MySQL基础
简介
- mysql是
架构
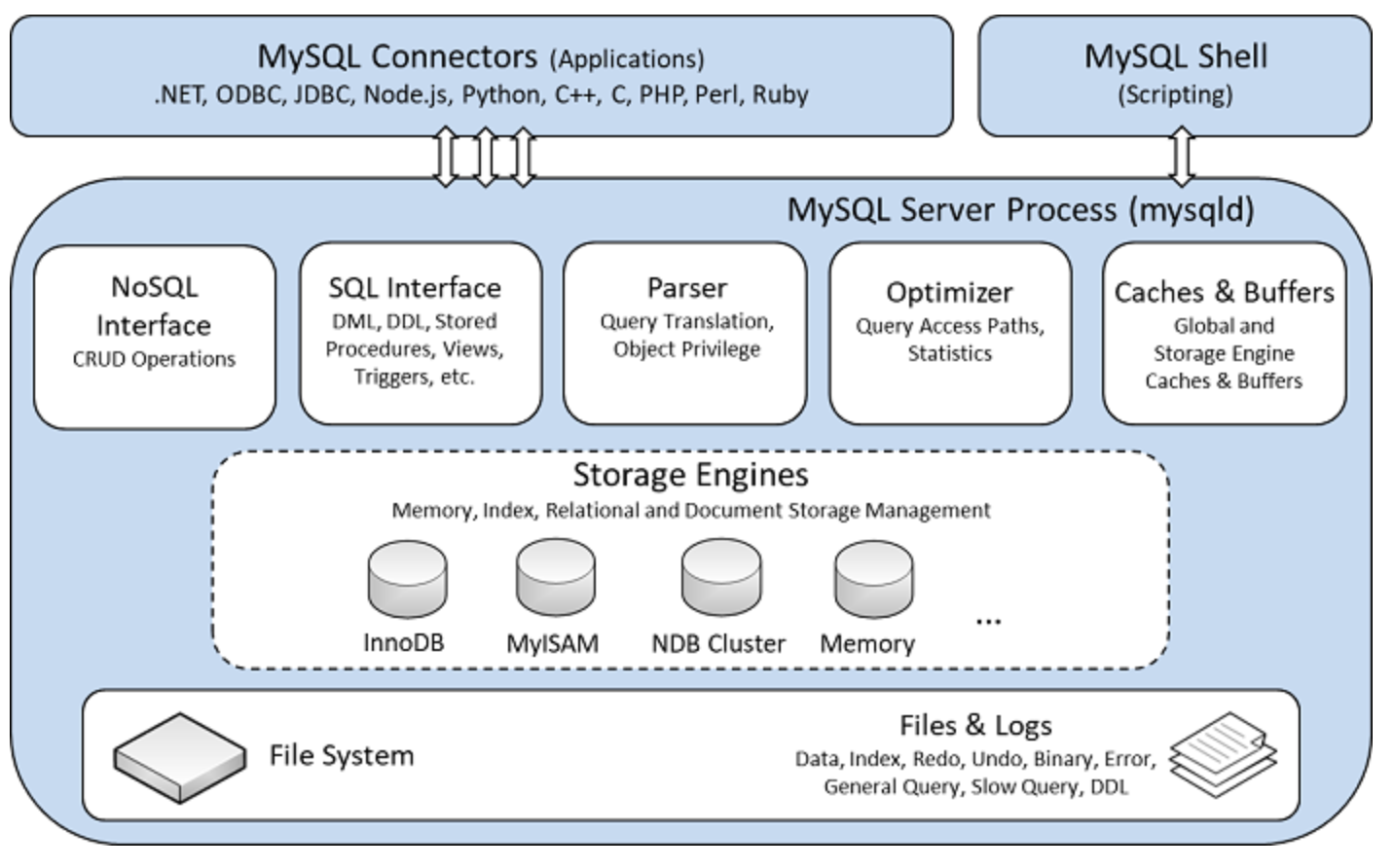
特点
设计范式
1NF: 原子性,保证每列不可再分, 保证表中无表;
2NF: 消除部分依赖,在满足1NF上,每个属性完全依赖于主键;
3NF: 消除传递依赖,在满足2NF上,属性不依赖于其他非主属性;
BCNF: 在满足3NF上,
索引
- 聚集索引:根据主键来构建,叶子节点存放的是该主键对应的这一行记录
- 普通索引:根据申明这个索引时候的列来构建,叶子节点存放的是这一行记录对应的主键的值
- 唯一索引:在插入和修改的时候会校验该索引对应的列的值是否已经存在
- 联合索引:将两个列的值按照申明时候的顺序进行拼接后在构建索引。
数据是以行为单位存储在聚簇索引里的,根据主键查询可以直接利用聚簇索引定位到所在记录,根据普通索引查询需要先在普通索引上找到对应的主键的值,然后根据主键值去聚簇索引上查找记录,俗称回表。
普通索引上存储的值是主键的值,如果主键是一个很长的字符串并且建了很多普通索引,将造成普通索引占有很大的物理空间,这也是为什么建议使用 自增ID 来替代订单号作为主键,另一个原因是 自增ID 在插入的时候可以保证相邻的两条记录可能在同一个数据块,而订单号的连续性在设计上可能没有自增ID好,导致连续插入可能在多个数据块,增加了磁盘读写次数。
日志
- redolog:wal日志,保证数据库宕机后可以通过该文件进行恢复。
- undolog:事务回滚和 MVCC。
- binlog:高可用,也就是通过 binlog 来将数据同步到集群内其他的 MySQL 实例。
redolog和binlog区别:
- Binlog在存储引擎上层 Server 层写入的,记录的是逻辑操作,
- redolog 记录的底层某个数据页的物理操作;
- redolog 是循环写,
- binlog 是追加写的,不会覆盖以前写的数据
锁
InnoDB 中锁的最小粒度为行
- 共享锁:读,共享锁之间可以兼容
- 排他锁:写,其他都互斥。
根据加锁的范围,可以分为:
全局锁:全局锁会把整个数据库实例加锁,命令为 flush tables withs read lock ,将使数据库处于只读状态,其他数据写入和修改表结构等语句会阻塞,一般在备库上做全局备份使用。
表级锁
表锁: lock table with read/write ,和读写锁一样;
元数据锁:也叫意向锁,不需要显示申明,加索引的时候会自动加元数据写锁,对表进行增删改查的时候会加元数据读锁。这样当两条修改语句的事务之间元数据锁都是读锁不互斥,但是修改表结构的时候执行更新由于互斥就需要阻塞。
行锁:间隙锁,他锁定的是两条记录之间的间隙,防止其他事务往这个间隙插入数据,间隙锁是隐式锁,是存储引擎自己加上的。
锁的问题
- 脏读:指一个事物读取了另外一个事物没有提交的数据,如果另外一个数据对这个数据又进行了更改,则出现数据一致性,脏读违背了数据库的隔离性。脏读目前只能出现在读未提交这个隔离级别下,目前 MySQL 默认的隔离级别为可重复读。
- 不可重复读:指一个事务先后两次读取同一条记录的结果不一样,因为第二次读取的时候可能其他事务已经进行更改并提交,不可重复读只发生在隔离级别为读未提交和读已提交里。
- 丢失更新:两个事务同时更新某一条记录,导致其中一个事务更新失效,理论上任何一个隔离级别都不会发生丢失更新,因为更新的时候会加上排他锁,但是应用中却经常发生,例如一个计数器应用,事务A查询计数器的值 v=5,在内存中加 1 写入到数据库,在写入之前另外一个事务读取到计数器的值 v=5 ,然后加 1 写入数据库,这样本来应该为 7 , 现在却是 6 ,这是因为我们是先读取在写入,而读取和写入对数据库而言是两个操作,并不是一个原子操作,这里可以通过把查询的记录加上排他锁 select for update 来防止丢失更新现象。当然这里直接将 sql 改为 v = v + 1 也可以。
- 死锁:两个或两个以上事务因争夺资源而互相等待的情况,InnoDB 提供了死锁检测和超时机制来防止死锁的影响,死锁检测是非常耗 CPU 的,当很多个事务同时竞争同一个资源的时候,例如抢购的时候扣商品份额,或者支付的时候所有的订单都会用到一个公共账户,同一个资源竞争的事务越多,死锁检测越耗 CPU
- 热点:
事务
完全符合 ACID 特性。
- 原子性 : 是指一个事务内的所有操作要么全部成功要么全部失败,数据库中将 redolog 和 binlog 的写入采用两阶段提交就是为了保证事务的原子性。另外由于 InnodDB 是按页进行存储的,每个页大小为 16kb 而操作系统的一般以 4KB 为一页进行读取,所以可能出现一个 InnoDB 的数据页只写了一部分的情况。而 InnoDB 为了防止这种情况的发生采用双写机制,除了写入磁盘上的数据页还会在共享空间中写入。而 redolog 按块存储,每个块 512 字节,正好和扇区大小一样所以,可以保证原子性,不需要进行双写。
- 一致性 :保证磁盘和缓存的数据一致,binlog 数据和 主库中的数据一致。
- 隔离性 :默认为可重复读,采用 undolog 来实现。
- 持久性 :事务一旦提交,其结果就是永久的,redolog 需要在事务提交前进行刷盘,磁盘采用 RAID 等。
存储过程
MyISAM 和 INNODB的区别
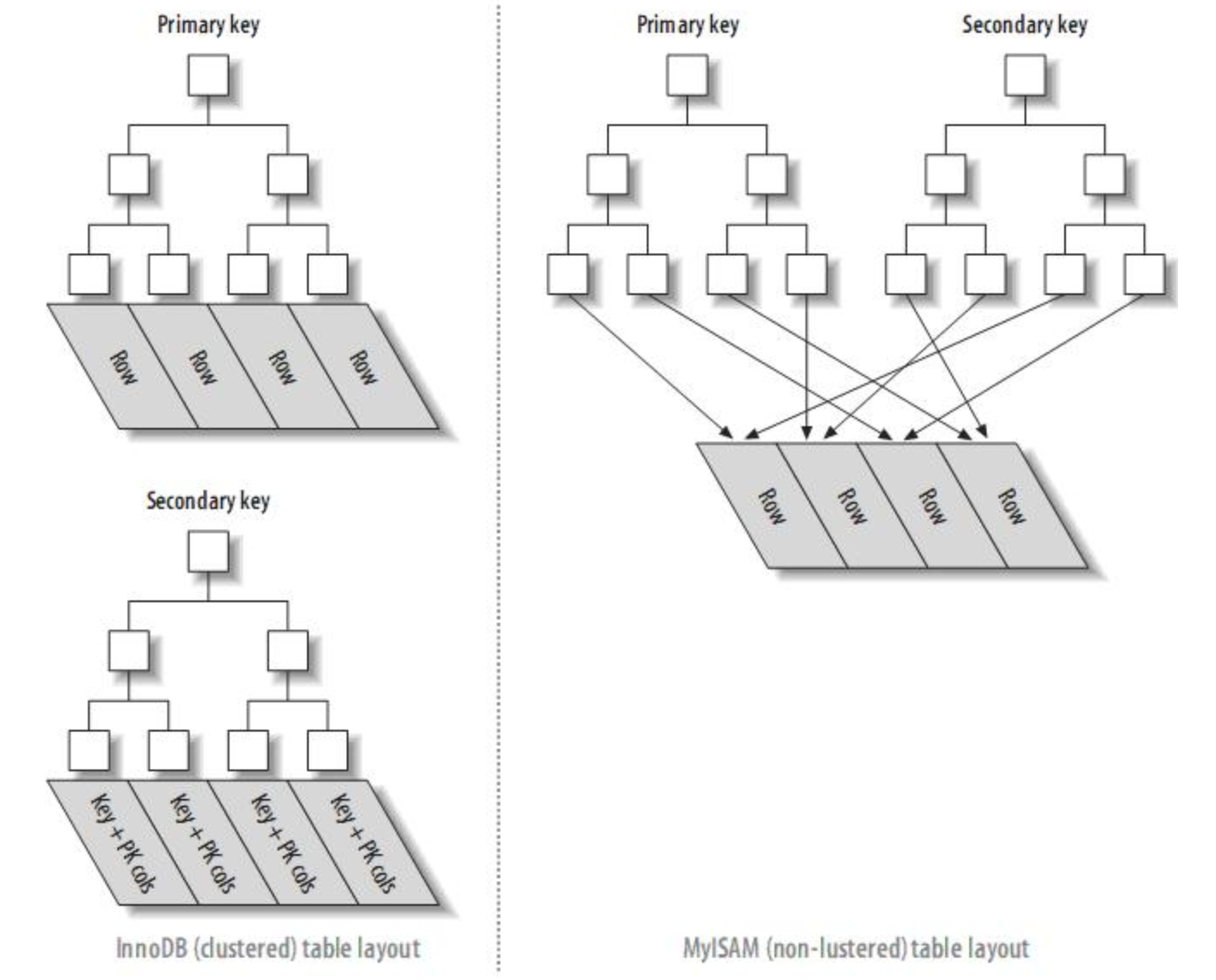
- MyISAM的索引和数据是分开的, innodb索引和数据是紧密捆绑的;
- MyISAM不支持事务,INNODB支持事务;
- 外键 MyISAM 不支持外键, INNODB支持外键;
- MyISAM时表锁,innodb是行锁;
- 查询和添加速度(MyISAM批量插入速度快)
- MyISAM支持全文索引,INNODB不支持全文索引;
- MyISAM内存空间使用率比InnoDB低
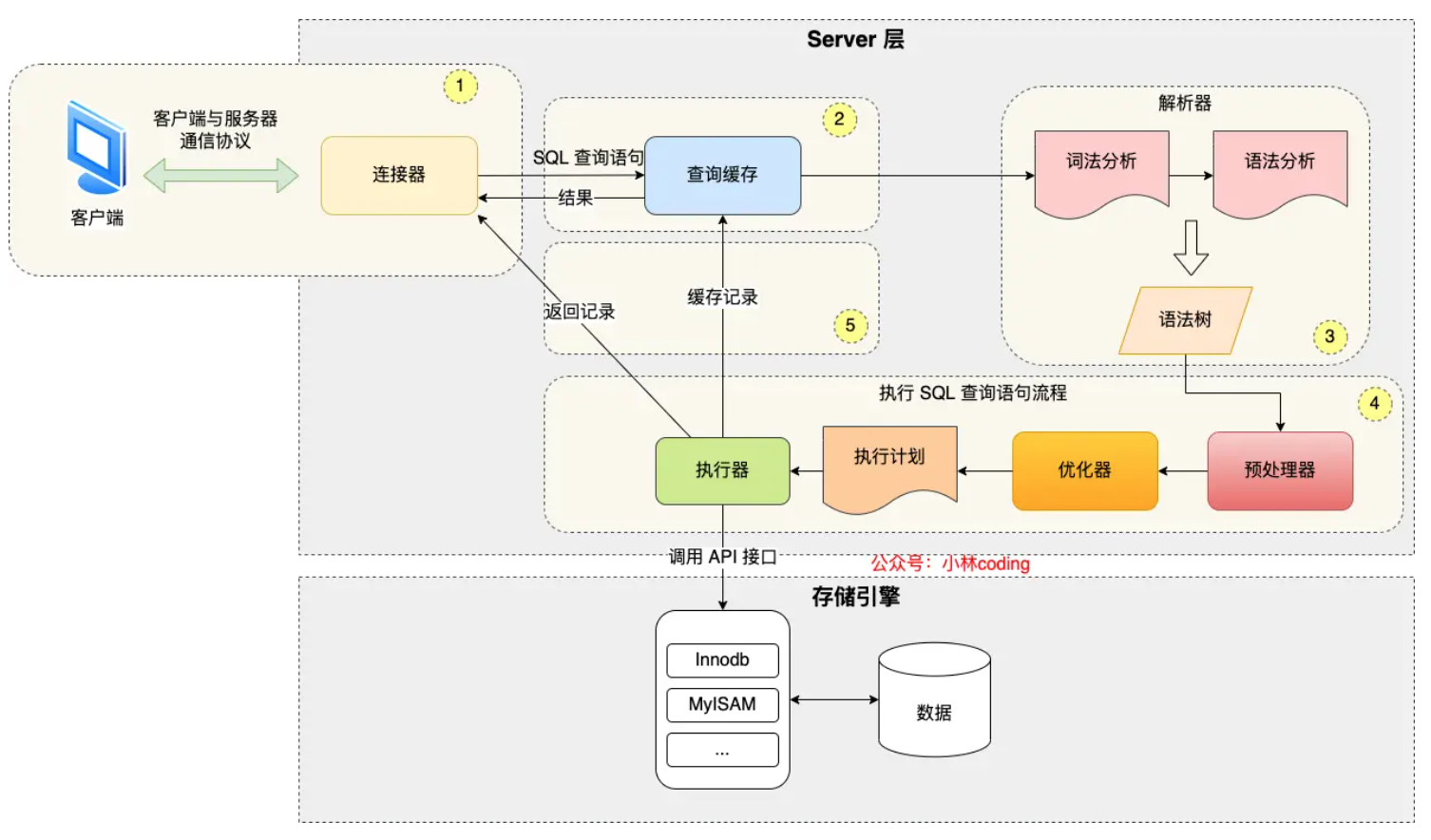
语句执行流程
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将
select *中的*符号扩展为表上的所有列。 - 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
- 预处理阶段:检查表或字段是否存在;将
存储结构
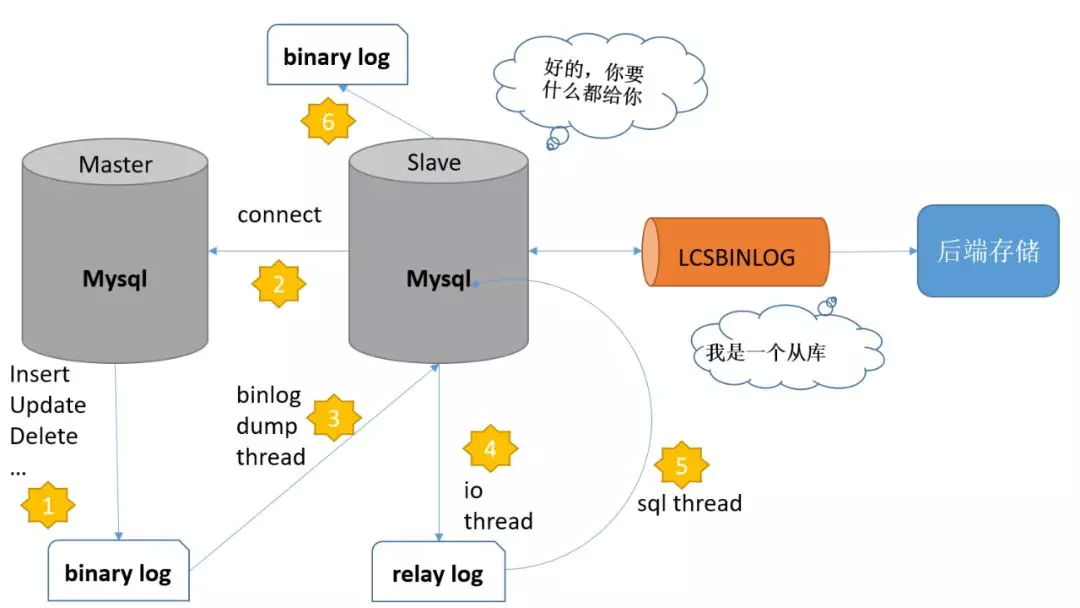
主从复制
- master(主库)在每次准备提交事务完成数据更新前,将改变记录到二进制日志 (binary log) 中
- slave(从库)发起连接,连接到 master,请求获取指定位置的 binlog 文件
- master 创建 dump 线程,推送 binlog 的 slave
- slave 启动一个 I/O 线程来读取主库上 binary log 中的事件,并记录到 slave 自己的中继日志 (relay log) 中
- slave 还会起动一个 SQL 线程,该线程从 relay log 中读取事件并在备库执行,完成数据同步
- slave 记录自己的 binlog
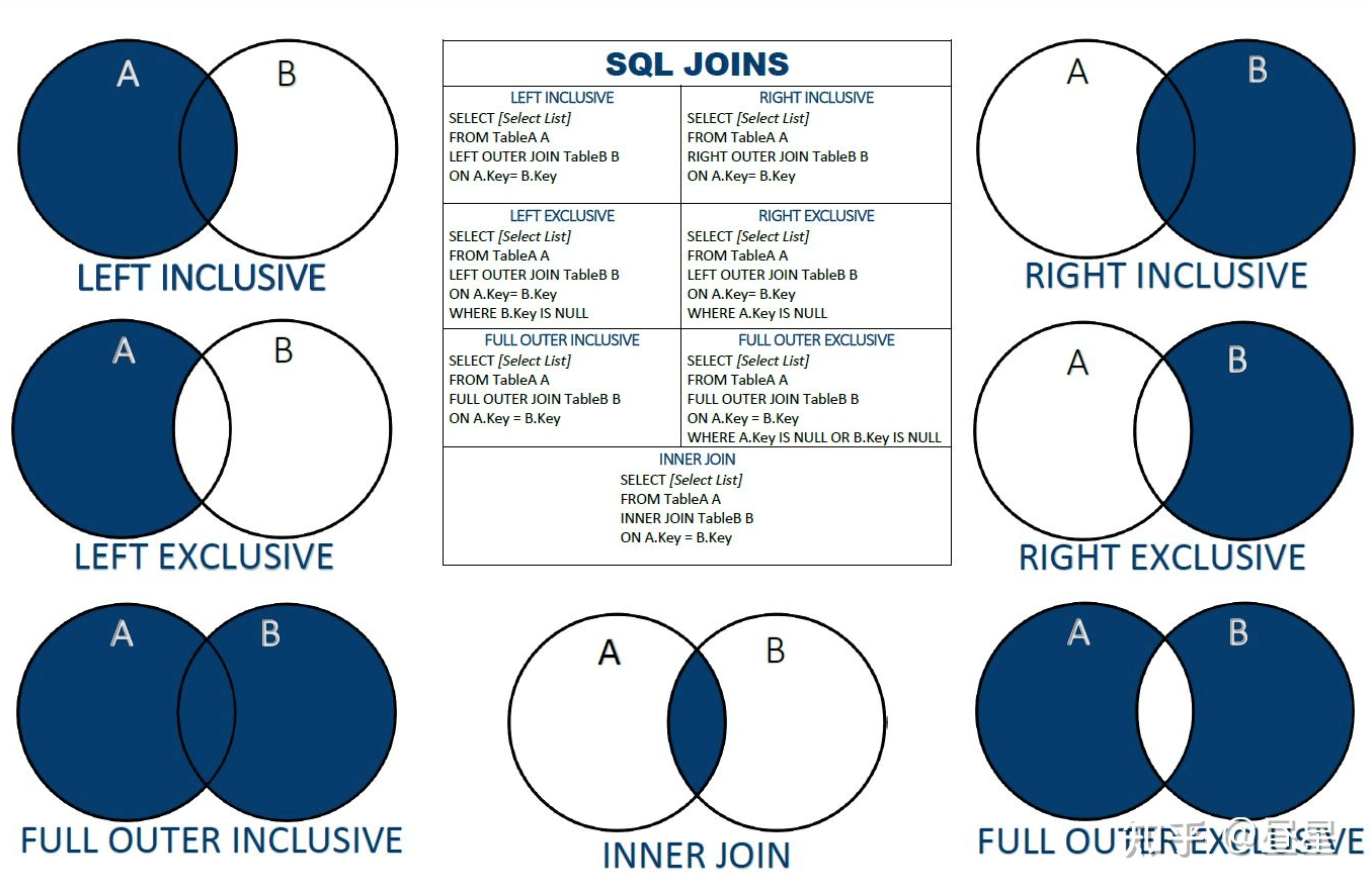
SQL 中的join