ElasticSearch基础
简介
Elasticsearch 是一个基于
Lucene的搜索和分析引擎;近实时;
分布式可扩展的近实时;
架构

- 一个 ES Index 在集群模式下,有多个 Node (节点)组成。每个节点就是 ES 的Instance (实例)。
- 每个节点上会有多个 shard (分片), P1 P2 是主分片, R1 R2 是副本分片
- 每个分片上对应着就是一个 Lucene Index(底层索引文件)
- Lucene Index 是一个统称
- 由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档。
- commit point记录了所有 segments 的信息
特点
- 分布式存储
- 近实时检索
核心概念
- 索引(index):
- 分片(shard):
- 分段(segment):
- Translog:
数据类型
Elasticsearch中每个field都要精确对应一个数据类型;
类型包括:
keyword:不需要分词,进行过滤、排序、聚合等操作;
text:分词,用于全文搜索,无法排序,聚合等操作;
integer:
Shard分片和Replica副本
es通过
shard(分片)来保证数据的可扩展性;es通过
replica(副本)来保证数据的高可用性;默认基于hash的分片规则:
shard = hash(routing) % number_of_primary_shards, routing为doc id;在创建索引数据时,可以指定相关的shards数量和replicas,否则默认为5和1;
对于索引来说,shards设置后,无法改变;replicas可以通过api更新;
分片数量和节点数相关,一般满足:节点最大数 = 分片数 * (副本数 + 1);
每个分片都是一个Lucene Index,所以一个分片只能存放 Integer.MAX_VALUE - 128 = 2,147,483,519个docs。
在索引写入时,副本分片做着与主分片相同的工作。新文档首先被索引进主分片然后再同步到其它所有的副本分片。
Master选举
读写流程
写流程
创建索引的过程:
- 准备待索引的原文档,数据来源可能是文件、数据库或网络
- 对文档的内容进行分词组件处理,形成一系列的Term
- 索引组件对文档和Term处理,形成字典和倒排表
搜索索引的过程:
- 对查询语句进行分词处理,形成一系列Term
- 根据倒排索引表查找出包含Term的文档,并进行合并形成符合结果的文档集
- 比对查询语句与各个文档相关性得分,并按照得分高低返回
单文档写入流程
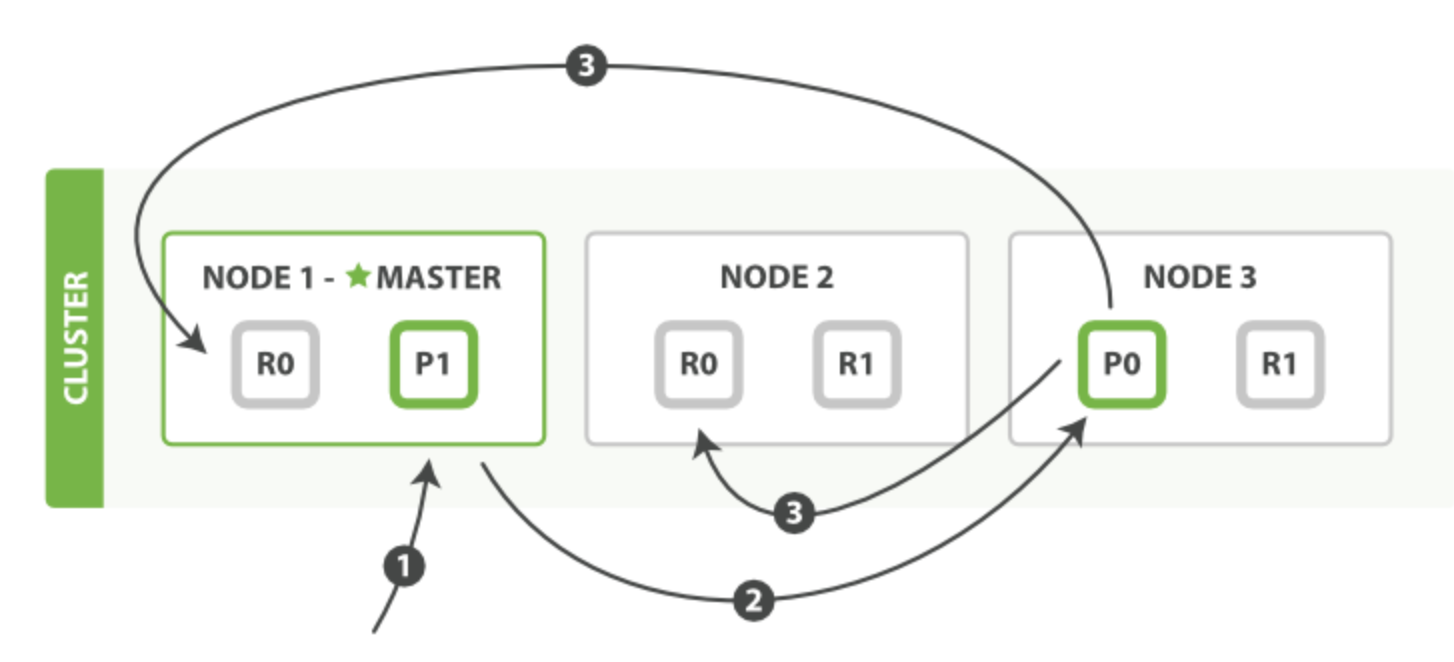
- 客户端向 Node 1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
常用操作
- 清空index数据
| |
TF/IDF
TF(Term Frequency, 词频): 词(Term)在文档中出现的频率;
$ tf(t\in d) = \sqrt{frequency} $
IDF(Invert Doc Frequency, 逆向文档频率): 索引中文档数量除以所有包含该词的文档数
$ idf(t) = 1 + log ( numDocs / (docFreq + 1)) $
norm(字段长度归一值): 字段中词数平方根的倒数,
$ norm(d) = 1 / \sqrt{numTerms} $
API
| |
Alias(索引别名)
alias是index的一个快捷方式或软连接,用来实现索引变更的零停机操作;
Elasticsearch 中有两种方式管理别名:
_alias用于单个操作;_aliases用于执行多个原子级操作;
| |