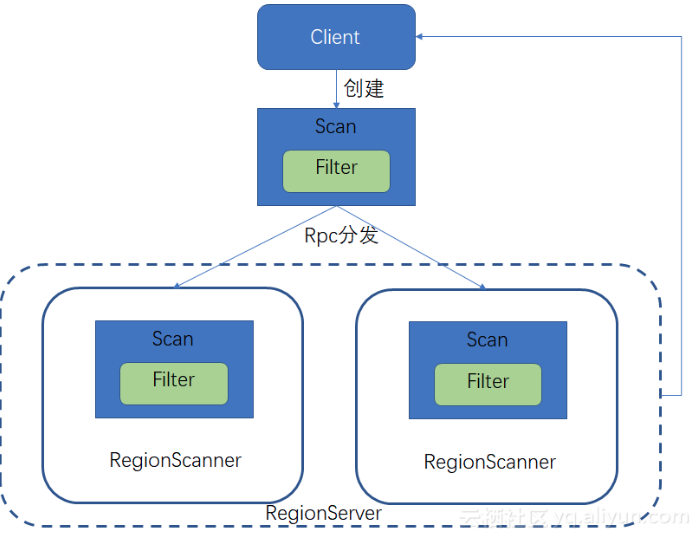
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| scan 'blog', FILTER => org.apache.hadoop.hbase.filter.FuzzyRowFilter.new(Arrays.asList(Pair.new(Bytes.toBytes("00?"),Bytes.toBytes("\x00\x00\x01"))))
scan "journalq:send_log", {LIMIT=>10, STARTROW=> "\x00\x00\x00\x08\x00\x00\x01j\xC16=\x98\x03E\xD2\x02\xE1", STOPROW=>"\x00\x00\x00\x08\x00\x00\x01j\xDA\x9F\x85\x17\xF7\xBDbr" }
scan "journalq:send_log", {STARTROW=> "\x00\x00\x00\x08\x00\x00\x01j\xC16=\x98\x03E\xD2\x02\xE1", STOPROW=>"\x00\x00\x00\x14\x00\x00\x01l=.\xFB\xAF\xD4\x1D\x8C\xD9\x8F\x00\xB2\x04\xE9\x80\x09\x98\xEC\xF8B~7D\xD7\xF4s\xB1\x80\xB1V\xA1\xB3\xA2\xDE\x9F\xDE\x9A", FILTER=>org.apache.hadoop.hbase.filter.FuzzyRowFilter.new(Arrays.asList(Pair.new(Bytes.toBytes("0008????????0000000000000000????????????????"),Bytes.toBytes("\x00\x00\x00\x01\x01\x01\x01\x01\x01\x01\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01")))) }
scan "journalq:send_log", {STARTROW=> "\x00\x00\x00\x08\x00\x00\x01j\xC16=\x98\x03E\xD2\x02\xE1", STOPROW=>"\x00\x00\x00\x14\x00\x00\x01l=.\xFB\xAF\xD4\x1D\x8C\xD9\x8F\x00\xB2\x04\xE9\x80\x09\x98\xEC\xF8B~7D\xD7\xF4s\xB1\x80\xB1V\xA1\xB3\xA2\xDE\x9F\xDE\x9A", FILTER=>org.apache.hadoop.hbase.filter.FuzzyRowFilter.new(Arrays.asList(Pair.new(Bytes.toBytes("0008????????0000000000000000????????????????"),Bytes.toBytes("\x00\x00\x00\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01\x01")))) }
scan "journalq:send_log", {STARTROW=> "\x00\x00\x00\x08\x00\x00\x01j\xC16=\x98\x03E\xD2\x02\xE1", STOPROW=>"\x00\x00\x00\x14\x00\x00\x01l=.\xFB\xAF\xD4\x1D\x8C\xD9\x8F\x00\xB2\x04\xE9\x80\x09\x98\xEC\xF8B~7D\xD7\xF4s\xB1\x80\xB1V\xA1\xB3\xA2\xDE\x9F\xDE\x9A", FILTER=>org.apache.hadoop.hbase.filter.FuzzyRowFilter.new(Arrays.asList(Pair.new(Bytes.toBytes("0000"),Bytes.toBytes("\x01\x01\x01\x01")))), LIMIT=> 10 }
scan "journalq:send_log", {STARTROW=> "\x00\x00\x00\x13\x00\x00\x01", FILTER=>org.apache.hadoop.hbase.filter.FuzzyRowFilter.new(Arrays.asList(Pair.new(Bytes.toBytes("0000"),Bytes.toBytes("\x01\x01\x01\x01")))), LIMIT=> 1000 }
scan "journalq:send_log", {STARTROW=> "\x00\x00\x00\x08\x00\x00\x01j\xC16=\x98\x03E\xD2\x02\xE1", STOPROW=>"\x00\x00\x00\x14\x00\x00\x01l=.\xFB\xAF\xD4\x1D\x8C\xD9\x8F\x00\xB2\x04\xE9\x80\x09\x98\xEC\xF8B~7D\xD7\xF4s\xB1\x80\xB1V\xA1\xB3\xA2\xDE\x9F\xDE\x9A", LIMIT=>10 }
scan "journalq:send_log", {STARTROW=> "\x00\x00\x00\x02\x00\x00\x01k\x0C\x168\x92\xD4\x1D\x8C\xD9\x8F\x00\xB2\x04\xE9\x80\x09\x98\xEC\xF8B~\xC2\x8Fl-\xD3\x04\xB5F(\x9F\x89\xED\x13\xDD\xE5!", STOPROW=>"\x00\x00\x00\x8D\x00\x00\x01l#]\xAF)", LIMIT=>10 }
scan "journalq:send_log", {STARTROW=> "\x00\x00\x00\x02\x00\x00\x01k\x0C\x168\x92\xD4\x1D\x8C\xD9\x8F\x00\xB2\x04\xE9\x80\x09\x98\xEC\xF8B~\xC2\x8Fl-\xD3\x04\xB5F(\x9F\x89\xED\x13\xDD\xE5!", STOPROW=>"\x00\x00\x00\x8D\x00\x00\x01l#]\xAF)", FILTER=>org.apache.hadoop.hbase.filter.FuzzyRowFilter.new(Arrays.asList(Pair.new(Bytes.toBytes("0008????0000????0000????"),Bytes.toBytes("\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00")))) }
scan "journalq:send_log", {FILTER=>"SingleColumnValueFilter('cf','create_time',=,'regexstring:2014-11-08.*')"}
|