LevelDB
简介
LevelDB是Google的 Jeff Dean和Sanjay Ghemawat设计开发的key-value存储引擎,底层存储利用了LSM tree思想,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,适合应用在查询较少,而写很多的场景。
特点
key和value都是任意长度的字节数组;
entry(即一条K-V记录)默认是按照key的字典顺序存储的,也可以重载这个排序函数;
提供的基本操作接口:Put()、Delete()、Get()、Batch();
支持批量操作以原子操作进行;
可以创建数据全景的snapshot(快照),并允许在快照中查找数据;
可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot);
自动使用Snappy压缩数据;
可移植性;
非关系型数据模型(NoSQL),不支持sql语句,也不支持索引;
一次只允许一个进程访问一个特定的数据库;
设计思路
LevelDB的数据是存储在磁盘上的,采用LSM-Tree的结构实现。LSM-Tree将磁盘的随机写转化为顺序写,从而大大提高了写速度。为了做到这一点LSM-Tree的思路是将索引树结构拆成一大一小两颗树,较小的一个常驻内存,较大的一个持久化到磁盘,他们共同维护一个有序的key空间。写入操作会首先操作内存中的树,随着内存中树的不断变大,会触发与磁盘中树的归并操作,而归并操作本身仅有顺序写。
随着数据的不断写入,磁盘中的树会不断膨胀,为了避免每次参与归并操作的数据量过大,以及优化读操作的考虑,LevelDB将磁盘中的数据又拆分成多层,每一层的数据达到一定容量后会触发向下一层的归并操作,每一层的数据量比其上一层成倍增长。这也就是LevelDB的名称来源。
架构

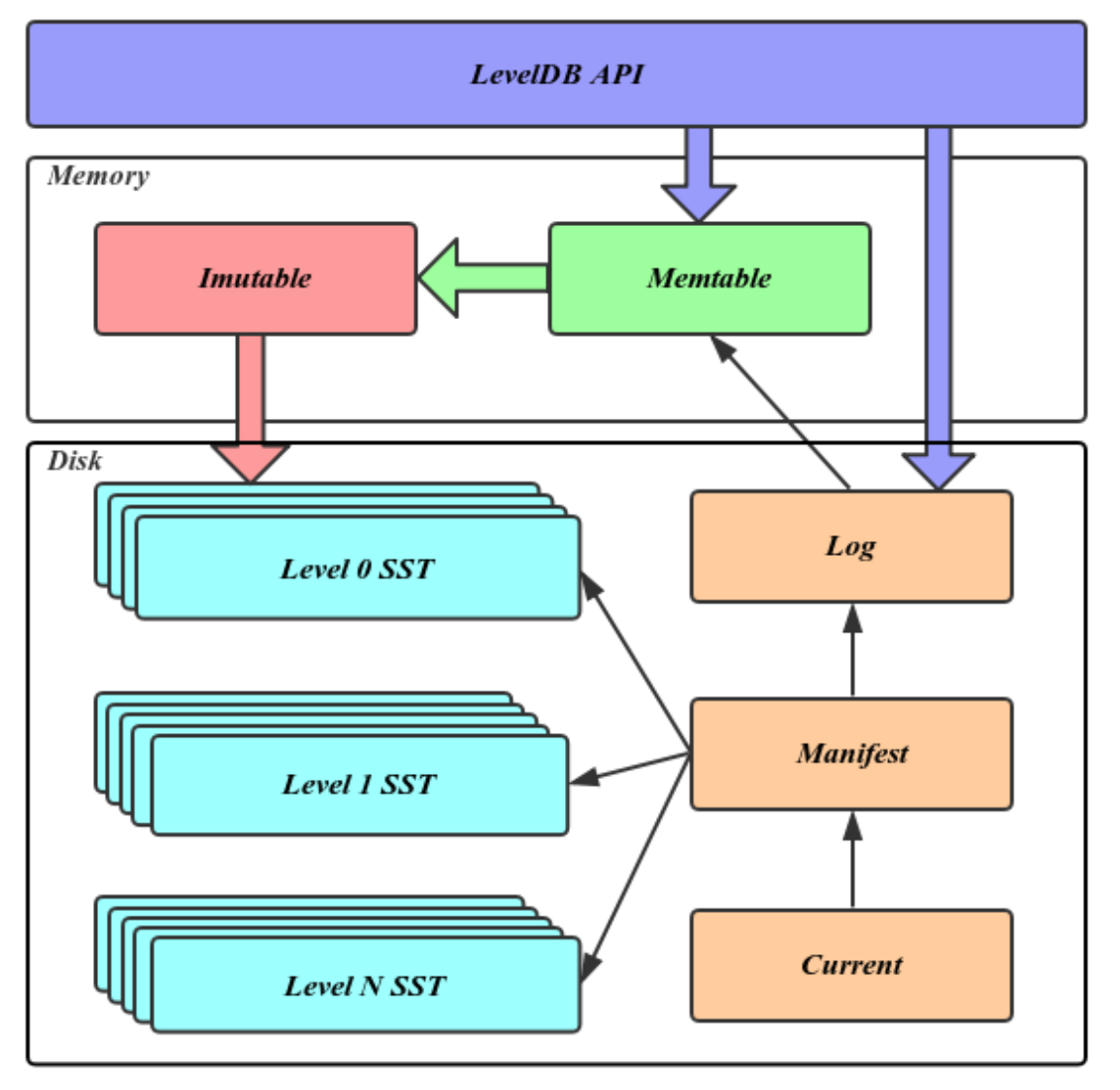
组成
Memtable:内存数据结构,跳表实现,新的数据会首先写入这里;
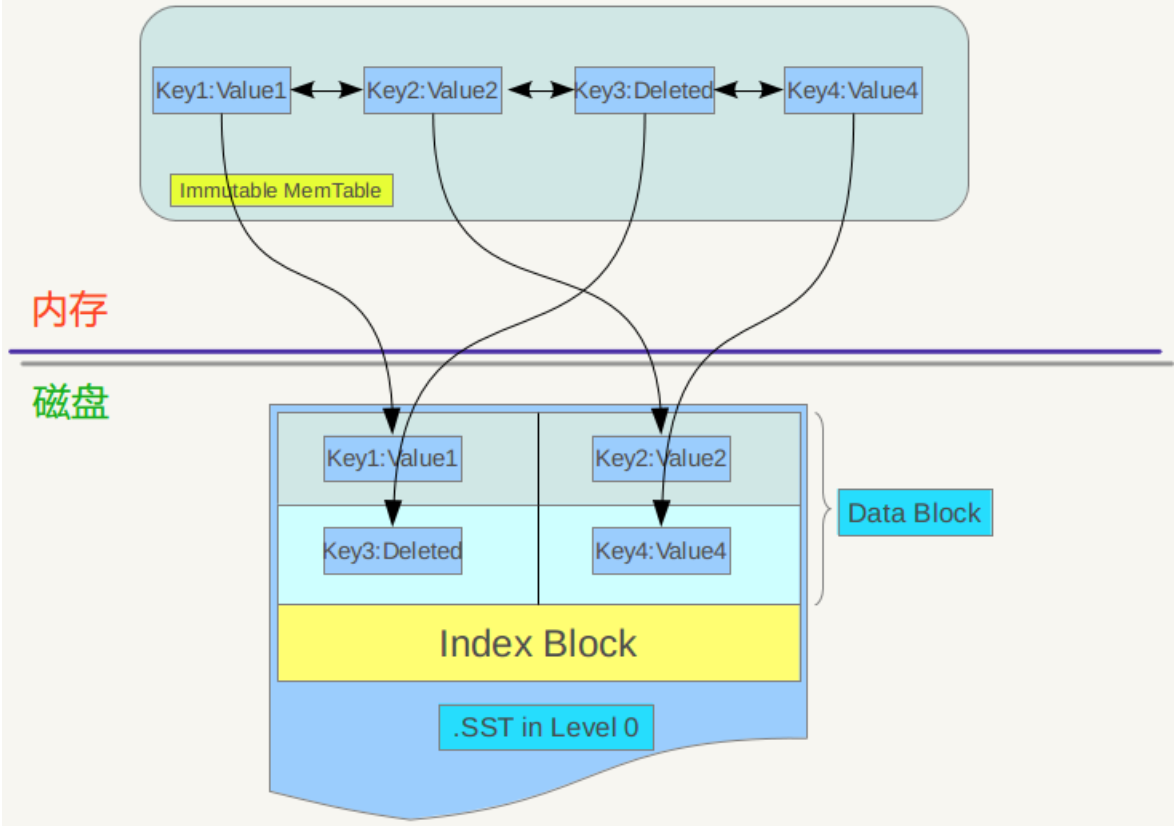
Immutable Memtable:达到Memtable设置的容量上限后,Memtable会变为Immutable为之后向SST文件的归并做准备,顾名思义,Immutable Mumtable不再接受用户写入,同时会有新的Memtable生成;
Log文件:写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log的存在使得机器宕机导致的内存数据丢失得以恢复;
SST文件:磁盘数据存储文件。分为Level 0到Level N多层,每一层包含多个SST文件;单层SST文件总量随层次增加成倍增长;文件内数据有序;其中Level0的SST文件由Immutable直接Dump产生,其他Level的SST文件由其上一层的文件和本层文件归并产生;SST文件在归并过程中顺序写生成,生成后仅可能在之后的归并中被删除,而不会有任何的修改操作。
Manifest文件:Manifest文件中记录SST文件在不同Level的分布,单个SST文件的最大最小key,以及其他一些LevelDB需要的元信息。
Current文件: 从上面的介绍可以看出,LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个。Current文件简单的记录了当前Manifest的文件名,从而让这个过程变得非常简单。
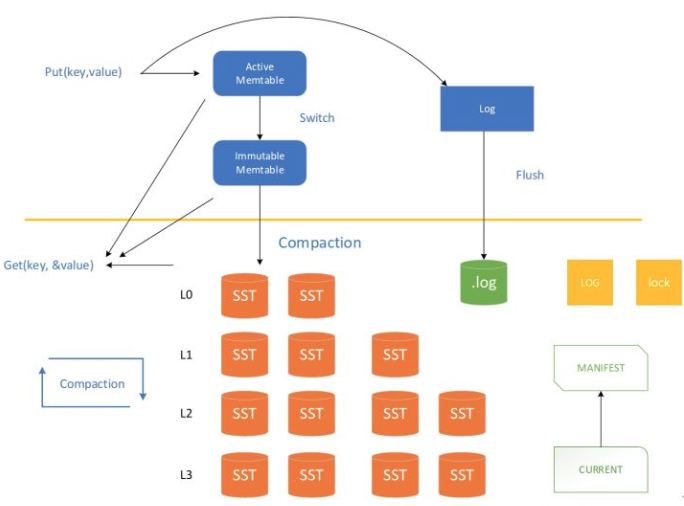
写操作流程
顺序写入磁盘log文件;
写入内存memtable(采用skiplist结构实现);
MemTable 的大小达到设定阈值的时候,转换成 Immutable MemTable。
Immutable Table 由后台线程异步 Flush 到磁盘上,成为 Level0 上的一个 sst 文件。
在某些条件下,会触发后台线程对 Level0 ~ LevelN 的文件进行 Compaction。
读操作流程
在内存中依次查找memtable、immutable memtable;
如果配置了cache,查找cache;
根据mainfest索引文件,在磁盘中查找SST文件;
SSTable文件
SST文件并不是平坦的结构,而是分层组织的,这也是LevelDB名称的来源。
每个SST文件大小上限为2MB,所以,LevelDB通常存储了大量的SST文件;
SST文件由若干个4K大小的blocks组成,block也是读/写操作的最小单元;
SST文件的最后一个block是一个index,指向每个data block的起始位置,以及每个block第一个entry的key值(block内的key有序存储);
使用Bloom filter加速查找,只要扫描index,就可以快速找出所有可能包含指定entry的block。
同一个block内的key可以共享前缀(只存储一次),这样每个key只要存储自己唯一的后缀就行了。如果block中只有部分key需要共享前缀,在这部分key与其它key之间插入"reset"标识。
由log直接读取的entry会写到Level 0的SST中(最多4个文件);
当Level 0的4个文件都存储满了,会选择其中一个文件Compact到Level 1的SST中;
- 注意:Level 0的SSTable文件和其它Level的文件相比有特殊性:这个层级内的.sst文件,两个文件可能存在key重叠,比如有两个level 0的sst文件,文件A和文件B,文件A的key范围是:{bar, car},文件B的Key范围是{blue,samecity},那么很可能两个文件都存在key=”blood”的记录。对于其它Level的SSTable文件来说,则不会出现同一层级内.sst文件的key重叠现象,就是说Level L中任意两个.sst文件,那么可以保证它们的key值是不会重叠的。
Log:最大4MB (可配置), 会写入Level 0;
Level 0:最多4个SST文件,;
Level 1:总大小不超过10MB;
Level 2:总大小不超过100MB;
Level 3+:总大小不超过上一个Level ×10的大小。
比如:0 ↠ 4 SST, 1 ↠ 10M, 2 ↠ 100M, 3 ↠ 1G, 4 ↠ 10G, 5 ↠ 100G, 6 ↠ 1T, 7 ↠ 10T
Compaction操作
对于LevelDb来说,写入记录操作很简单,删除记录仅仅写入一个删除标记就算完事,但是读取记录比较复杂,需要在内存以及各个层级文件中依照新鲜程度依次查找,代价很高。为了加快读取速度,levelDb采取了compaction的方式来对已有的记录进行整理压缩,通过这种方式,来删除掉一些不再有效的KV数据,减小数据规模,减少文件数量等。
LevelDb的compaction机制和过程与Bigtable所讲述的是基本一致的,Bigtable中讲到三种类型的compaction: minor ,major和full:
- minor Compaction,就是把memtable中的数据导出到SSTable文件中;
- major compaction就是合并不同层级的SSTable文件;
- full compaction就是将所有SSTable进行合并;
LevelDb包含其中两种,minor和major。