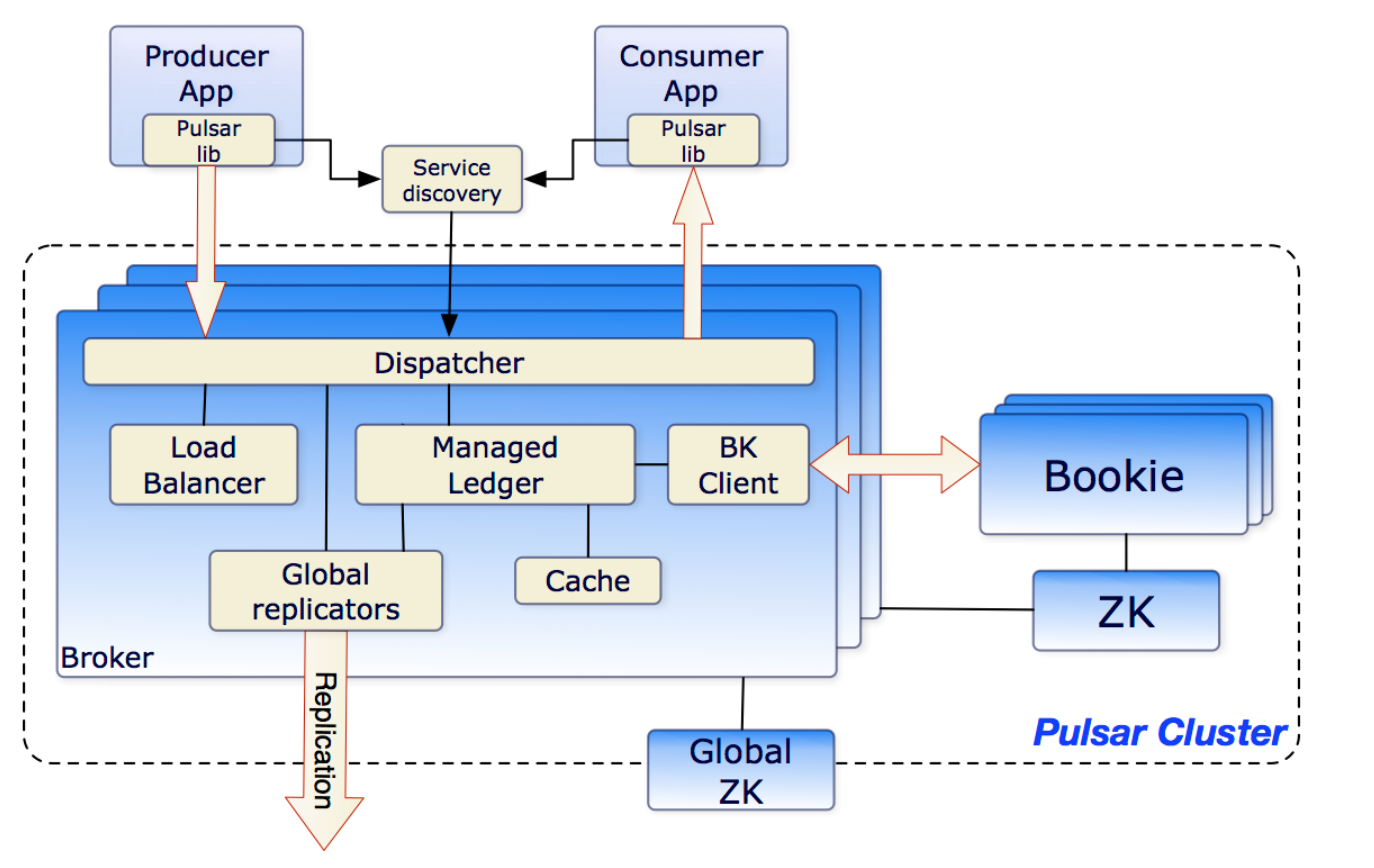
关系架构图

property/tenant:一个property代表一个租户,一个property可包含多个namesapce;假设部署了一个Pulsar集群来支持多个应用程序,在企业中每个property都可以代表一个团队,一个核心的功能,或者一个产品线;
namespace:是Pulsar的基本管理单元,在namaspace级别可设置权限permission,备份fine-tune,跨集群管理消息数据的地理复制geo-replication、消息TTL等;一个namaspace里的所有topic都继承相同的设置;
topic:一种通道,用作从producer到consumer传输消息:持久(默认,硬盘)和非持久(仅内存);
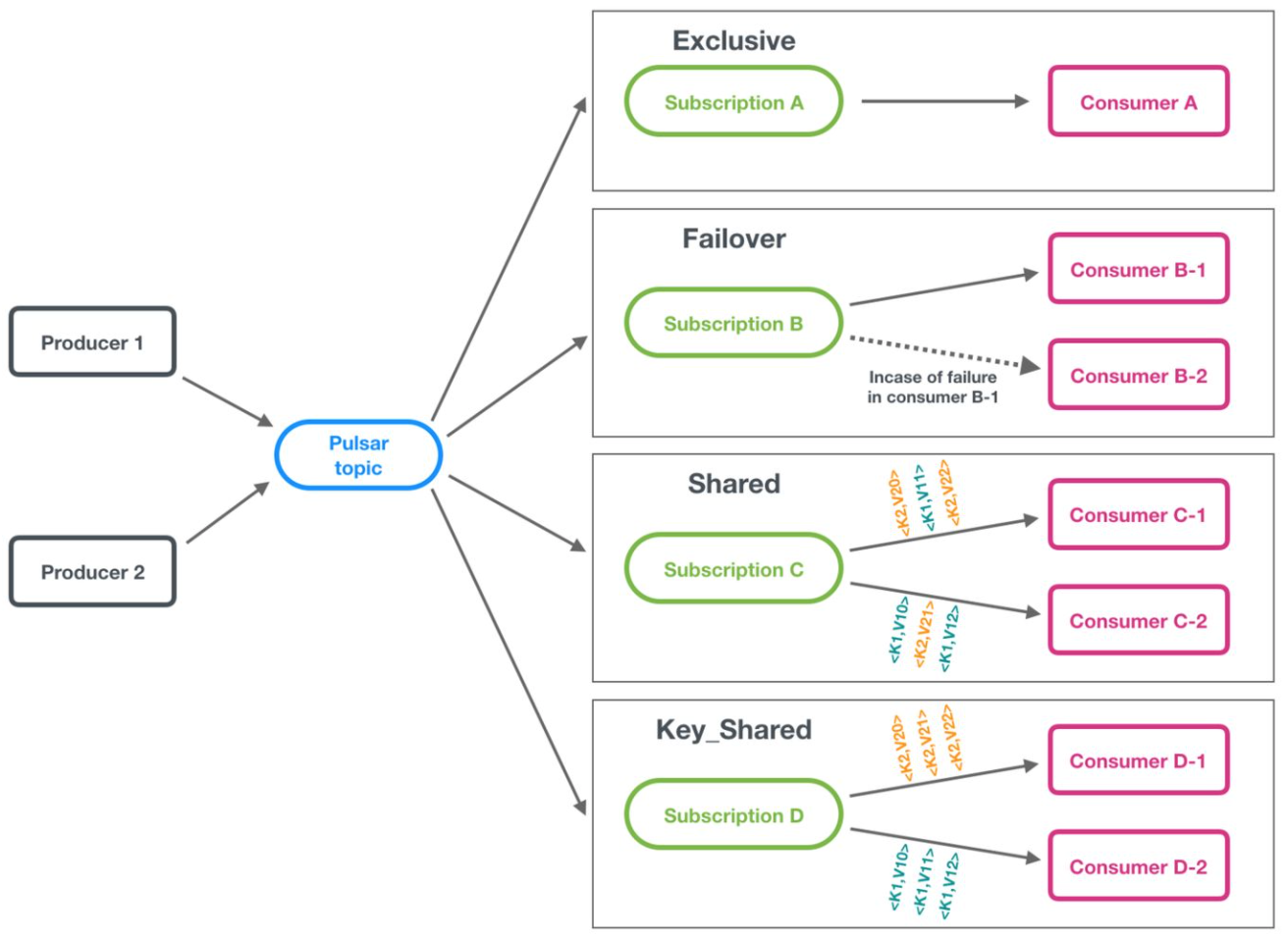
订阅模式
Pulsar使用同一个模型支持流和队列语义。这个特性可以通过订阅模型实现。消费者使用订阅模型中的任何一个订阅主题:
Exclusive: pulsar默认的消息订阅模式,支持流语义,在这种模式下,中能有一个consumer消息消息,一个订阅关系中只能有一台机器消费每个topic,如果有多于一个consumer消费此topic则会出错
Failover:同一时刻只有一个有效的Consumer,支持流语义,其余的Consumer作为备用节点,在Master Consumer不可用后进行替代。
Shared: 支持队列语义
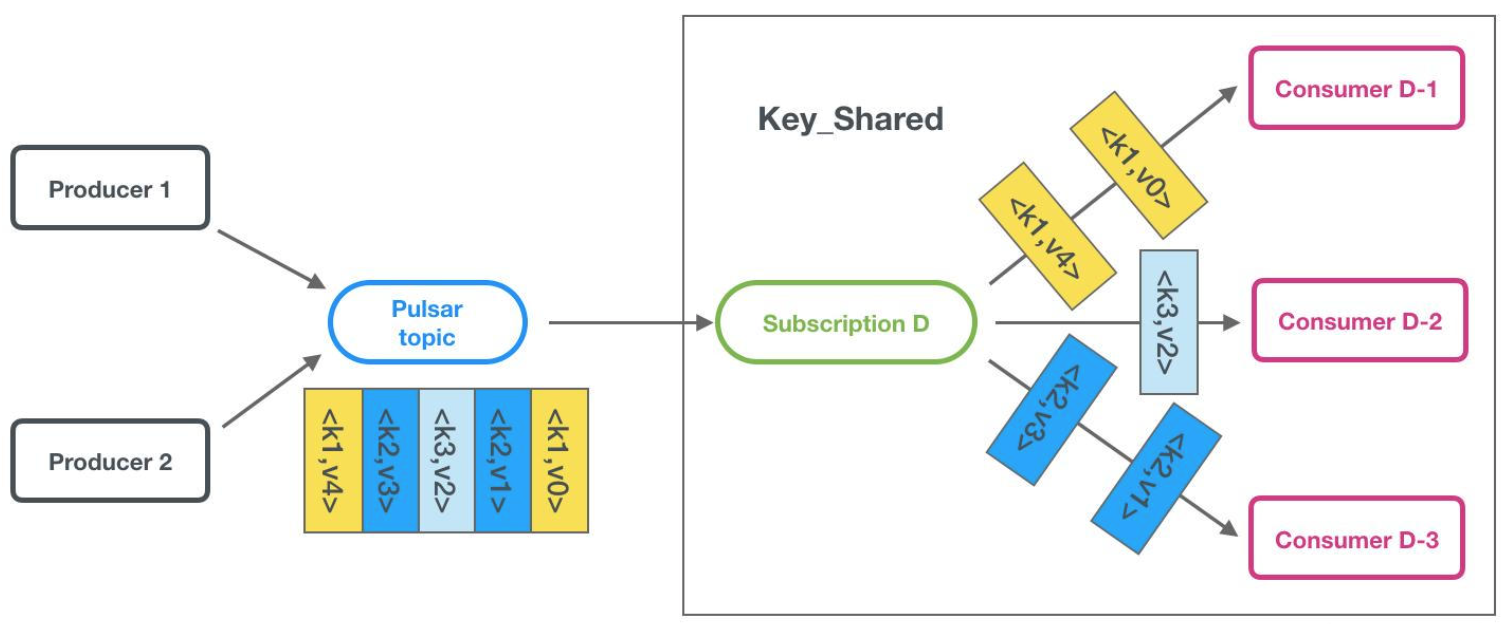
KeyShared:类似于shared模式,但是相同key的消息会传递给同一个消费者,(该模式限制:消息必须指定key/orderingKey;不能使用累计确认;该模式目前是测试版,可禁用);
ExclusiveMode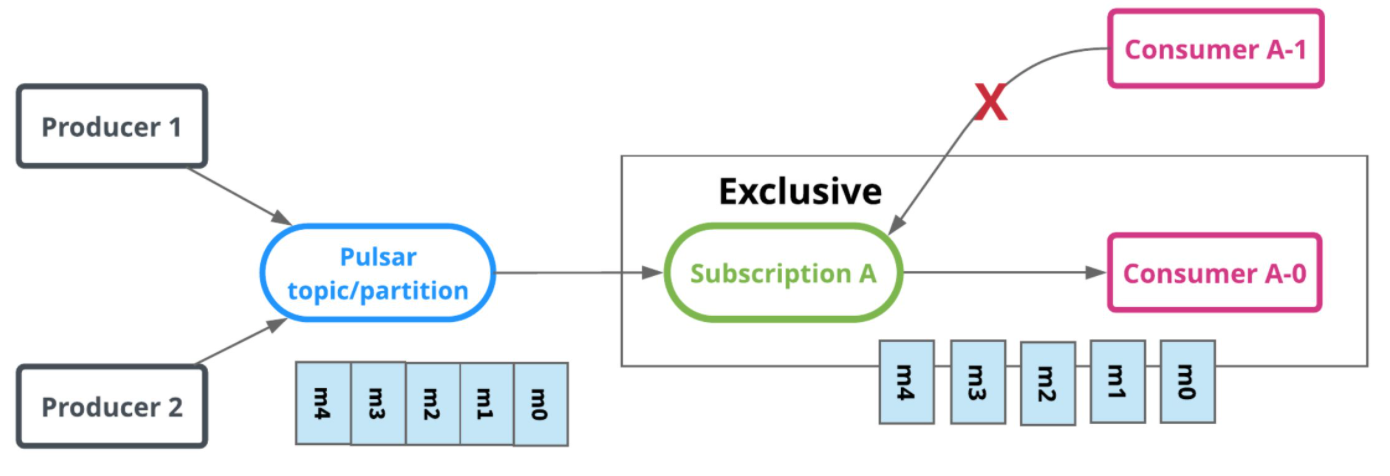 ◎ ExclusiveMode
◎ ExclusiveMode
Failover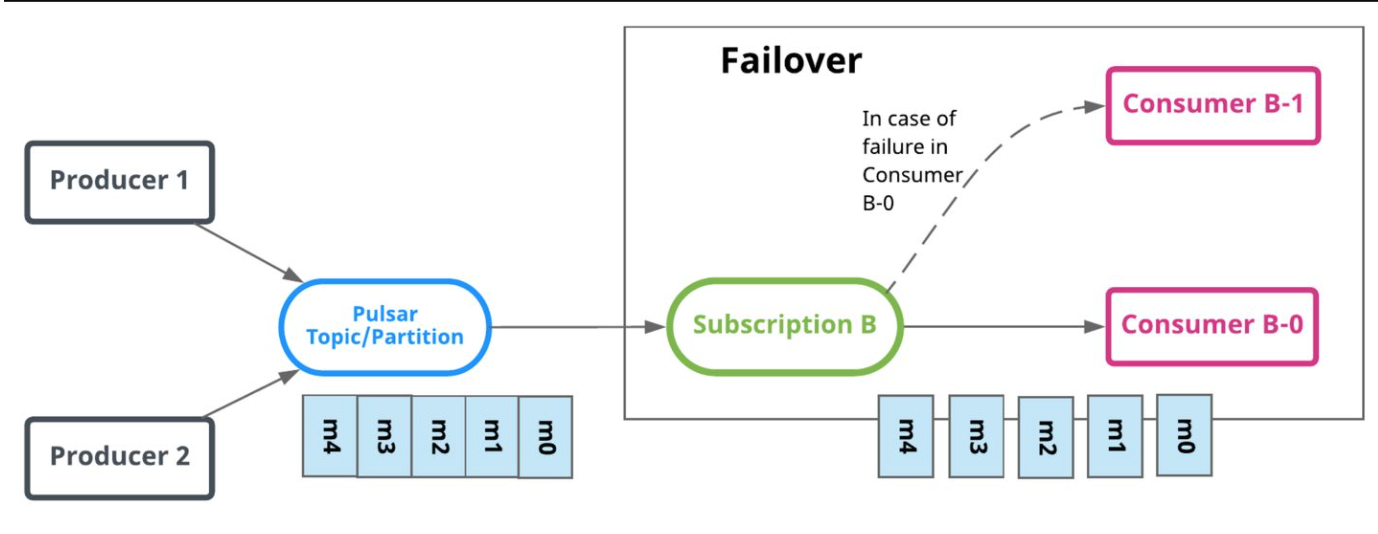 ◎ Fail
◎ Fail

消息分区
Pulsar 的 Topic 分为 Partitioned Topic 和 Non-Partitioned Topic 两类,Non-Partitioned Topic 可以理解为一个分区数为1的 Topic。
实际上在 Pulsar 中,Topic 是一个虚拟的概念,创建一个3分区的 Topic,实际上是创建了3个“分区Topic”,发给这个 Topic 的消息会被发往这个 Topic 对应的多个 “分区Topic”。
分区 Topic 做数据持久化时,分区是逻辑上的概念,实际存储的单位是分片(Segment)的。
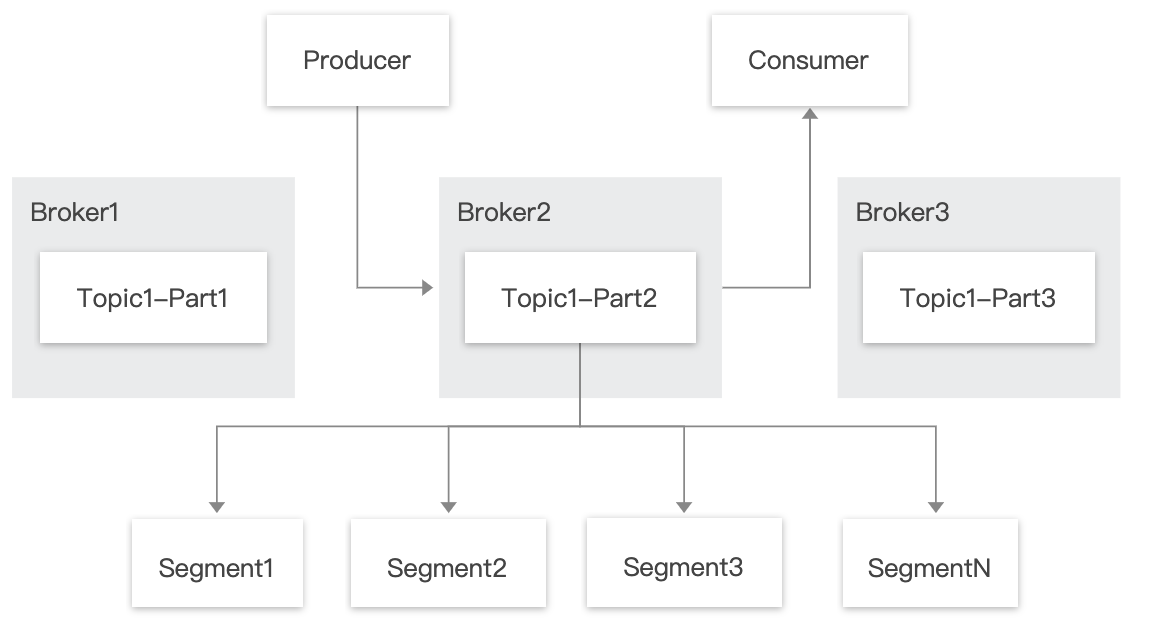
物理分区:计算与存储耦合,容错需要拷贝物理分区,扩容需要迁移物理分区来达到负载均衡。
逻辑分区:物理“分片”,计算层与存储层隔离,这种结构使得 Apache Pulsar 具备以下优点。
Broker 和 Bookie 相互独立,方便实现独立的扩展以及独立的容错。
Broker 无状态,便于快速上、下线,更加适合于云原生场景。
分区存储不受限于单个节点存储容量。
分区数据分布均匀,单个分区数据量突出不会使整个集群出现木桶效应。
存储不足扩容时,能迅速利用新增节点平摊存储负载。
消息 ID 生成规则
在 Pulsar 中,每条消息都有自己的 ID(即 MessageID),MessageID 由四部分组成:ledgerId:entryID:partition-index:batch-index。其中:
- partition-index:指分区的编号,在非分区 topic 的时候为 -1。
- batch-index:在非批量消息的时候为 -1。
消息去重
Pulsar和Kafka对比
- pulsar是流式处理(kafka)和队列的合体;
- 都支持分区,但pulsar不是必须;
- pulsar的broker是无状态的,而kafka是有状态的;
- pulsar简单的跨域赋值、扩容简单,数据处理快;