HBase
简介
Apache HBase是基于Hadoop构建的一个分布式、可伸缩的海量数据存储系统。
HDFS为Hbase提供底层数据存储服务,
Zookeeper为Hbase提供稳定服务和Failover机制,
MapReduce为Hbase提供高性能的计算能力,
是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。
特点
- 海量存储:单表支持几十亿行,几百万列,数千个版本的数据,TB/PB级别;
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
- 列式存储:列族存储;
- 易扩展:横向扩展(RegionServer),提高并发能力;纵向扩展(hdfs),提高存储容量
- 高并发:在并发的情况下,Hbase的单个IO延迟下降并不多
- 稀疏:空数据不占用存储空间。
对比
| RDBMS | HBase | |
|---|---|---|
| 硬件架构 | 传统的多核系统,硬件成本昂贵 | 分布式集群,硬件成本低廉 |
| 数据库大小 | GB,TB | PB |
| 扩展性 | 横向扩展和纵向扩展较差 | 很方便进行横向扩展和纵向扩展 |
| 容错性 | 一般需要额外硬件设备实现 HA 机制 | 结合HDFS提供可靠的数据冗余,由于由多个节点组成,所以不担心一点或几点宕机 |
| 吞吐量 | 百万查询/每秒 | 数千查询/每秒 |
| 数据保护 | 替换 | 保留 |
| 存储模式 | 行存储,密集 | 列族存储,稀疏 |
| 数据类型 | 丰富 | 字节数组 |
| 事务支持 | 全面的ACID事务支持,表级 | 行级 |
| 查询语言 | SQL | Java API |
| 索引 | 灵活多个 | Row-Key |
应用场景
Hbase是一个通过廉价PC机器集群来存储海量数据的分布式数据库解决方案。它比较适合的场景概括如下:
巨量大(百T、PB级别)
查询简单(基于rowkey或者rowkey范围查询)
不涉及到复杂的关联
典型应用场景:
- 海量订单流水数据(长久保存) 交易记录 数据库历史数据;
- 交易记录;
- 日志、监控类数据;
- 对象存储:不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中;
- 时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求;
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上;
- 时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中;
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求;
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上;
- Feeds流:典型的应用就是xx朋友圈类似的应用;
- NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求;
架构
架构图
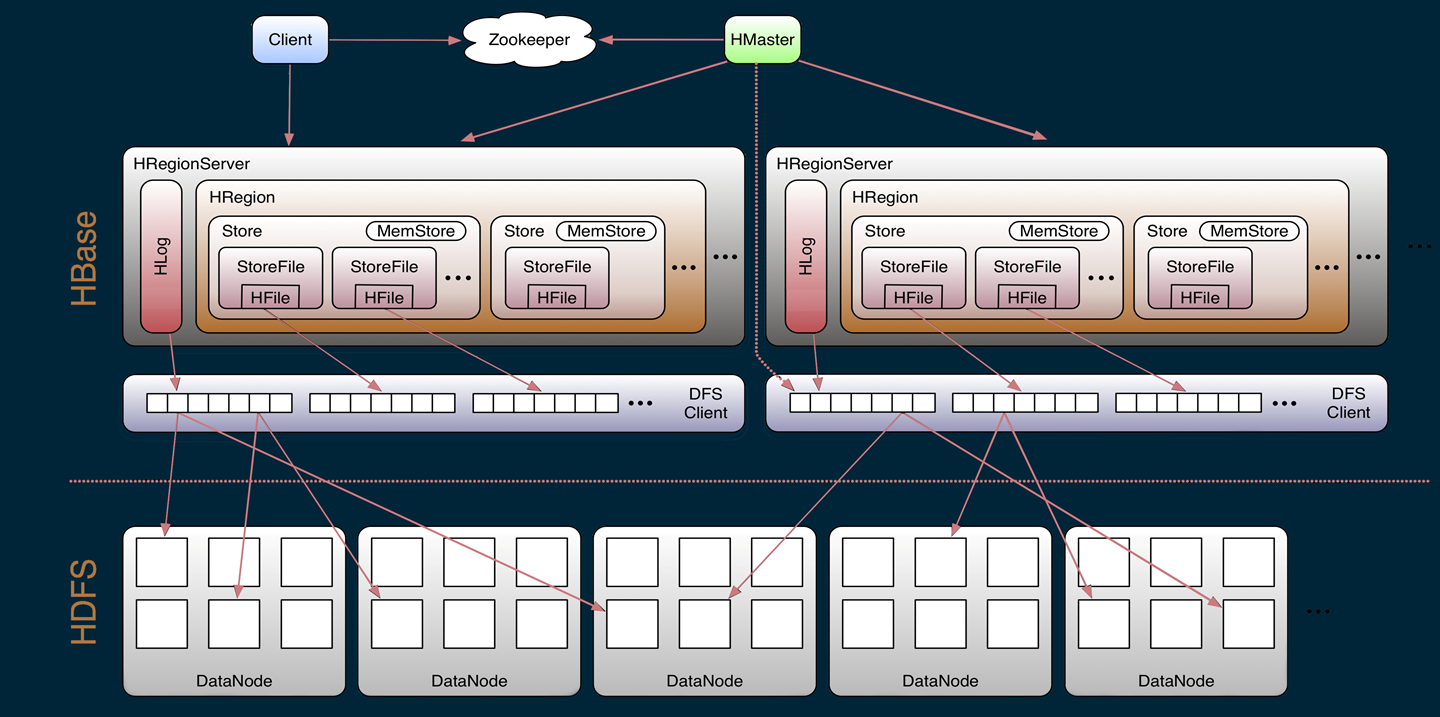
- Client:访问hbase的客户端,并提供缓存;
- Zookeeper:提供元数据查询、集群配置、状态监控及HA;
- HMaster:协调、监控RS集群状态,Region分配、负载均衡、提供DDL表操作功能;
- HRegionServer:管理HRegion,与底层FS交互,读写;
- HDFS: 数据文件存储;
基本概念
Table(表):数据的逻辑视图;
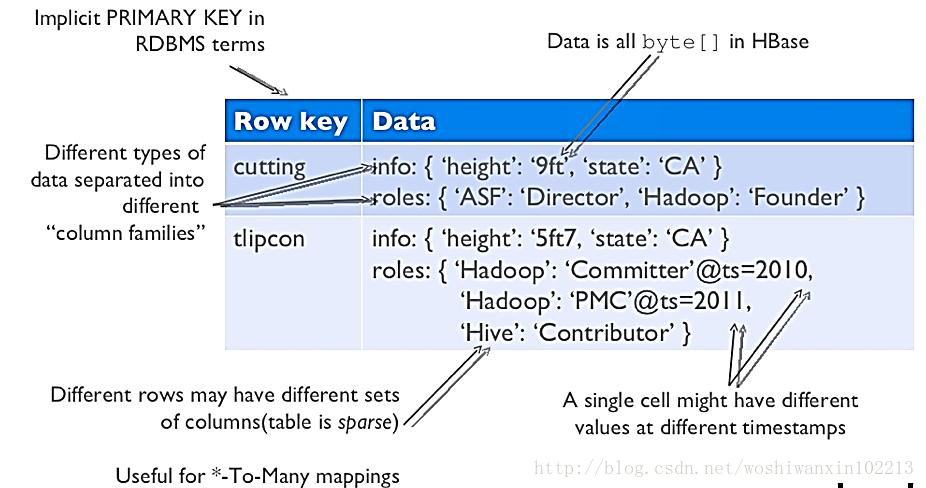
Row Key(行键):表中每条记录的全局唯一主键,字节数组,字典排序,最大64K。尽量现在合适的Row Key 是数据相近的数据分布在同一个Region中,提高效率;
Region(分区):表会按Row Key拆分成一定大小的Key Range,每个“Key Range”称为一个Region;
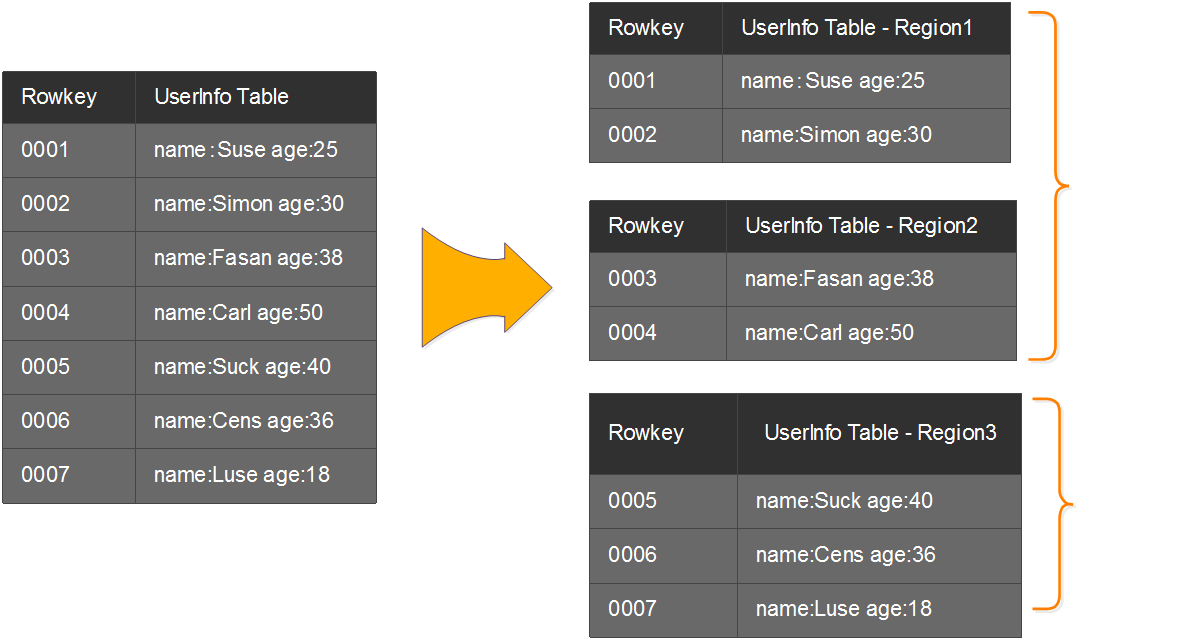
列族(Column Family):包含多个列数据,同一个CF的列数据存储在一个文件中,读取时可一次读取;建议1-3个CF;
时间戳(Timestamp):时间戳用于区分数据的不同版本,最新的时间戳在最前面,通过时间戳简化了数据的更新和删除操作;
值(Key Value):数据值
基本操作
- get:根据 (row_key, cf, name ) -> value
- scan: 更加条件获取批量的数据;
- put:插入更新;
- delete:删除数据;
重要数据结构
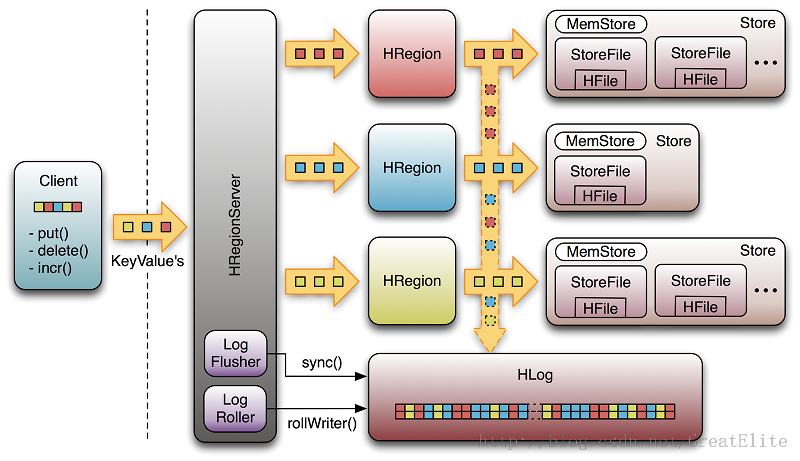
HRegionServer
- 每个RegionServer 包含一个 WAL(预写日志文件),一个BlockCache(读缓存),0到多个(默认最多1000)Region;
- 每个Region包含多个Store(对应CF的数量),每个Store包含1个MemStore(写缓存),0-多个HFile;
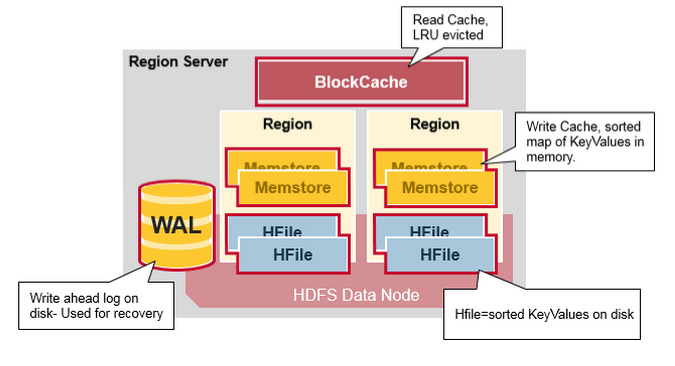
HRegion
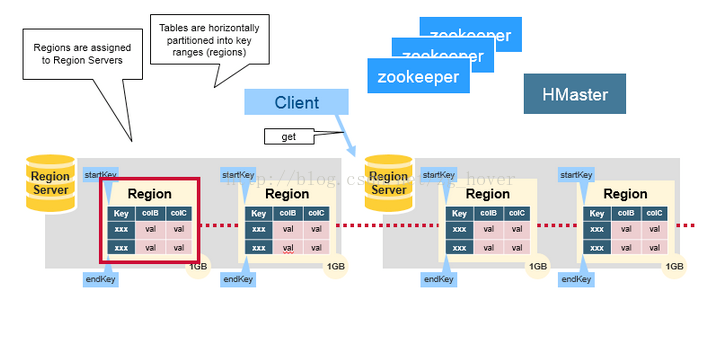
- HBase通过RowKey将表水平切割成多个HRegion,一个HRegion有一个startKey和endKey的row key,包含了从startKey到endKey范围内的所有的行(包含startKey,但不包含endKey)
- 每个Regions被HMaster分配到某个RegionServe上,这些RegionServer负责数据的读取和写入。一个RegionServer可以服务多个region。数量大概是1000个。
MemStore(写缓存)
- MemStore 用来缓存写数据的,写入数据的keyValues;
- 当memStore的大小达到一个阀值(默认128MB)时,memStore会被flush到文件HFile;
BlockCache(读缓存)
- BlockCache用来缓存读数据,每个RegionServer维持一个BlockCache;;
- BlockCache由Block组成,Block默认大小64K;
- 默认BlockCache将Block分成3个优先队列:Single,Multi,InMemory,用于提高Cache效率。
- BlockCache大小是固定的,可由参数hfile.block.cache.size,默认是RegionServer堆内存的40%;
- BlockCache实现方案:LRUBlockCache,SlabCache,BucketCache;
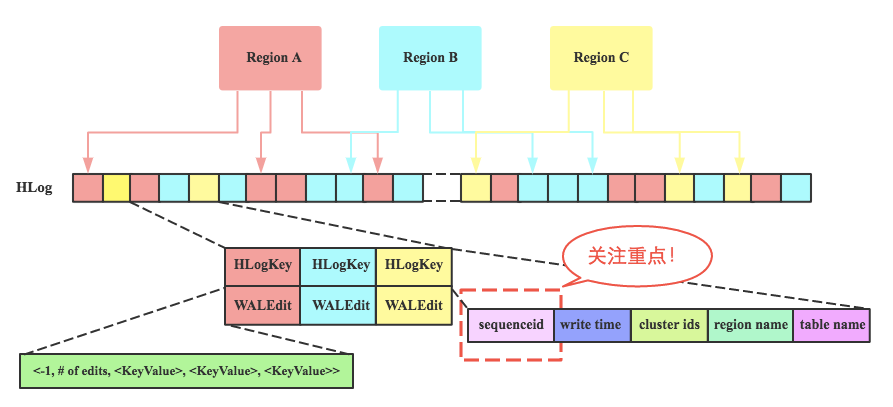
HLog(WAL)
每一个RegionServer有一个WAL Log文件(1.0后可配置多个);
WAL Log 文件为顺序写入,速度很快;
WAL Log 文件只append,不更改;
由于WAL 文件可由HDFS自动生成副本,发生故障时,可通过副本进行恢复;
MemStore 在内存中的数据失效后,可由WAL文件进行恢复;
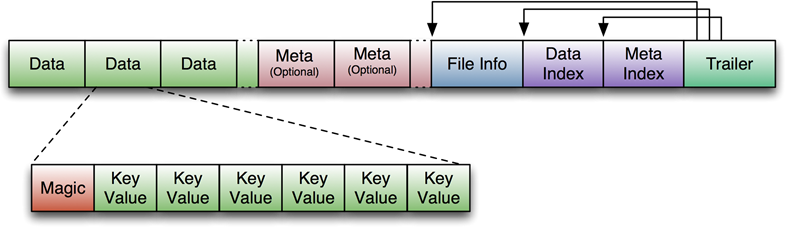
HFile
HFile是Hbase数据在磁盘上的存储文件,在HDFS上的存储目录结构为 表名/region名/列族名/HFiles,HFile存储了一个多级索引(multi-layered index), 通过多级索引就可以快速得到数据(工作机制类似于b+tree)
- Key-Value按照升序排列
- Key-Value存储在以64KB为单位的Block里
- 每个Block有一个叶索引(leaf-index), 记录Block的位置
- 每个Block的最后一个Key(译注: 最后一个key也是最大的key), 放入中间索引(intermediate index)
- 根索引(root index)指向中间索引
关键流程
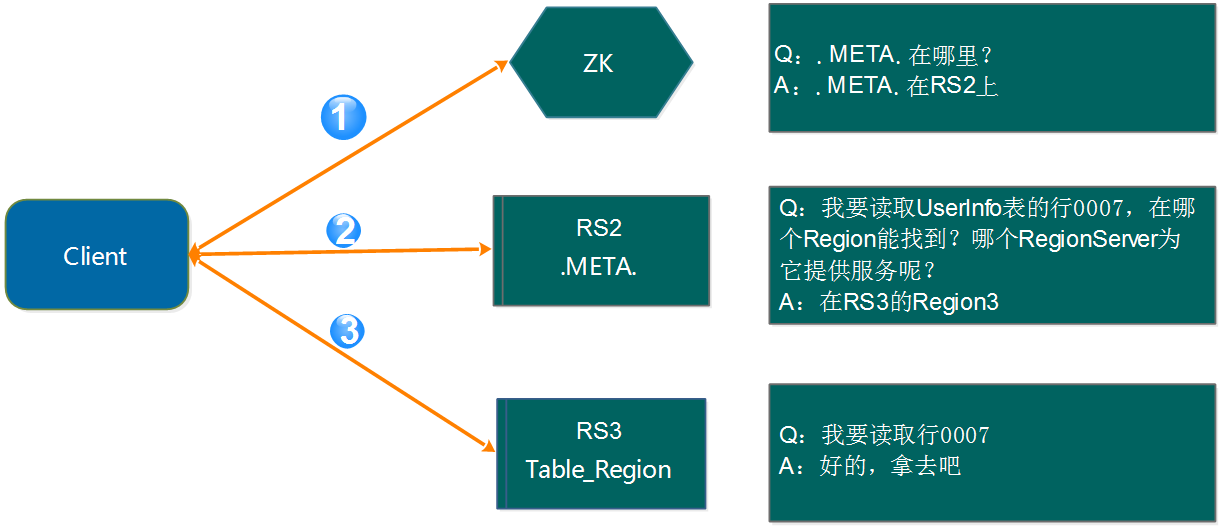
Region定位
写流程
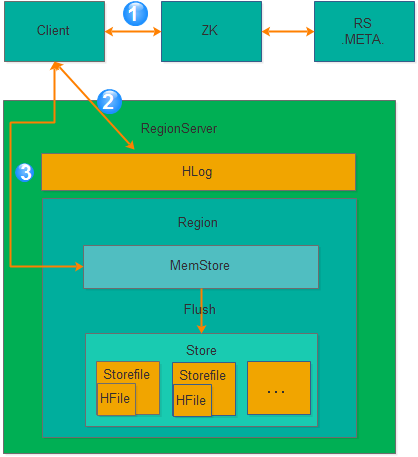
client 向zk查询应该写入到哪个RS;
将数据append到RS的WAL中;
将数据写入到MemStore中,写操作返回;
MemStore达到一定条件[1],则把数据flush到HFile文件中。
当HFile文件数量达到一定阈值,会触发合并(compaction)操作;当单个HFile大小超过一定阈值后,会触发拆分(split)操作。
StoreFile的合并(Compaction)和拆分(Split)
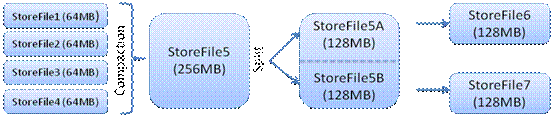
Compaction分为两种:
minor compaction:把多个小HFile合并成一个大HFile,主要是为了提高读效率(因为一个row可能散布在多个HFile文件中)。minor compaction不做任何删除数据、过期数据的清理工作。
major compaction:把给定region的一个列族的所有HFile合并成一个文件,major compaction会丢弃有删除标记的或过期的内容,释放占用的空间。
minor合并是轻量级的,可以频繁发生;major合并相当耗资源,不要经常使用,且通常需要手工触发。
Split操作过程完成的非常快,因为原始的数据文件并不会被改变,系统只是简单的创建两个Reference文件指向原始的数据文件,每个Reference文件管理原始文件一半的数据。Reference文件名字是一个ID,它使用被参考的region的名字的hash作为前缀,例如:1278437856009925445.3323223323。Reference文件只含有非常少量的信息,这些信息包括被分割的原始region的key以及这个文件管理前半段还是后半段。只有当系统做compaction的时候原始数据文件才会被分割成两个独立的文件并放到相应的region目录下面,同时原始数据文件和那些Reference文件也会被清除。
读流程
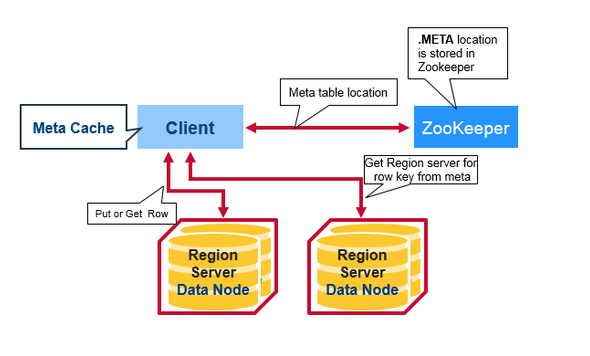
- Client先从Zookeeper中获取托管META表的RegionServer。
- Client查询.META.服务,来获取需要访问的RowKey对应的Region Server。Client将这些信息与META表位置一起缓存起来。
- Client从相应的Region Server获取该行的数据。
- 之后的查询都是从 client 缓存读取 meta 信息从对应的 region server 查询;(如果缓存中查询不到对应的数据那么将从第一步重新开始)
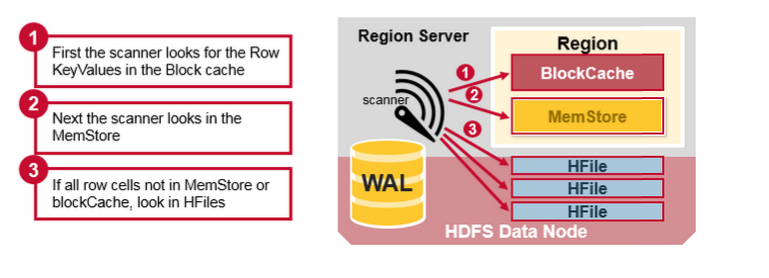
具体从RegionServer中读数据的过程
- 先从BlockCache(读缓存)中找对应的 row;
- 如果缓存里找不到,那就去查询 MemStore(写缓存)找对应的最近的写数据;
- 如果两个地方都没用,那么就会根据 BlockCache 中的 B+ Tree Index(mentioned above)以及 Bloom Filter找 HFile 里的数据;
- 两个缓存无法命中且大量 HFile 未合并的时候,将有可能对很多的 HFiles 进行读操作(这叫 读放大(Read Amplification)。
6. 总结
- HDFS + ZooKeeper 提供了高可用和数据可靠存储的能力;
- 通过CF + Region 的相关设计,将数据进行按序物理分片,实现了数据的海量扩展;
- 通过WAL + MemStore 的相关设计,将随机写转化为顺序写,实现了写操作的性能优化;
- 通过 BlockCache + HFile 的相关设计 ,将随机读操作;
参考
HBase会在如下几种情况下触发flush操作,需要注意的是MemStore的最小flush单元是HRegion而不是单个MemStore。可想而知,如果一个HRegion中Memstore过多,每次flush的开销必然会很大,因此我们也建议在进行表设计的时候尽量减少ColumnFamily的个数。
- Memstore级别限制:当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。
- Region级别限制:当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认 2* 128M = 256M),会触发memstore刷新。
- Region Server级别限制:当一个Region Server中所有Memstore的大小总和达到了上限(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认 40%的JVM内存使用量),会触发部分Memstore刷新。Flush顺序是按照Memstore由大到小执行,先Flush Memstore最大的Region,再执行次大的,直至总体Memstore内存使用量低于阈值(hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize,默认 38%的JVM内存使用量)。
- 当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
- HBase定期刷新Memstore:默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
- 手动执行flush:用户可以通过shell命令 flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
- http://www.dataguru.cn/article-9479-1.html