InfluxDB
InfluxDB在DB-Engines的时序数据库类别里排名第一,实至名归,从它的功能丰富性、易用性以及底层实现来看,都有很多的亮点,值得大篇幅来分析。
首先简单归纳下它的几个比较重要的特性:
- 极简架构:单机版的InfluxDB只需要安装一个binary,即可运行使用,完全没有任何的外部依赖。相比来看几个反面例子,OpenTSDB底层是HBase,拖家带口就得带上ZooKeeper、HDFS等,如果你不熟悉Hadoop技术栈,一般运维起来是有一定的难度,这也是其被人抱怨最多的一个点。KairosDB稍微好点,它依赖Cassandra和ZooKeeper,单机测试可以使用H2。总的来说,依赖一个外部的分布式数据库的TSDB,在架构上会比完全自包含的TSDB复杂一点,毕竟一个成熟的分布式数据库本身就很复杂,当然这一点在云计算这个时代已经完全消除。
- TSM Engine:底层采用自研的TSM存储引擎,TSM也是基于LSM的思想,提供极强的写能力以及高压缩率,在后面的章节会对其做一个比较详细的分析。
- InfluxQL:提供SQL-Like的查询语言,极大的方便了使用,数据库在易用性上演进的终极目标都是提供Query Language。
- Continuous Queries: 通过CQ能够支持auto-rollup和pre-aggregation,对常见的查询操作可以通过CQ来预计算加速查询。
- TimeSeries Index: 对Tags会进行索引,提供高效的检索。这一项功能,对比OpenTSDB和KairosDB等,在Tags检索的效率上提升了不少。OpenTSDB在Tags检索上做了不少的查询优化,但是受限于HBase的功能和数据模型,所以然并卵。不过目前稳定版中的实现采用的是memory-based index的实现方式,这种方案在实现上比较简单,查询上效率最高,但是带来了不少的问题,在下面的章节会详细描述。
- Plugin Support: 支持自定义插件,能够扩展到兼容多种协议,如Graphite、collectd和OpenTSDB。
在下面的章节,会主要对其基本概念、TSM存储引擎、Continuous Queries以及TimeSeries Index做详细的解析。
基本概念
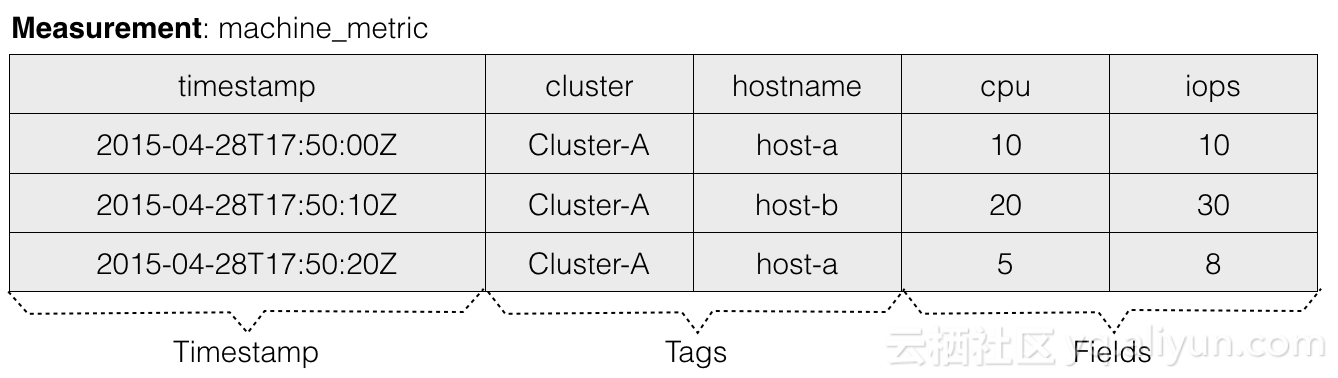
先来了解下InfluxDB中的几个基本概念,看下具体的例子:
| |
上面是一条向InfluxDB中写入一条数据的命令行,来看下这条数据由哪几个部分组成:
- Measurement:Measurement的概念与OpenTSDB的Metric类似,代表数据所属监控指标的名称。例如上述例子是对机器指标的监控,所以其measurement命名为machine_metric。
- Tags:与OpenTSDB的Tags概念类似,用于描述主体的不同的维度,允许存在一个或多个Tag,每个Tag也是由TagKey和TagValue构成。
- Field:在OpenTSDB的逻辑数据模型中,一行metric数据对应一个value。而在InfluxDB中,一行measurement数据可以对应多个value,每个value根据Field来区分。
- Timestamp: 时序数据的必备属性,代表该条数据所属的时间点,可以看到InfluxDB的时间精度能够精确到纳秒。
- TimeSeries:Measurement+Tags的组合,在InfluxDB中被称为TimeSeries。TimeSeries就是时间线,根据时间能够定位到某个时间点,所以TimeSeries+Field+Timestamp能够定位到某个Value。这个概念比较重要,在后续的章节中都会提到。
最终在逻辑上每个Measurement内的数据会组织成一张大的数据表,如下图所示:
在查询时,InfluxDB支持在Measurement内任意维度的条件查询,你可以指定任意某个Tag或者Filed的条件做查询。接着上面的数据案例,你可以构造以下查询条件:
| |
从数据模型以及查询的条件上看,Tag和Field没有任何区别。从语义上来看,Tag用于描述Measurement,而Field用于描述Value。从内部实现来上看,Tag会被全索引,而Filed不会,所以根据Tag来进行条件查询会比根据Filed来查询效率高很多。
TSM
InfluxDB底层的存储引擎经历了从LevelDB到BlotDB,再到选择自研TSM的过程,整个选择转变的思考可以在其官网文档里看到。整个思考过程很值得借鉴,对技术选型和转变的思考总是比平白的描述某个产品特性让人印象深刻的多。
我简单总结下它的整个存储引擎选型转变的过程,第一阶段是LevelDB,选型LevelDB的主要原因是其底层数据结构采用LSM,对写入很友好,能够提供很高的写入吞吐量,比较符合时序数据的特性。在LevelDB内,数据是采用KeyValue的方式存储且按Key排序,InfluxDB使用的Key设计是SeriesKey+Timestamp的组合,所以相同SeriesKey的数据是按timestamp来排序存储的,能够提供很高效的按时间范围的扫描。
不过使用LevelDB的一个最大的问题是,InfluxDB支持历史数据自动删除(Retention Policy),在时序数据场景下数据自动删除通常是大块的连续时间段的历史数据删除。LevelDB不支持Range delete也不支持TTL,所以要删除只能是一个一个key的删除,会造成大量的删除流量压力,且在LSM这种数据结构下,真正的物理删除不是即时的,在compaction时才会生效。各类TSDB实现数据删除的做法大致分为两类:
- 数据分区:按不同的时间范围划分为不同的分区(Shard),因为时序数据写入都是按时间线性产生的,所以分区的产生也是按时间线性增长的,写入通常是在最新的分区,而不会散列到多个分区。分区的优点是数据回收的物理删除非常简单,直接把整个分区删除即可。缺点是数据回收的精细度比较大,为整个分区,而回收的时间精度取决于分区的时间跨度。分区的实现可以是在应用层提供,也可以是存储引擎层提供,例如可以利用RocksDB的column family来作为数据分区。InfluxDB采用这种模式,默认的Retention Policy下数据会以7天时间跨度组成为一个分区。
- TTL:底层数据引擎直接提供数据自动过期的功能,可以为每条数据设定存储时间(time to live),当数据存活时间到达后存储引擎会自动对数据进行物理删除。这种方式的优点是数据回收的精细度很高,精细到秒级及行级的数据回收。缺点是LSM的实现上,物理删除发生在compaction的时候,比较不及时。RocksDB、HBase、Cassandra和阿里云表格存储都提供数据TTL的功能。
InfluxDB采用的是第一种策略,会按7天一个周期,将数据分为多个不同的Shard,每个Shard都是一个独立的数据库实例。随着运行时间的增长,shard的个数会越来越多。而由于每个shard都是一个独立的数据库实例,底层都是一套独立的LevelDB存储引擎,这时带来的问题是,每个存储引擎都会打开比较多的文件,随着shard的增多,最终进程打开的文件句柄会很快触及到上限。LevelDB底层采用level compaction策略,是文件数多的原因之一。实际上level compaction策略不适合时序数据这种写入模式,这点原因InfluxDB没有提及。
由于遇到大量的客户反馈文件句柄过多的问题,InfluxDB在新版本的存储引擎选型中选择了BoltDB替换LevelDB。BoltDB底层数据结构是mmap B+树,其给出的选型理由是:1.与LevelDB相同语义的API;2.纯Go实现,便于集成和跨平台;3.单个数据库只使用一个文件,解决了文件句柄消耗过多的问题,这条是他们选型BoltDB的最主要理由。但是BoltDB的B+树结构与LSM相比,在写入能力上是一个弱势,B+树会产生大量的随机写。所以InfluxDB在使用BoltDB之后,很快遇到了IOPS的问题,当数据库大小达到几个GB后,会经常遇到IOPS的瓶颈,极大影响写入能力。虽然InfluxDB后续也采用了一些写入优化措施,例如在BoltDB之前加了一层WAL,数据写入先写WAL,WAL能保证数据是顺序写盘,但是最终写入BoltDB还是会带来比较大的IOPS资源消耗。
InfluxDB在经历了几个小版本的BoltDB后,最终决定自研TSM,TSM的设计目标一是解决LevelDB的文件句柄过多问题,二是解决BoltDB的写入性能问题。TSM全称是Time-Structured Merge Tree,思想类似LSM,不过是基于时序数据的特性做了一些特殊的优化。来看下TSM的一些重要组件:
Write Ahead Log(WAL) : 数据会先写入WAL,后进入memory-index和cache,写入WAL会同步刷盘,保证数据持久化。Cache内数据会异步刷入TSM File,在Cache内数据未持久化到TSM File之前若遇到进程crash,则会通过WAL内的数据来恢复cache内的数据,这个行为与LSM是完全类似的。
Cache: TSM的Cache与LSM的MemoryTable类似,其内部的数据为WAL中未持久化到TSM File的数据。若进程发生failover,则cache中的数据会根据WAL中的数据进行重建。Cache内数据保存在一个SortedMap中,Map的Key为TimeSeries+Timestamp的组成。所以可以看到,在内存中数据是按TimeSeries组织的,TimeSeries中的数据按时间顺序存放。
TSM Files: TSM File与LSM的SSTable类似,TSM File由四个部分组成,分别为:header, blocks, index和footer。其中最重要的部分是blocks和index:
Block:每个block内存储的是某个TimeSeries的一段时间范围内的值,即某个时间段下某个measurement的某组tag set对应的某个field的所有值,Block内部会根据field的不同的值的类型采取不同的压缩策略,以达到最优的压缩效率。
Index:文件内的索引信息保存了每个TimeSeries下所有的数据Block的位置信息,索引数据按TimeSeries的Key的字典序排序。在内存中不会把完整的index数据加载进去,这样会很大,而是只对部分Key做索引,称之为indirectIndex。indirectIndex中会有一些辅助定位的信息,例如该文件中的最小最大时间以及最小最大Key等,最重要的是保存了部分Key以及其Index数据的文件offset信息。若想要定位某个TimeSeries的Index数据,会先根据内存中的部分Key信息找到与其最相近的Index Offset,之后从该起点开始顺序扫描文件内容再精确定位到该Key的Index数据位置。
Compaction: compaction是一个将write-optimized的数据存储格式优化为read-optimized的数据存储格式的一个过程,是LSM结构存储引擎做存储和查询优化很重要的一个功能,compaction的策略和算法的优劣决定了存储引擎的质量。在时序数据的场景下,基本很少发生update或者delete,数据都是按时间顺序生成的,所以基本不会有overlap,Compaction起到的作用主要在于压缩和索引优化。
LevelCompaction: InfluxDB将TSM文件分为4个层级(Level 1-4),compaction只会发生在同层级文件内,同层级的文件compaction后会晋升到下一层级。从这个规则看,根据时序数据的产生特性,level越高数据生成时间越旧,访问热度越低。由Cache数据初次生成的TSM文件称为Snapshot,多个Snapshot文件compaction后产生Level1的TSM文件,Level1的文件compaction后生成level2的文件,依次类推。低Level和高Level的compaction会采用不同的算法,低level文件的compaction采用低CPU消耗的做法,例如不会做解压缩和block合并,而高level文件的compaction则会做block解压缩以及block合并,以进一步提高压缩率。我理解这种设计是一种权衡,compaction通常在后台工作,为了不影响实时的数据写入,对compaction消耗的资源是有严格的控制,资源受限的情况下必然会影响compaction的速度。而level越低的数据越新,热度也越高,需要有一种更快的加速查询的compaction,所以InfluxDB在低level采用低资源消耗的compaction策略,这完全是贴合时序数据的写入和查询特性来设计的。
IndexOptimizationCompaction: 当Level4的文件积攒到一定个数后,index会变得很大,查询效率会变的比较低。影响查询效率低的因素主要在于同一个TimeSeries数据会被多个TSM文件所包含,所以查询不可避免的需要跨多个文件进行数据整合。所以IndexOptimizationCompaction的主要作用就是将同一TimeSeries下的数据合并到同一个TSM文件中,尽量减少不同TSM文件间的TimeSeries重合度。
FullCompaction: InfluxDB在判断某个Shard长时间内不会再有数据写入之后,会对数据做一次FullCompaction。FullCompaction是LevelCompaction和IndexOptimization的整合,在做完一次FullCompaction之后,这个Shard不会再做任何的compaction,除非有新的数据写入或者删除发生。这个策略是对冷数据的一个规整,主要目的在于提高压缩率。
Continuous Queries
对InfluxDB内的数据做预聚合和降精度有两种推荐的策略,一种是使用InfluxData内的数据计算引擎Kapacitor,另一种是使用InfluxDB自带的Continuous Queries。
| |
如上是一个简单的配置Continuous Queries的CQL,所起的作用是能够让InfluxDB启动一个定时任务,每隔5分钟将『machine_metric』这个measurement下的所有数据按cluster+hostname这个维度进行聚合,计算cpu这个Field的平均值,最终结果写入average_machine_cpu_5m这个新的measurement内。
InfluxDB的Continuous Queries与KairosDB的auto-rollup功能类似,都是单节点调度,数据的聚合是滞后而非实时的流计算,在计算时对存储会产生较大的读压力。
TimeSeries Index
时序数据库除了支撑时序数据的存储和计算外,还需要能够提供多维度查询。InfluxDB为了提供更快速的多维查询,对TimeSeries进行了索引。关于数据和索引,InfluxDB是这么描述自己的:
| |
在InfluxDB 1.3之前,TimeSeries Index(下面简称为TSI)只支持Memory-based的方式,即所有的TimeSeries的索引都是放在内存内,这种方式有好处但是也会带来很多的问题。而在最新发布的InfluxDB 1.3版本上,提供了另外一种方式的索引可供选择,新的索引方式会把索引存储在磁盘上,效率上相比内存索引差一点,但是解决了内存索引存在的不少问题。
Memory-based Index
| |
如上是InfluxDB 1.3的源码中对内存索引数据结构的定义,主要有两个重要的数据结构体:
Series: 对应某个TimeSeries,其内存储TimeSeries相关的一些基本属性以及它所属的Shard
- Key:对应measurement + tags序列化后的字符串。
- tags: 该TimeSeries下所有的TagKey和TagValue
- ID: 用于唯一区分的整数ID。
- measurement: 所属的measurement。
- shardIDs: 所有包含该Series的ShardID列表。
Measurement: 每个measurement在内存中都会对应一个Measurement结构,其内部主要是一些索引来加速查询。
- seriesByID:通过SeriesID查询Series的一个Map。
- seriesByTagKeyValue:双层Map,第一层是TagKey对应其所有的TagValue,第二层是TagValue对应的所有Series的ID。可以看到,当TimeSeries的基数变得很大,这个map所占的内存会相当多。
- sortedSeriesIDs:一个排序的SeriesID列表。
全内存索引结构带来的好处是能够提供非常高效的多维查询,但是相应的也会存在一些问题:
- 能够支持的TimeSeries基数有限,主要受限于内存的大小。若TimeSeries个数超过上限,则整个数据库会处于不可服务的状态。这类问题一般由用户错误的设计TagKey引发,例如某个TagKey是一个随机的ID。一旦遇到这个问题的话,也很难恢复,往往只能通过手动删数据。
- 若进程重启,恢复数据的时间会比较长,因为需要从所有的TSM文件中加载全量的TimeSeries信息来在内存中构建索引。
Disk-based Index
针对全内存索引存在的这些问题,InfluxDB在最新的1.3版本中提供了另外一种索引的实现。得益于代码设计上良好的扩展性,索引模块和存储引擎模块都是插件化的,用户可以在配置中自由选择使用哪种索引。

InfluxDB实现了一个特殊的存储引擎来做索引数据的存储,其结构也与LSM类似,如上图就是一个Disk-based Index的结构图,详细的说明可以参见设计文档。
索引数据会先写入Write-Ahead-Log,WAL中的数据按LogEntry组织,每个LogEntry对应一个TimeSeries,包含Measurement、Tags以及checksum信息。写入WAL成功后,数据会进入一个内存索引结构内。当WAL积攒到一定大小后,LogFile会Flush成IndexFile。IndexFile的逻辑结构与内存索引的结构一致,表示的也是Measurement到TagKey,TagKey到TagValue,TagValue到TimeSeries的Map结构。InfluxDB会使用mmap来访问文件,同时文件中对每个Map都会保存HashIndex来加速查询。
当IndexFile积攒到一定数量后,InfluxDB也提供compaction的机制,将多个IndexFile合并为一个,节省存储空间以及加速查询。
总结
InfluxDB内所有的组件全部采取自研,自研的好处是每个组件都可以贴合时序数据的特性来做设计,将性能发挥到极致。整个社区也是非常活跃,但是动不动就会有一次大的功能升级,例如改个存储格式换个索引实现啥的,对于用户来说就比较折腾了。总的来说,我还是比较看好InfluxDB的发展,不过可惜的是集群版没有开源。