Apache Hudi
简介
Hudi,全称是Hadoop Upsert Delete and Incremental, 最初的设计目标:在hadoop上实现update和delete操作;
Hudi通过
COW和MOR两种方式在只能overwrite的文件系统上实现update操作;
COW表
- cow, copy on write,COW表写的时候数据直接写入basefile,(parquet)不写log文件;
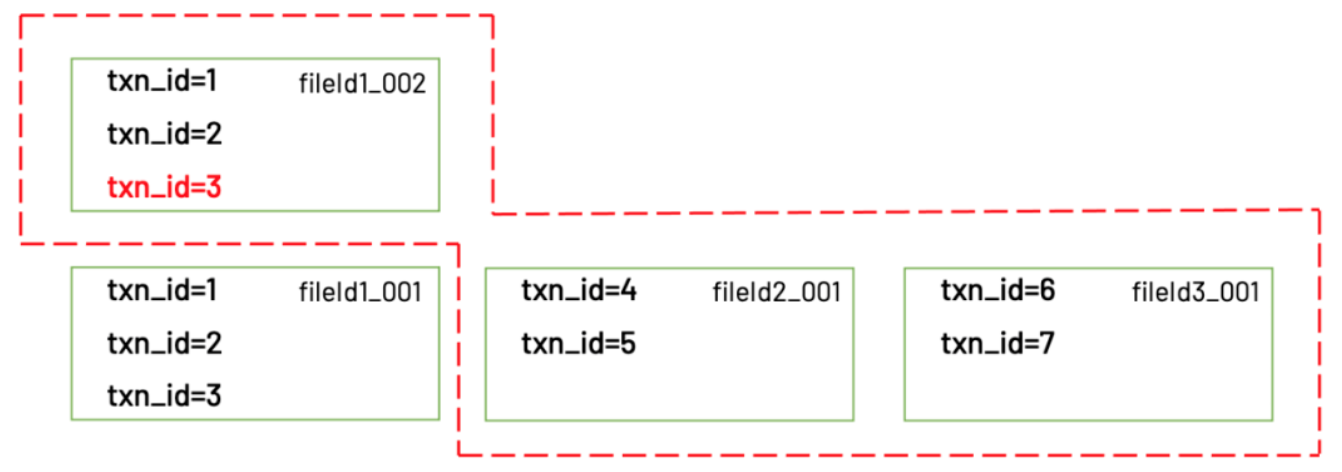
Upsert的过程整体分为3步(这里省略了很多不太重要的步骤):
根据partitionPath进行重新分区。
根据recordKey确定哪些记录需要插入,哪些记录需要更新。对于需要更新的记录,还需要找到旧的记录所在的文件。(这个过程被称为tagging)
把记录写入实际的文件。
MOR表
merge on read,MOR表写数据时,记录首先会被快速的写进日志文件,稍后会使用时间轴上的压缩操作将其与基础文件合并。
MOR表在更新时只会把更新的那部分数据写入一个.log文件;
因为.log文件不包含老数据,也不涉及tagging,又是顺序写入的,所以写入会非常快。而当客户端要读取数据时,会有两种选择:
读取时动态地把.log文件和原始数据文件(称为base文件)进行merge
异步地把.log文件和base文件merge,如果merge还没完成,只能读到上个版本的数据;
Index
在upsert的工作原理中,我们提到了tagging过程中需要使用index确定每一条数据之前是否已经插入过, 这3种index分别是:Bloom Index,Simple Index和HBase Index。
Bloom Index:实现原理是bloom filter。优点是效率高,缺点是bloom filter固有的假阳性问题,所以Hudi对bloom filter里存在的key,还需要回溯原文件再查找一遍。Hudi默认使用的是Bloom Index。
Simple Index:实现原理是把新数据和老数据进行join。优点是实现最简单,无需额外的资源。缺点是性能比较差。
HBase Index:实现原理是把index存放在HBase里面。优点是性能最高,缺点是需要外部的系统,增加了运维压力。
查询
鉴于这种灵活而全面的数据布局和丰富的时间线,Hudi能够支持三种不同的查询表方式,具体取决于表的类型。
| 查询类型 | COW | MOR |
|---|---|---|
| 快照查询 | 查询在给定表或表分区中所有文件片中的最新基本文件上执行,将查看到最新提交的记录。 | 通过并到给定表或表分区中的所有文件切片中最新的基本文件及其日志文件合来执行查询,将看到最新的delta-commit操作写入的的记录。 |
| 增量查询 | 在给定的开始,结束即时时间范围内,对最新的基本文件执行查询(称为增量查询窗口),同时仅使用Hudi指定的列提取在此窗口中写入的记录。 | 查询是在增量查询窗口中对最新的文件片执行的,具体取决于窗口本身,读取基本块或日志块中读取记录的组合。 |
| 读优化查询 | 和快照查询相同 | 仅访问基本文件,提供给定文件片自上次执行压缩操作以来的数据。通常查询数据的最新程度的保证取决于压缩策略 |
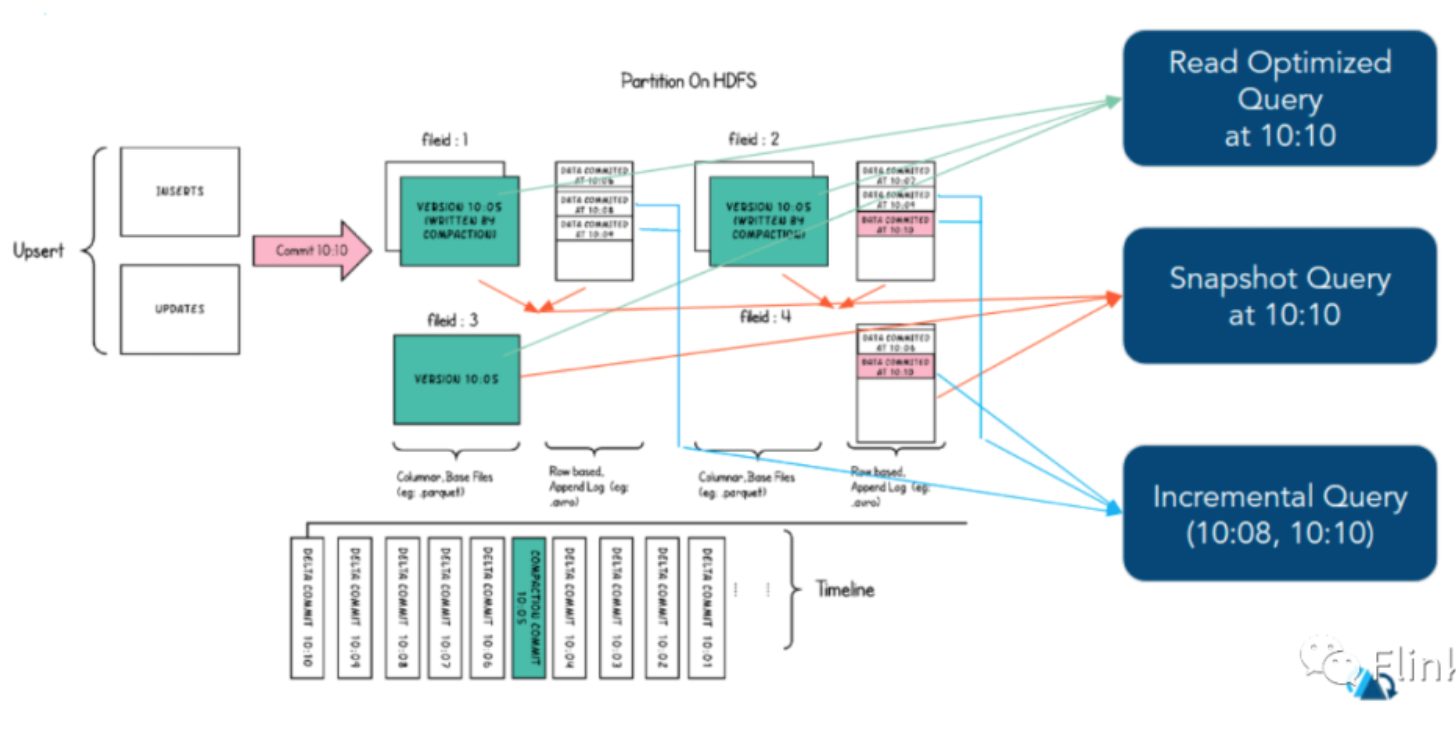
读优化查询
可查看给定的commit/compact即时操作的表的最新快照。仅将最新文件片的基本/列文件暴露给查询,并保证与非Hudi表相同的列查询性能。
| 指标 | 读优化查询 | 快照查询 |
|---|---|---|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |