Flink-基本
数据流
数据流就是一个无界(unbounded)的事件序列。事件(Event)可以是监控报警数据、传感器感知数据、信用卡交易、用户在APP上的行为…随着数据量的爆炸式增长,单台机器无法处理庞大的数据流,一般需要多台机器并行地处理,因此需要一种并行的流式计算引擎来对大数据场景下的数据流做处理。
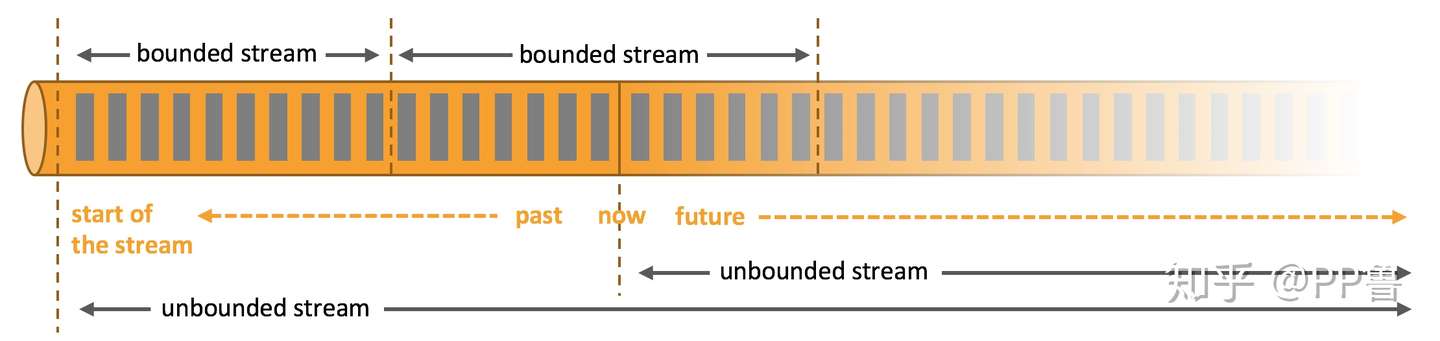
有界和无界数据 来源:Flink官网
流式计算的衡量指标:延迟和吞吐
在批量计算场景,主要通过一次计算的总时间来评价性能。在流式计算场景,数据源源不断地流入系统,计算引擎对每个数据处理地越快越好,计算引擎能处理的数据量越大越好。例如处理实时的Twitter文本数据案例,如果系统只能处理一个人发的Tweet或处理时间长达一天,那说明这个系统非常不靠谱。为了衡量流式计算的“快”和“量”两方面的性能,一般用延迟(Latency)和吞吐(Throughput)这两个指标。
延迟 Latency
延迟表示一个事件被系统处理的总时间,一般以毫秒为单位。根据业务应用不同,我们一般关心平均延迟和分位延迟(Percentile Latency)。假设一个煎饼摊就是一个流式计算系统,每个顾客来购买煎饼是它所需要处理的事件,从顾客到达到顾客拿到购买的煎饼并付费离开,就是这个顾客的延迟。如果正赶上了早餐高峰期,顾客极有可能排队,这个排队时间也要算在延迟时间中。例如,99分位延迟表示系统处理前99%顾客所需的最长时间,也就是对所有顾客延迟排名后,第99%的那个时间。一般商业系统更关注分位延迟,因为分位延迟比平均延迟能反应出这个系统的一些潜在问题。还是以煎饼摊为例,一般煎饼中都有薄脆,薄脆是单独制作的,如果薄脆制作的速度跟不上煎饼制作的速度,那在高峰期,将拖慢整个过程的延迟,部分用户会因为等待时间过久而放弃排队。
延迟对于很多流式计算非常重要,比如欺诈检测、告警监控等等。像Flink这样的流式计算引擎可以将延迟降到毫秒级别,如果用mini-batch的方法处理同样的问题,很可能是分钟级到小时级的延迟,因为计算引擎必须等待一批数据达到才开始进行计算。
吞吐 Throughput
吞吐表示一个系统最大能处理多少事件,一般以单位时间处理的事件数量为单位。需要注意的是,吞吐除了与引擎自身设计有关,也与数据源发送过来的事件数据量有关,有可能计算引擎的最大吞吐量远大于数据源的数据量。比如,煎饼摊可能在早七点到九点的需求最高,很可能出现大量排队的情况,但另外的时间几乎不需要排队等待。假设一天能提供1000个煎饼,服务10个小时,那它的平均吞吐量为100个/小时;仅早上2小时的高峰期就提供了600个煎饼,它的峰值吞吐量是300个/小时。比起平均吞吐量,峰值吞吐量更影响用户体验,如果峰值吞吐量低,也会导致用户等待时间过久而放弃排队。早高峰时,一般用户都需要排队等待,排队的过程被称作缓存(Buffering)。如果仍然有大量事件进入缓存,很可能超出系统的极限,就会出现反压问题(Backpressure),这时候就需要一些优雅的策略来处理类似问题,否则会造成系统崩溃,用户体验极差。
延迟与吞吐
延迟与吞吐其实并不是相互孤立的,他们相互影响。如果延迟高,那么很可能造成吞吐低,系统处理不了太多事件。为了优化这两个指标,一种办法是提高煎饼师傅的制作速度,当用户量大到超过单个煎饼师傅的瓶颈时,接着就需要考虑再增加一个煎饼师傅。这也是当前大数据系统都在采用的并行(parallelism)策略,如果一个机器做不了或做得不够快,那就用更多的机器一起来做。
数据流图
数据流图描述了数据如何在不同的操作间流动。数据流图一般是一个有向图,图中的节点是一个算子(Operator),表示某种运算,边表示数据间的相互依赖关系或数据的流动方向。算子从输入读取数据,进行一些计算,接着将计算结果发送到下一个算子。Source是所有计算的开始,Sink是所有计算的终点。

一个解析Twitter标签的数据流图逻辑视角 来源:Streaming Processing With Apache Flink
上图从逻辑角度描述数据的流动,对于一个Twitter数据流,接收输入源后需要将Twitter文本中的#井号标签去除,提取关键词,再对关键词做词频统计。这样一个图并没有考虑大数据情况下跨计算节点计算的问题,它只是一种处理问题的逻辑思路,因此称之为逻辑视角。
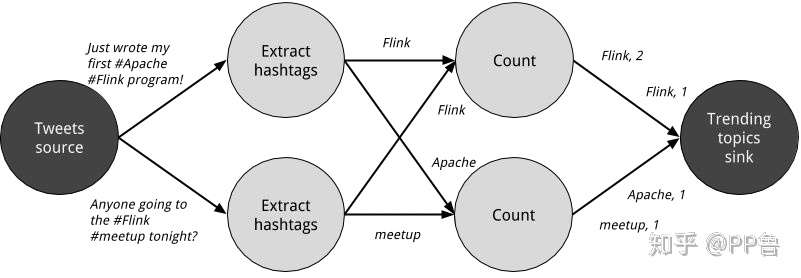
数据流图的物理视角 来源:Streaming Processing With Apache Flink
实现一个能够处理大数据的分布式系统,需要考虑在多个节点上并行计算。上图将逻辑视角细化为物理视角。Source发出的数据会兵分两路,被分配到两个节点上,在各自节点上进行"Extract hashtags"和"Count"运算。每个"Extract hashtags"和"Count"运算只处理一部分数据。最终数据要聚合到Sink上。
数据交换策略
在物理视角中,我们看到数据经历了跨节点的数据交换。比如,我们要统计"Flink"这个单词出现的次数,各个节点可能都会解析出"Flink"这个单词,但是我们最终要的是所有节点上的"Flink"单词的总和。因此从"Extract hashtags"到"Count",发生了数据交换,所有的"Flink"被发送到第一个节点上,才能做词频求和统计。在这个任务中,同一个词需要交换到同一个节点上,就是一种数据交换。
在流式计算场景,某个节点及节点上的数据通常被称为分区(partition)。
数据交换一般有以下几种策略。

数据交换策略 来源:Streaming Processing With Apache Flink
- Forward:数据在一个分区上前向传播,无需跨节点通信。
- Broadcast:将数据发送到所有分区上,需要大量的跨节点通信开销。
- Key-Based:按照某个key将数据做分片,某个key的所有数据都会分配到一个分区上。刚才词频统计的例子中,就是以单词为key进行的分片处理。
- Random:将数据做随机均匀分片,以避某个分区上的数据过大。
状态 State
状态是流式计算特有的概念。比如刚才计算词频的例子,要统计实时数据流一分钟内的单词词频,一方面要处理每一瞬间新流入的数据,另一方面要保存之前一分钟内已经进入系统的单词词频。再举一个告警的例子,当系统在监听到“高温”事件后10分钟内又监听到“冒烟”的事件,系统必须及时报警,系统必须把“高温”的事件作为状态记录下来,并判断这个状态下十分钟内是否有“冒烟”事件。
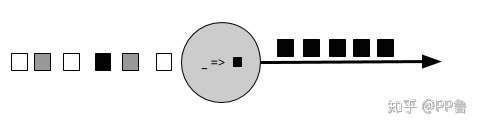
无状态算子 来源:Streaming Processing With Apache Flink
上图中的圆圈就是一个无状态算子,它将每个输入方框都转化成黑色。
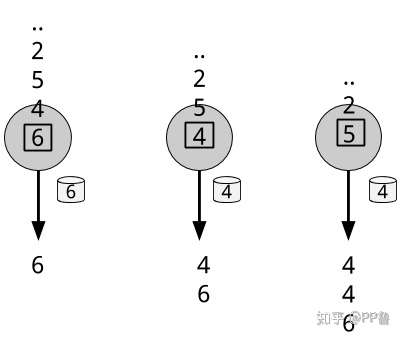
有状态算子 来源:Streaming Processing With Apache Flink
上图的圆圈是一个有状态算子,计算的是一个数据流中的最小值。它需要保存一个当前的最小值作为状态,并根据新事件来不断更新这个状态。
流式计算要处理无界的数据流,要注意如果将这些状态不断增长,最后造成数据爆炸,因此会使用一些机制来限制状态的数据总量。
综上,实现一个流式计算系统非常复杂,需要考虑几个因素:
- 系统必须能有效管理状态。因为一般的计算既依赖当前事件,也依赖之前事件产生的状态。
- 设计能够管理状态的并行算法极具挑战。一般将数据按照某个key进行切片,将一组大数据切分成小的分区,每个分区单独维护状态数据。
- 当系统出现错误而挂掉重启时,必须能够保证之前保存的状态数据也能恢复,否则重启后很多计算结果有可能是错误的。一般使用checkpoint来解决这个问题。
可见,流式计算系统比批量计算系统更难实现。
窗口
我们一般要对流式数据以窗口的形式做聚合统计分析。一般有如下几种定义窗口的方式。
Tumbling
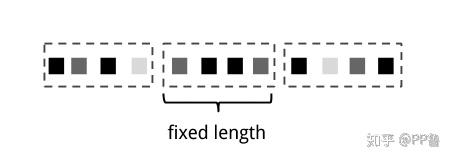
Count-Based Tumbling Window 来源:Streaming Processing With Apache Flink

Time-based Tumbing Window 来源:Streaming Processing With Apache Flink
Tumbling窗口互不重叠且一般是定长的,可以是固定事件数目,也可以是固定时间间隔。
Sliding
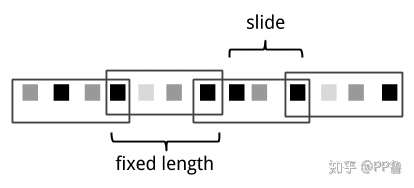
Sliding Window 来源:Streaming Processing With Apache Flink
滑动窗口的窗口与窗口之间有滑动间隔(Slide)。
Session
Session是一个用户与互联网应用交互的概念,一般指用户在APP或网站上的一系列行为。比如,用户在淘宝上短时间有大量的搜索和点击的行为,这一些列行为组成了一个Session,接着可能因为一些其他因素,用户暂停了与APP的交互,过一会用户又返回了APP,经过一系列搜索、点击、与客服沟通,最终下单。Session窗口的长度并不固定,因此不能简单用上面两种形式的窗口来建模。
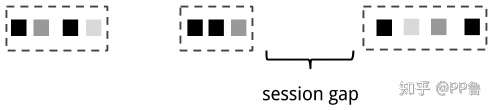
Session Window 来源:Streaming Processing With Apache Flink
Session窗口没有固定长度,一般使用Session Gap将数据做分组。
并行物理视角
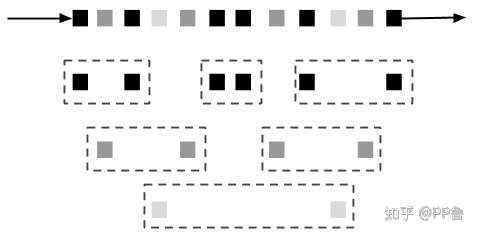
Parallel Count-based Tumbling Window 来源:Streaming Processing With Apache Flink
前面讲的几种窗口都是从全局视角定义的逻辑窗口,实际上数据是在不同分区上的。例如,接受一个传感器数据流,我们可以根据传感器id作为key,将来自同一个传感器的事件都切分到一个分区上。每个分区的数据是独立的,其窗口策略也是独立的。例如上图所示的,同一颜色的事件被分到同一个分区上,组成固定长度为2的窗口。
时间语义
“一分钟”真的是一分钟吗?
你可能觉得时间是最简单不过的事情,没什么可讨论的,恰恰相反,在很多应用场景,时间有着不同的意义。“一分钟”真的是一分钟吗?
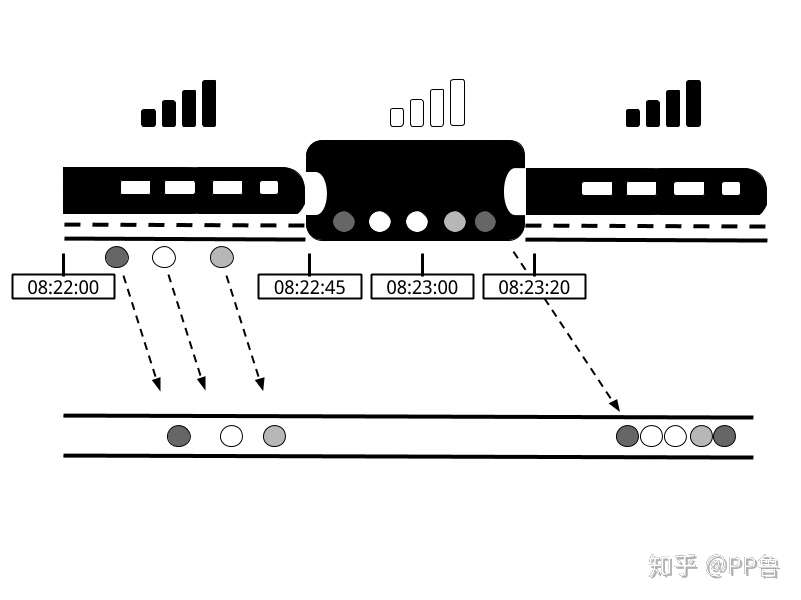
穿越隧道的一分钟 来源:Streaming Processing With Apache Flink
假设你坐高铁并玩王者荣耀消磨时间,王者荣耀在最终计算MVP时,要考虑的一个因素是玩家每分钟释放技能次数。在一波团战中,你疯狂抢了三个人头,正当你觉得稳拿MVP时,高铁穿越进了隧道,手机丢失信号,你掉线了!好在高铁在隧道里只停留了几十秒,APP缓存了你掉线时的数据,并在信号恢复后将缓存数据传回了服务器。在这种情形下,时间比想象中更复杂,有一个时间记录事件实际发生的时间(Event Time),还有一个时间是事件上传到服务器后,服务器处理时间(Processing Time)。
比如,你旁边的小伙伴跟你一起开黑,他的手机运营商更给力,进隧道后没有丢信号,如果都使用Processing Time,在丢失信号的这段时间,你的数据没有计算进去,显然对你来说是不公平的。但是当信号恢复,数据重传到服务器,再根据Event Time重新计算一次,那就非常公平了。我们可以根据Event Time复现一个事件序列的顺序,因此,使用Event Time是最准确的。
Watermark
虽然使用Event Time更准确,但问题在于,因为各种不可控因素,事件上报会有延迟,那么最多要等待多长时间呢?从服务器的角度来看,在事件到达之前,我们也无法确定是否有事件已经延迟,如何设置Event Time时间窗口成了很大的问题。比如刚才的例子,我们要统计一分钟内的实时数据,考虑到事件的延迟,如何设置合理的等待时间,以等待一分钟内所有事件都到达服务器?也正因为这个问题,流式计算比批量计算在准确性上有差距,因为批量计算一般以更长的一段时间为一个批次,一个批次内延迟上报的数据比一个时间窗口内延迟上报的数据相对比例更少。比如某个电商平台上,去计算一件商品每分钟点击次数,使用一天的总数除以分钟数的计算方法,比使用一分钟时间窗口实时的点击次数更准确。可以看到,数据的实时性和准确性二者不可得兼,必须取一个平衡。
Watermark是一种折中解决方案,它假设某个时间点上,不会有比这个时间点更晚的上报数据。当算子接受到一个Watermark后,它会假定后续不会再接收到这个时间窗口的内容,然后会触发对当前时间窗口的计算。比如,一种 Eager Watermark 策略的等待延迟上报的时间非常短,这样能保证低延迟,但是会导致错误率上升。在实际应用中,Watermark设计多长非常有挑战。还是以刚才手机游戏的例子,系统不知道玩家这次掉线的原因是什么,可能是在穿越隧道,也可能是坐飞机进入飞行模式,还有可能把这个游戏删了再也不玩了。
Processing Time 与 Event Time
那既然Event Time似乎可以解决一切问题,为什么还要使用Processing Time?前面也提到了,为了处理延迟上报或顺序错乱的事件,需要使用一些机制来做等待,这样会导致延迟上升。在某些场景可能对准确性要求不高,但是要求实时性更高,Processing Time就更合适一些。
投递保障
事件进入到计算引擎,如果引擎遇到故障并重启,该事件是否被成功处理了呢?一般有三种结果。
At Most Once: 每个事件最多被处理一次,也就是说,有可能某些事件没有被处理。
At Least Once: 每个事件至少被处理一次,如果系统遇到故障,系统重启后该事件会被再次处理一次。
Exactly Once: 每个事件只被处理一次,无论是否有故障重启。“Exactly Once"意味着事件不能有任何丢失,也必须保障状态也"Exactly Once”。Flink实现了"Exactly Once"语义。
小结
本文简述了流式大数据处理引擎的一些基础概念,包括数据流、数据流图、衡量指标、状态、时间、以及投递保障,每个流式计算引擎的实现过程都要面对这些问题,Flink对这些问题做出了具体实现。