Nebula Graph
简介
Nebula Graph是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
特点
- 全对称分布式架构
- 存储与计算分离
- 水平可扩展性
- RAFT 协议下的数据强一致
- 支持 openCypher
- 用户鉴权
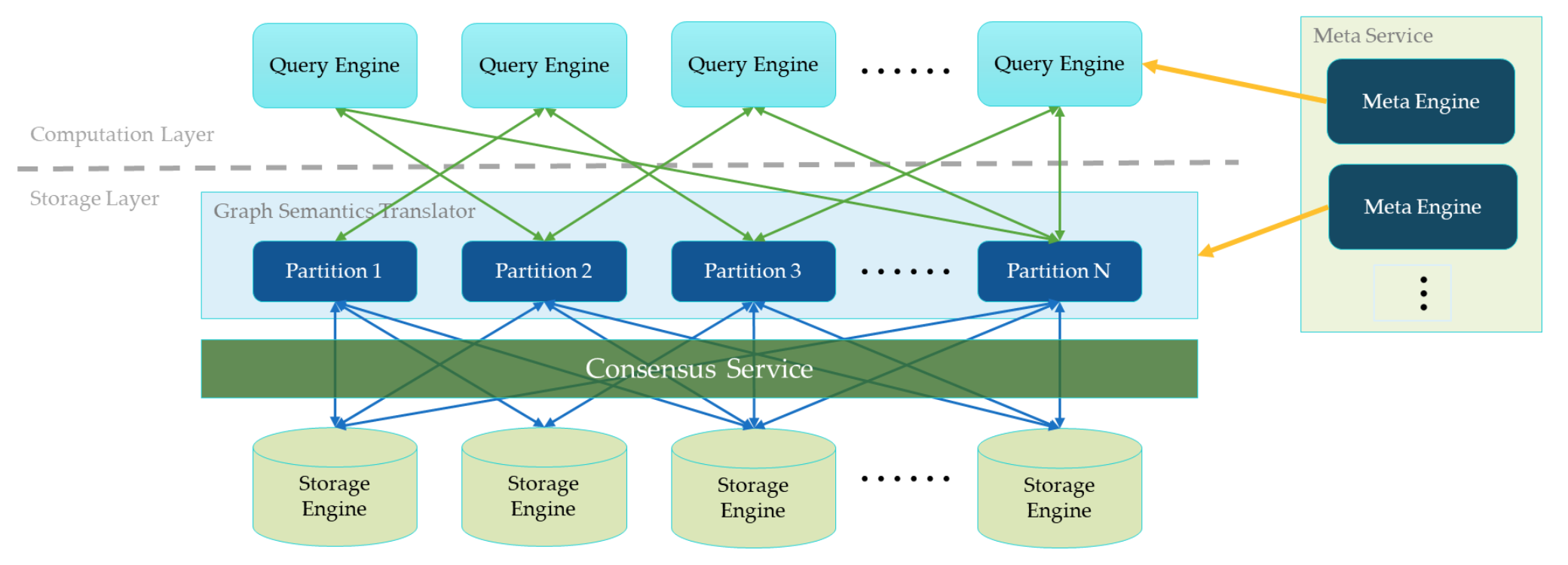
架构
数据结构¶
Nebula Graph数据模型使用5种数据结构来保存数据:
点(vertex)
点用来保存实体对象,特点如下:
- 点是用点标识符(
VID)标识的。VID在同一图空间中唯一。 - 点必须有至少一个标签(Tag)。
- 点是用点标识符(
标签(tag)
标签可以用于对点进行区分。具有相同标签的点共享相同的属性定义。
边(edge)
边是用来连接点的,表示两个点之间的关系或行为,特点如下:
- 一条边有且仅有一个边类型。
- 起点、边类型(edge type)、rank、终点可以唯一表示一条边。
- 边是有指向的。
->表示边的指向,边可以沿任意方向遍历。 - 边必须有rank。rank是一个不可更改的、用户分配的、64位有符号整数。通过它才能识别两个点之间具有相同边类型的边。边按它们的rank排序,值大的边排在前面。默认rank为0。
边类型(edge type)
边类型用于对边进行区分。具有相同边类型的边共享相同的属性定义。
属性(properties)
属性是指以键值对(key-value)形式存储点或边的相关信息。
有向属性图¶
Nebula Graph将数据存储在有向属性图中。有向属性图是指点和边构成的图,这些边是有方向的。有向属性图表示为:
G = < V, E, PV, PE >
- V是点的集合。
- E是有向边的集合。
- PV 是点的属性。
- PE 是边的属性。