Ozone
简介
Ozone是专门为Hadoop设计的可扩展的分布式对象存储系统。Hadoop生态中的其它组件如Spark、Hive和Yarn不需要任何修改就可以直接运行在Ozone之上。Ozone的使用方式也较为丰富,可以通过命令行直接使用也有java客户端接口,而且接口支持RPC和REST。
Ozone的提出在2014年,由Hortonworks率先提出,并建立了一个JIRA:HDFS-7240(Object store in HDFS)。一个大背景是当时许多企业已经推出了对象存储的服务而HDFS还不支持。
特点
- SCALABLE(可扩展性):Ozone可扩展到数百亿个文件和块,并在未来甚至更多。
- CONSISTENT(一致性):Ozone是一个非常一致的对象存储。 通过使用诸如RAFT之类的协议来实现这种一致性。
- SECURE(安全):Ozone与kerberos基础设施集成,用于访问控制,并支持TDE和线上加密。
- MULTI-PROTOCOL SUPPORT(多协议支持):Ozone支持不同的协议,如S3和Hadoop文件系统API
- HIGHLY AVAILABLE(高可用性):Ozone是一个完全复制的系统,旨在经受多次故障。
- Interoperability with Hadoop Ecosystem:Ozone的设计适用于YARN和Kubernetes等集装箱化环境;Ozone可以被现存的Hadoop生态和相关的应用(如 apache hive、apache spark 和传统的 mapreduce)使用,因此Ozone支持: Hadoop Compatible FileSystem API(也叫OzoneFS) – hive、spark等可以使用OzoneFS API Ozone作为存储层,而不需要做任务修改。
架构
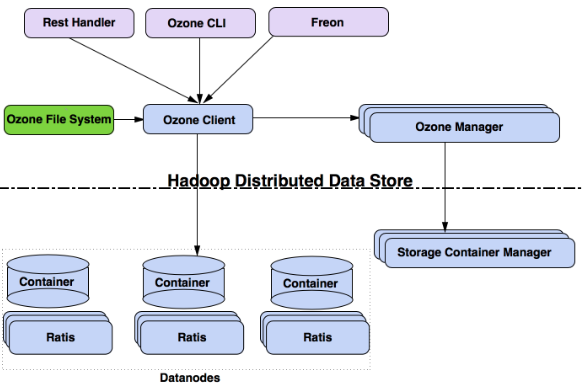
在架构上Ozone由三部分组成,分别为Ozone Manager、Storage Container Manager和Datanodes
Ozone Manager: OzoneManager是一个server服务,主要负责Ozone的namespace,记录所有的volume, bucket和key操作。有点类似HDFS的namenode
SCM: 类似HDFS中的block manager,是Ozone中一个非常重要的组件,用来管理container的,为OM提供基于block和container的服务。
基本概念
- Container:容器,由这些容器对外提供块存储服务。每个容器有自己的大小空间,即所属的 DN 节点。在 HDDS 模式下,DN 管理的将不再是直接的块副本数据,而是 Container 容器副本。Replication 操作以及 DN 的心跳汇报都是基于容器层面来做的。
- Block:块存储单元,与 HDFS 模式下的块类似。是存储数据的单元,也是客户端实际数据写入单元。
- Chunk:实际文件存储,一个 Block 块单元由一组 Chunk 文件组成。
- Pipeline:管道,这个管道信息指容器实际位置的节点信息。比如 Pipeline 中包含 3 个节点,意为容器需要 Replication 在这 3 个节点上。当然,在后续容器数据写入的时候,也会保证 Pipeline 节点上的数据一致。
- SCM:容器管理服务(Storage Container Manager)。这个服务类似于 HDFS 的 NN 这样的角色。SCM 服务是 HDDS 中十分核心的服务,它负责管理所有的容器分配、删除等操作。对于外部使用者而言,它们都需要向 SCM 请求分配容器来提供块的存储写入。
- KSM(OM):对象存储管理服务(Key Space Manager,命名空间管理服务)。原先 KSM 服务与 SCM 服务都是偏向于底层服务的,但是 KSM 实际的功能属性是对象存储的元数据管理,所以后来更名为 Ozone Manager(OM)服务了。KSM 服务属于构建于 HDDS 其上的一个应用服务。
Container作为Ozone中的一个基本存储单元,它只包含2大类信息,一个是key,一个是文件对象。key由bucket、volume名称拼装而成,而文件对象由其内部的ChunkInfo信息所维护。下图是Container的内部结构图:
 ng)
ng)
组件
- KSM(Key Space Manager)
- SCM(Storage Container Manager)
- HDDS(Hadoop Distributed Data Store)
Ozone的调用过程可以理解为是一个寻找Container的过程。中间过程中,需要向2大服务KSM、SCM进行Container的定位和获取。前者负责提供Container的位置,然后后者负责返回Container对象。(但是目前代码中这2个功能都耦合在了SCM上面)。社区将其分离化的一个主要目的是为了方便后续的扩展。
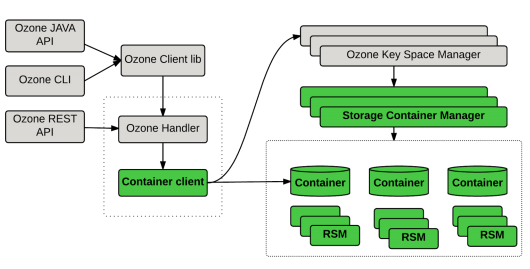
Pipeline
目前Ozone可提供2种副本机制:
- 1.完全单副本方式,就是standalone模式。
- 2.用外部框架Apache Ratis(分布式一致性算法Raft的Java实现)实现多副本方式。
参考
- https://blog.csdn.net/Androidlushangderen/article/details/78450332
- http://blogspring.cn/view/73
- HDFS对象存储–Ozone架构设计_走在前往架构师的路上-CSDN博客
- HDFS Ozone的Pipeline实现机制_走在前往架构师的路上-CSDN博客
- https://www.zhihu.com/search?type=content&q=ozone%20hadoop
- HDFS对象存储–Ozone架构设计 - zsychanpin - 博客园
- Hadoop 对象存储 Ozone - 云+社区 - 腾讯云
- HDFS对象存储–Ozone架构设计 - 程序园