在 HBase 中,split 其实是进行 sharding 的一种技术手段,通过 HBase 的 split 条件和 split 策略,将 region 进行合理的 split,再通过 HBase 的 balance 策略,将分裂的 region 负载均衡到各个 regionserver 上,最大化的发挥分布式系统的优点。HBase 这种自动的 sharding 技术比传统的数据库 sharding 要省事的多,减轻了维护的成本,但是这样也会给 HBase 带来额外的 IO 开销,因此在很多系统中如果能很好的预计 rowkey 的分布和数据增长情况,可以通过预先分区,事先将 region 分配好,再将 HBase 的自动分区禁掉。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| private boolean flushRegion(final Region region, final boolean emergencyFlush,
boolean forceFlushAllStores) {
synchronized (this.regionsInQueue) {
FlushRegionEntry fqe = this.regionsInQueue.remove(region);
// Use the start time of the FlushRegionEntry if available
if (fqe != null && emergencyFlush) {
// Need to remove from region from delay queue. When NOT an
// emergencyFlush, then item was removed via a flushQueue.poll.
flushQueue.remove(fqe);
}
}
lock.readLock().lock();
try {
notifyFlushRequest(region, emergencyFlush);
FlushResult flushResult = region.flush(forceFlushAllStores);
boolean shouldCompact = flushResult.isCompactionNeeded();
// We just want to check the size
boolean shouldSplit = ((HRegion)region).checkSplit() != null;
if (shouldSplit) {
this.server.compactSplitThread.requestSplit(region);
} else if (shouldCompact) {
server.compactSplitThread.requestSystemCompaction(
region, Thread.currentThread().getName());
}
} catch (DroppedSnapshotException ex) {
|
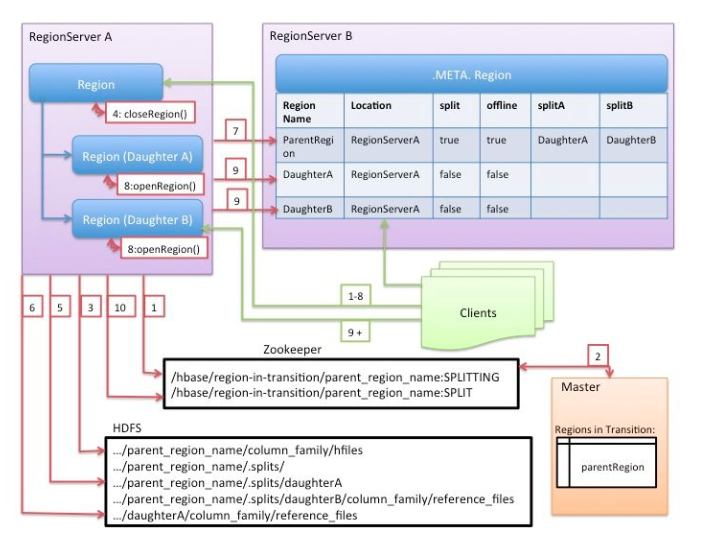
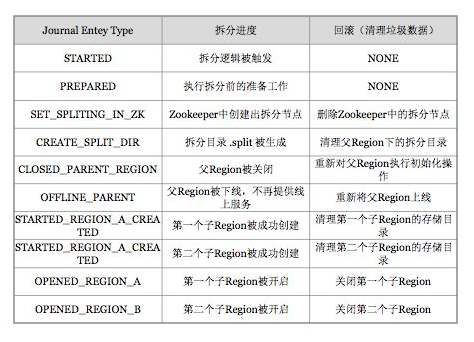
HBase 将整个切分过程包装成了一个事务,意图能够保证切分事务的原子性。整个分裂事务过程分为三个阶段:prepare – execute – (rollback) ,操作模版如下:
在内存中初始化两个子 region,具体是生成两个 HRegionInfo 对象,包含 tableName、regionName、startkey、endkey 等。同时会生成一个 transaction journal,这个对象用来记录切分的进展,具体见 rollback 阶段。
regionserver 更改 ZK 节点 /region-in-transition 中该 region 的状态为 SPLITING。
master 通过 watch 节点/region-in-transition 检测到 region 状态改变,并修改内存中 region 的状态,在 master 页面 RIT 模块就可以看到 region 执行 split 的状态信息。
在父存储目录下新建临时文件夹.split 保存 split 后的 daughter region 信息。
关闭 parent region:parent region 关闭数据写入并触发 flush 操作,将写入 region 的数据全部持久化到磁盘。此后短时间内客户端落在父 region 上的请求都会抛出异常 NotServingRegionException。
核心分裂步骤:在.split 文件夹下新建两个子文件夹,称之为 daughter A、daughter B,并在文件夹中生成 reference 文件,分别指向父 region 中对应文件。这个步骤是所有步骤中最核心的一个环节,生成 reference 文件日志如下所示:

父 region 分裂为两个子 region 后,将 daughter A、daughter B 拷贝到 HBase 根目录下,形成两个新的 region。
父 region 通知修改 hbase.meta 表后下线,不再提供服务。下线后 parent region 在 meta 表中的信息并不会马上删除,而是标注 split 列、offline 列为 true,并记录两个子 region
开启 daughter A、daughter B 两个子 region。通知修改 hbase.meta 表,正式对外提供服务。
您可以使用自定义 RegionSplitPolicy(HBase 0.94+)重写默认拆分策略。通常,自定义拆分策略应该扩展 HBase 的默认拆分策略: IncreasingToUpperBoundRegionSplitPolicy。
该策略可以通过 HBase 配置或者也可以基于每个表在全局范围内进行设置。
在 hbase-site.xml 中全局配置拆分策略:
1
2
3
4
| <property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>
|
使用 Java API 在表上配置拆分策略:
1
2
3
4
5
| HTableDescriptor tableDesc = new HTableDescriptor("test");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, ConstantSizeRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("cf1")));
admin.createTable(tableDesc);
----
|
使用 HBase Shell 在表上配置拆分策略:
1
| hbase> create 'test', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy', }},{NAME => 'cf1'}
|
该策略可以通过使用的 HBaseConfiguration 或按表进行全局设置:
1
2
| HTableDescriptor myHtd = ...;
myHtd.setValue(HTableDescriptor.SPLIT_POLICY, MyCustomSplitPolicy.class.getName());
|
该DisabledRegionSplitPolicy策略阻止手动区域拆分。
在线修改 split 策略
1
2
| hbase> t="test_66_snappy5"
hbase> disable t; alter t, {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy', 'MAX_FILESIZE' => 214748364800 }} ; enable t
|
- https://zhuanlan.zhihu.com/p/39648692
- https://cloud.tencent.com/developer/article/1005586
- HBase 原理–所有 Region 切分的细节都在这里了 - 简书
- https://andr-robot.github.io/HBase%E4%B8%ADRegion%E7%9A%84%E5%88%87%E5%88%86/
- Hbase Split 解析_大数据_Kuzury-CSDN 博客