HBase Compaction分析
compact 流程
compact 触发条件
memstore flush:
memstore flush会产生HFile文件,文件越来越多就需要compact。因此在每次执行完Flush操作之后,都会对当前Store中的文件数进行判断,一旦store 中的HFile文件数 - 正在compacting的文件数 > minFilesToCompact,就会触发compaction。默认:“hbase.hstore.compaction.min” 为:3。
1 2 3 4 5 6 7 8 9 10 11boolean needsCompaction = flush.commit(status); if (needsCompaction) { compactionRequested = true; } public boolean needsCompaction(Collection<HStoreFile> storeFiles, List<HStoreFile> filesCompacting) { int numCandidates = storeFiles.size() - filesCompacting.size(); return numCandidates >= comConf.getMinFilesToCompact(); } minFilesToCompact = Math.max(2, conf.getInt("hbase.hstore.compaction.min"));周期检查:(CompactionChecker)
后台线程CompactionChecker定期触发检查是否需要执行compaction,检查周期为:hbase.server.thread.wakefrequency*hbase.server.compactchecker.interval.multiplier。默认为10000 * 1000 ms,就是2个多小时。
1 2 3 4 5 6 7 8 9 10long multiplier = s.getCompactionCheckMultiplier(); assert multiplier > 0; if (iteration % multiplier != 0) { continue; } if (s.needsCompaction()) { // Queue a compaction. Will recognize if major is needed. this.instance.compactSplitThread.requestSystemCompaction(hr, s, getName() + " requests compaction"); }手动触发:
一般来讲,手动触发compaction通常是为了执行major compaction,原因有三,
其一是因为很多业务担心自动major compaction影响读写性能,因此会选择低峰期手动触发;
其二也有可能是用户在执行完alter操作之后希望立刻生效,执行手动触发major compaction;
其三是HBase管理员发现硬盘容量不够的情况下手动触发major compaction删除大量过期数据;
无论哪种触发动机,一旦手动触发,HBase会不做很多自动化检查,直接执行合并。
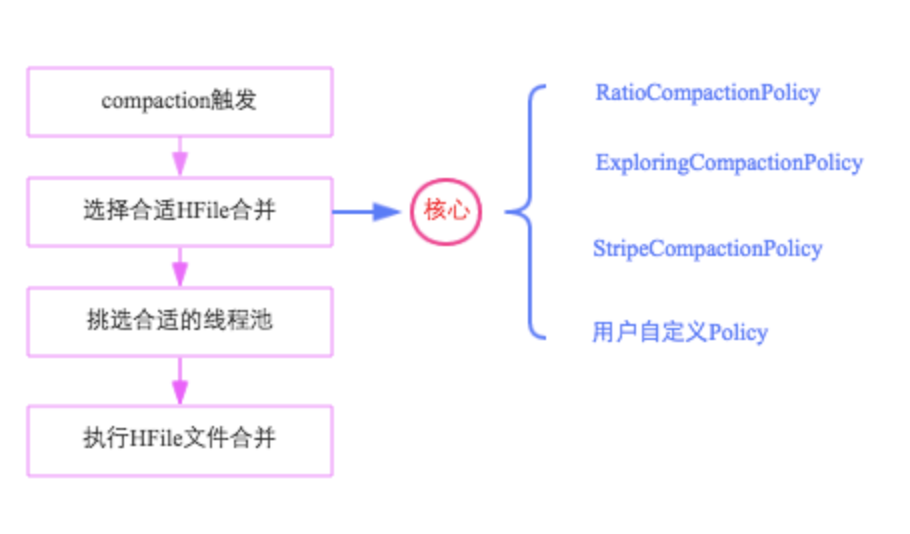
compact 文件选择策略
选择合适的文件进行合并是整个compaction的核心,因为合并文件的大小以及其当前承载的IO数直接决定了compaction的效果。最理想的情况是,这些文件承载了大量IO请求但是大小很小,这样compaction本身不会消耗太多IO,而且合并完成之后对读的性能会有显著提升。然而现实情况可能大部分都不会是这样。都会首先对该Store中所有HFile进行一一排查,排除不满足条件的部分文件:
排除当前正在执行compact的文件及其比这些文件更新的所有文件(SequenceId更大)
排除某些过大的单个文件,如果文件大小大于hbase.hzstore.compaction.max.size(默认Long最大值),则被排除,否则会产生大量IO消耗
经过排除的文件称为候选文件。

文件现在策略有:
- RatioBasedCompactionPolicy:从最旧文件开始遍历到最新候选文件,找到小于[hbase.hstore.compaction.min.size(默认为memstore的flush大小,128M)和compact文件总大小*ratio 的最大值]的符合条件文件,如果发现不符合则马上停止搜索。ratio是一个可变的比例,可以通过设置高峰期的时间来改变这个比例,在高峰期时ratio为1.2,非高峰期为5,也就是非高峰期允许compact更大的文件(非高峰期可以耗费更大IO)。 目的是尽可能找到小文件进行minor compact。如果判断这个compact操作后文件数仍然过多会阻塞flush操作,则只是简单选择从最老的文件起,候选文件数减去hbase.hstore.compaction.min(默认3)个文件。
- ExploringCompactionPolicy:从最旧文件开始遍历所有的候选文件,找出符合[compact文件大小 小于 hbase.hstore.compaction.max.size(默认Long最大值)且所有文件的大小都不会超过其它文件大小*ratio]并且效率最高[compact文件数最多或compact大小最小]。ratio是高峰期比例。注意,由于存在限制,因此可能候选文件被排除到为0个,这时如果判断这个compact操作后文件数仍然过多会阻塞flush操作,则会选择hbase.hstore.compaction.min(默认3)个文件起,符合最大(Long最大值)最小compact大小(128MB)的总大小最小的一个子集合。
minor compact和 major compact
minor compact:将store 中 相邻的 flie 合并为一个大的 file,只用来做部分文件的合并操作以及包括minVersion=0并且设置ttl的过期版本清理,不做任何删除数据、多版本数据的清理工作。
major compact:对Region下的HStore下的所有StoreFile执行合并操作,会做删除数据,多版本数据清理工作,最终的结果是整理合并出一个文件。
major compaction的判断条件如下(满足任意一个):
用户强制执行major compaction;
长时间没有进行compact(CompactionChecker的判断条件2)且候选文件数小于hbase.hstore.compaction.max(默认10)
Store中含有Reference文件,Reference文件是split region产生的临时文件,只是简单的引用文件,一般必须在compact过程中删除。
如果不满足major compaction条件,就必然为minor compaction。
compact 线程池选择
compact 有 largeCompaction、smallCompaction这两个线程池负责处理compact 请求。
- largeCompaction (longCompaction):大文件合并线程,当合并的文件总大小大于阈值(throttlePoint)时处理;
- smallCompaction (shortCompaction):小文件合并线程池。处理合并文件总大小小于阈值时的情况。
大小合并的阈值(throttlePoint)由参数hbase.regionserver.thread.compaction.throttle决定,没有设置的话,由:2 * "hbase.hstore.compaction.max" * "hbase.hregion.memstore.flush.size", 默认的2.5GB。
| |
Compact过程
源码HStore::compact()中,具体流程如下:
分别读出待合并hfile文件的KV,并顺序写到位于./tmp目录下的临时文件中
将临时文件移动到对应region的数据目录
将compaction的输入文件路径和输出文件路径封装为KV写入WAL日志,并打上compaction标记,最后强制执行sync
将对应region数据目录下的compaction输入文件全部删除
上述四个步骤看起来简单,但实际是很严谨的,具有很强的容错性和完美的幂等性:
A. 如果RS在步骤2之前发生异常,本次compaction会被认为失败,如果继续进行同样的compaction,上次异常对接下来的compaction不会有任何影响,也不会对读写有任何影响。唯一的影响就是多了一份多余的数据。
B. 如果RS在步骤2之后、步骤3之前发生异常,同样的,仅仅会多一份冗余数据。
C. 如果在步骤3之后、步骤4之前发生异常,RS在重新打开region之后首先会从WAL中看到标有compaction的日志,因为此时输入文件和输出文件已经持久化到HDFS,因此只需要根据WAL移除掉compaction输入文件即可
in-memory Compaction策略 当一个active segment被flush到pipeline中之后,后台会触发一个任务对pipeline中的数据进行合并。合并任务会对pipeline中所有segment进行scan,将他们的索引合并为一个。有三种合并策略可供选择:Basic,Eager,Adaptive。 Basic compaction策略和Eager compaction策略的区别在于如何处理cell数据。Basic compaction不会清理多余的数据版本,这样就不需要对cell的内存进行拷贝。而Eager compaction会过滤重复的数据,并清理多余的版本,这意味着会有额外的开销:例如如果使用了MSLAB存储cell数据,就需要把经过清理之后的cell从旧的MSLAB拷贝到新的MSLAB。basic适用于所有写入模式,eager则主要针对数据大量淘汰的场景:例如消息队列、购物车等。 Adaptive策略则是根据数据的重复情况来决定是否使用Eager策略。在Adaptive策略中,首先会对待合并的segment进行评估,方法是在已经统计过不重复key个数的segment中,找出cell个数最多的一个,然后用这个segment的numUniqueKeys / getCellsCount得到一个比例,如果比例小于设定的阈值,则使用Eager策略,否则使用Basic策略。
Compact流控
| |