Hive
简介
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
特性
Hive 的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。
Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 Hive 是读模式(Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义格式等
只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
Hive 的默认列分隔符:控制符 Ctrl + A,\x01
Hive 的默认行分隔符:换行符 \n
Hive 中包含以下数据模型:
database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在 HDFS 中表现所属 database 目录下一个文件夹
external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
partition:在 HDFS 中表现为 table 目录下的子目录
bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件
view:与传统数据库类似,只读,基于基本表创建
Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
内部表和外部表的区别:
删除内部表,删除表元数据和数据
删除外部表,删除元数据,不删除数据
架构
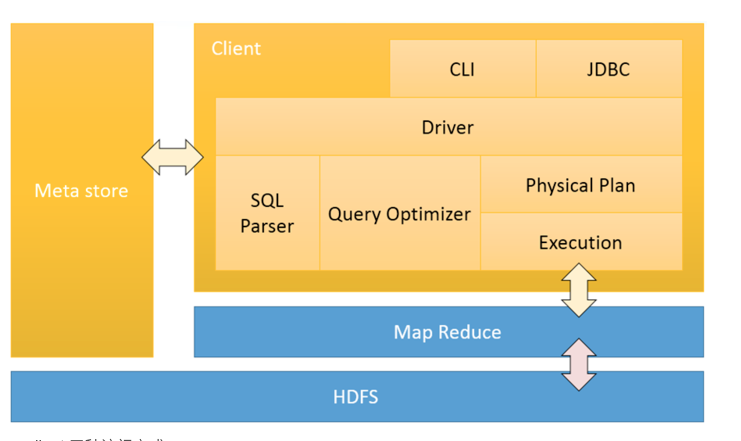
服务端
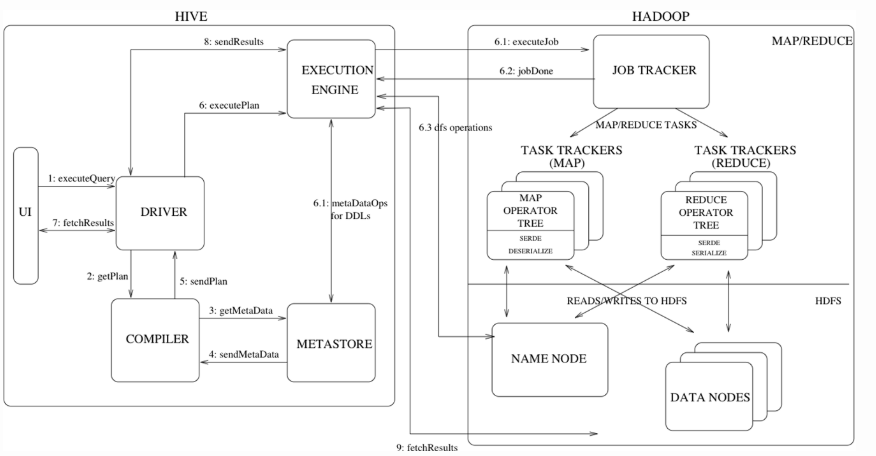
- Driver:包含Complier, Optimizer, Executor。作用是将HiveQL进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
- Metastore:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性。
- Thrift服务:提供rpc接口服务。
客户端
CLI:command line interface,命令行接口。
Thrift客户端:上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
WEBGUI:hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。
执行流程
部署
依赖
- jdk
- hadoop
- mysql
- hive
组件
- metastore: 元数据存储服务
- hive:hive 命令行接口工具;
- Hiveserver2:hive thrift server
- beeline:hive thrift client
- HCatalog:
- WebHCat
Core-site.xml
| |
metastore
内嵌模式:
hive-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:;databaseName=metastore_db;create=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.apache.derby.jdbc.EmbeddedDriver</value> </property> <property> <name>hive.metastore.local</name> <value>true</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> </configuration>本地模式:
远程模式:
启动
| |
CLI实例操作
| |
| |
hive on spark
- 配置文件
$HIVE_HOME/conf/hive-site.xml
| |
$HIVE_HOME/conf/spark-defaults.conf
| |
| |
hive for hbase
Hive中执行如下操作
| |
- 原理
Hive与HBase利用两者本身对外的API来实现整合,主要是靠HBaseStorageHandler进行通信,利用 HBaseStorageHandler,Hive可以获取到Hive表对应的HBase表名,列簇以及列,InputFormat和 OutputFormat类,创建和删除HBase表等。 Hive访问HBase中表数据,实质上是通过MapReduce读取HBase表数据,其实现是在MR中,使用HiveHBaseTableInputFormat完成对HBase表的切分,获取RecordReader对象来读取数据。 对HBase表的切分原则是一个Region切分成一个Split,即表中有多少个Regions,MR中就有多少个Map; 读取HBase表数据都是通过构建Scanner,对表进行全表扫描,如果有过滤条件,则转化为Filter。当过滤条件为rowkey时,则转化为对rowkey的过滤; Scanner通过RPC调用RegionServer的next()来获取数据;