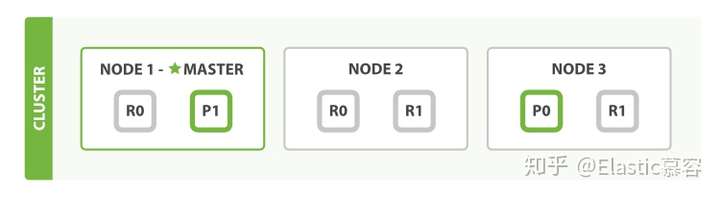
Elasticsearch写流程
lucene的写操作及其问题
Elasticsearch底层使用Lucene来实现doc的读写操作,Lucene通过
| |
三个方法来实现文档的写入,更新和删除操作。但是存在如下问题
- 没有并发设计。 lucene只是一个搜索引擎库,并没有涉及到分布式相关的设计,因此要想使用Lucene来处理海量数据,并利用分布式的能力,就必须在其之上进行分布式的相关设计。
- 非实时。 将文件写入lucence后并不能立即被检索,需要等待lucene生成一个完整的segment才能被检索
- 数据存储不可靠。 写入lucene的数据不会立即被持久化到磁盘,如果服务器宕机,那存储在内存中的数据将会丢失
- 不支持部分更新 。lucene中提供的updateDocuments仅支持对文档的全量更新,对部分更新不支持
2. Elasticsearch的写入方案
针对Lucene的问题,ES做了如下设计
2.1 分布式设计:
为了支持对海量数据的存储和查询,Elasticsearch引入分片的概念,一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的lucene实例。分片可以分配在不同的服务器上,同一个分片的不同副本不能分配在相同的服务器上。
在进行写操作时,ES会根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式 shard_num=hash(\routing)%num_primary_shards,计算出文档要分配到的分片,在从集群元数据中找出对应主分片的位置,将请求路由到该分片进行文档写操作。
2.2 近实时性-refresh操作
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,会定时地调用lucene的reopen(新版本为openIfChanged)为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由 refresh_interval参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
2.3 数据存储可靠性
- 引入translog 当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置
index.translog.durability和index.translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。由于translog是追加写入,因此性能要比随机写入要好。与传统的分布式系统不同,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度,因此先写入Lucene. - flush操作 另外每30分钟或当translog达到一定大小(由
index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化,会清空translog中的数据(6.x版本为了实现sequenceIDs,不删除translog)
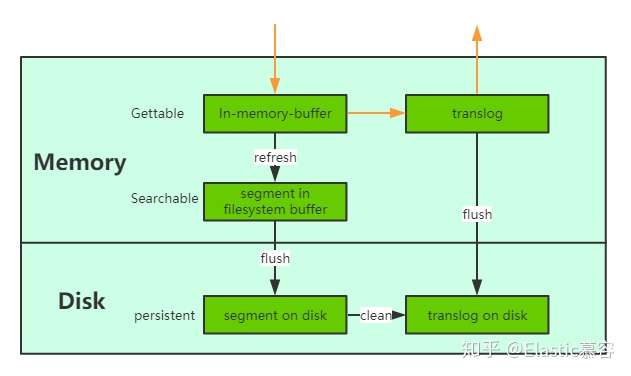
- merge操作 由于refresh默认间隔为1s中,因此会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
- 多副本机制 另外ES有多副本机制,一个分片的主副分片不能分片在同一个节点上,进一步保证数据的可靠性。
2.4 部分更新
lucene仅支持对文档的整体更新,ES为了支持局部更新,在Lucene的Store索引中存储了一个_source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从_source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。另外为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
3. ES的写入流程
选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个 coordinating node(协调节点);
计算得到文档要写入的分片
shard = hash(routing) % number_of_primary_shardsrouting 是一个可变值,默认是文档的 _id ;coordinating node会进行路由,将请求转发给对应的primary shard所在的 DataNode(假设primary shard在node1、replica shard在node2) ;
node1节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到 Replica shard ;
Primary Shard和Replica Shard都保存好了文档,返回client;
大致流程如下图:
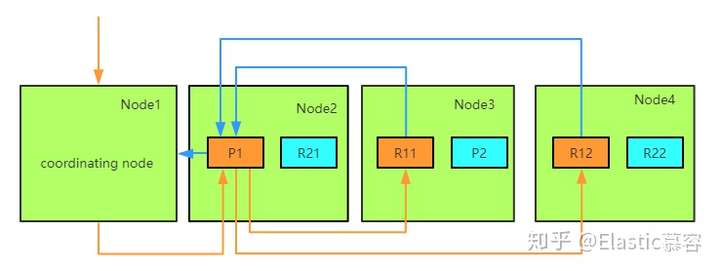
3.1 coordinating节点
ES中接收并转发请求的节点称为coordinating节点,ES中所有节点都可以接受并转发请求。当一个节点接受到写请求或更新请求后,会执行如下操作:
- ingest pipeline 查看该请求是否符合某个ingest pipeline的pattern, 如果符合则执行pipeline中的逻辑,一般是对文档进行各种预处理,如格式调整,增加字段等。如果当前节点没有ingest角色,则需要将请求转发给有ingest角色的节点执行。
- 自动创建索引 判断索引是否存在,如果开启了自动创建则自动创建,否则报错
- 设置routing 获取请求URL或mapping中的_routing,如果没有则使用_id, 如果没有指定_id则ES会自动生成一个全局唯一ID。该_routing字段用于决定文档分配在索引的哪个shard上。
- 构建BulkShardRequest 由于Bulk Request中包含多种(Index/Update/Delete)请求,这些请求分别需要到不同的shard上执行,因此协调节点,会将请求按照shard分开,同一个shard上的请求聚合到一起,构建BulkShardRequest
- 将请求发送给primary shard 因为当前执行的是写操作,因此只能在primary上完成,所以需要把请求路由到primary shard所在节点
- 等待primary shard返回
目前的Elasticsearch有两个明显的身份,一个是分布式搜索系统,另一个是分布式NoSQL数据库,对于这两种不同的身份,读写语义基本类似,但也有一点差异。

写操作
实时性:
搜索系统的Index一般都是NRT(Near Real Time),近实时的,比如Elasticsearch中,Index的实时性是由refresh控制的,默认是1s,最快可到100ms,那么也就意味着Index doc成功后,需要等待一秒钟后才可以被搜索到。
NoSQL数据库的Write基本都是RT(Real Time),实时的,写入成功后,立即是可见的。Elasticsearch中的Index请求也能保证是实时的,因为Get请求会直接读内存中尚未Flush到存储介质的TransLog。
可靠性:
搜索系统对可靠性要求都不高,一般数据的可靠性通过将原始数据存储在另一个存储系统来保证,当搜索系统的数据发生丢失时,再从其他存储系统导一份数据过来重新rebuild就可以了。在Elasticsearch中,通过设置TransLog的Flush频率可以控制可靠性,要么是按请求,每次请求都Flush;要么是按时间,每隔一段时间Flush一次。一般为了性能考虑,会设置为每隔5秒或者1分钟Flush一次,Flush间隔时间越长,可靠性就会越低。
NoSQL数据库作为一款数据库,必须要有很高的可靠性,数据可靠性是生命底线,决不能有闪失。如果把Elasticsearch当做NoSQL数据库,此时需要设置TransLog的Flush策略为每个请求都要Flush,这样才能保证当前Shard写入成功后,数据能尽量持久化下来。
读操作
下一篇《Elasticsearch内核解析 - 查询篇》中再详细介绍。
上面大概对比了下搜索和NoSQL在写方面的特点,接下来,我们看一下Elasticsearch 6.0.0版本中写入流程都做了哪些事情,希望能对大家有用。
关键点
在考虑或分析一个分布式系统的写操作时,一般需要从下面几个方面考虑:
- 可靠性:或者是持久性,数据写入系统成功后,数据不会被回滚或丢失。
- 一致性:数据写入成功后,再次查询时必须能保证读取到最新版本的数据,不能读取到旧数据。
- 原子性:一个写入或者更新操作,要么完全成功,要么完全失败,不允许出现中间状态。
- 隔离性:多个写入操作相互不影响。
- 实时性:写入后是否可以立即被查询到。
- 性能:写入性能,吞吐量到底怎么样。
Elasticsearch作为分布式系统,也需要在写入的时候满足上述的四个特点,我们在后面的写流程介绍中会涉及到上述四个方面。
接下来,我们一层一层剖析Elasticsearch内部的写机制。
Lucene的写
众所周知,Elasticsearch内部使用了Lucene完成索引创建和搜索功能,Lucene中写操作主要是通过IndexWriter类实现,IndexWriter提供三个接口:
| |
通过这三个接口可以完成单个文档的写入,更新和删除功能,包括了分词,倒排创建,正排创建等等所有搜索相关的流程。只要Doc通过IndesWriter写入后,后面就可以通过IndexSearcher搜索了,看起来功能已经完善了,但是仍然有一些问题没有解:
- 上述操作是单机的,而不是我们需要的分布式。
- 文档写入Lucene后并不是立即可查询的,需要生成完整的Segment后才可被搜索,如何保证实时性?
- Lucene生成的Segment是在内存中,如果机器宕机或掉电后,内存中的Segment会丢失,如何保证数据可靠性 ?
- Lucene不支持部分文档更新,但是这又是一个强需求,如何支持部分更新?
上述问题,在Lucene中是没有解决的,那么就需要Elasticsearch中解决上述问题。
Elasticsearch在解决上述问题时,除了我们在上一篇《Elasticsearch数据模型简介》中介绍的几种系统字段外,在引擎架构上也引入了多重机制来解决问题。我们再来看Elasticsearch中的写机制。
Elasticsearch的写
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。
此外,Elasticsearch整体架构上采用了一主多副的方式:

Elasticsearch一主多副
每个Index由多个Shard组成,每个Shard有一个主节点和多个副本节点,副本个数可配。但每次写入的时候,写入请求会先根据_routing规则选择发给哪个Shard,Index Request中可以设置使用哪个Filed的值作为路由参数,如果没有设置,则使用Mapping中的配置,如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard(在OperationRouting类中),最后从集群的Meta中找出出该Shard的Primary节点。
请求接着会发送给Primary Shard,在Primary Shard上执行成功后,再从Primary Shard上将请求同时发送给多个Replica Shard,请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功,返回结果给客户端。
这种模式下,写入操作的延时就等于latency = Latency(Primary Write) + Max(Replicas Write)。只要有副本在,写入延时最小也是两次单Shard的写入时延总和,写入效率会较低,但是这样的好处也很明显,避免写入后,单机或磁盘故障导致数据丢失,在数据重要性和性能方面,一般都是优先选择数据,除非一些允许丢数据的特殊场景。
采用多个副本后,避免了单机或磁盘故障发生时,对已经持久化后的数据造成损害,但是Elasticsearch里为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如5分钟)才会把Lucene的Segment写入磁盘持久化,对于写入内存,但还未Flush到磁盘的Lucene数据,如果发生机器宕机或者掉电,那么内存中的数据也会丢失,这时候如何保证?
对于这种问题,Elasticsearch学习了数据库中的处理方式:增加CommitLog模块,Elasticsearch中叫TransLog。

Refresh && Flush
在每一个Shard中,写入流程分为两部分,先写入Lucene,再写入TransLog。
写入请求到达Shard后,先写Lucene文件,创建好索引,此时索引还在内存里面,接着去写TransLog,写完TransLog后,刷新TransLog数据到磁盘上,写磁盘成功后,请求返回给用户。这里有几个关键点,一是和数据库不同,数据库是先写CommitLog,然后再写内存,而Elasticsearch是先写内存,最后才写TransLog,一种可能的原因是Lucene的内存写入会有很复杂的逻辑,很容易失败,比如分词,字段长度超过限制等,比较重,为了避免TransLog中有大量无效记录,减少recover的复杂度和提高速度,所以就把写Lucene放在了最前面。二是写Lucene内存后,并不是可被搜索的,需要通过Refresh把内存的对象转成完整的Segment后,然后再次reopen后才能被搜索,一般这个时间设置为1秒钟,导致写入Elasticsearch的文档,最快要1秒钟才可被从搜索到,所以Elasticsearch在搜索方面是NRT(Near Real Time)近实时的系统。三是当Elasticsearch作为NoSQL数据库时,查询方式是GetById,这种查询可以直接从TransLog中查询,这时候就成了RT(Real Time)实时系统。四是每隔一段比较长的时间,比如30分钟后,Lucene会把内存中生成的新Segment刷新到磁盘上,刷新后索引文件已经持久化了,历史的TransLog就没用了,会清空掉旧的TransLog。
上面介绍了Elasticsearch在写入时的两个关键模块,Replica和TransLog,接下来,我们看一下Update流程:
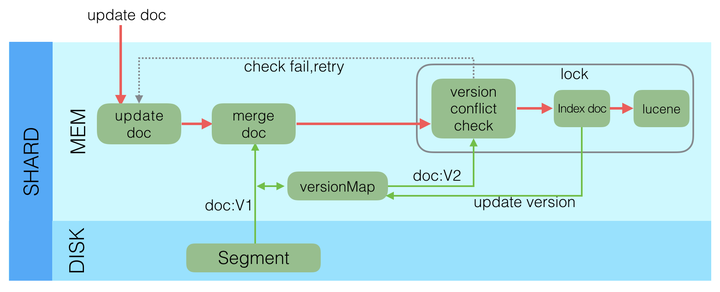
Update
Lucene中不支持部分字段的Update,所以需要在Elasticsearch中实现该功能,具体流程如下:
- 收到Update请求后,从Segment或者TransLog中读取同id的完整Doc,记录版本号为V1。
- 将版本V1的全量Doc和请求中的部分字段Doc合并为一个完整的Doc,同时更新内存中的VersionMap。获取到完整Doc后,Update请求就变成了Index请求。
- 加锁。
- 再次从versionMap中读取该id的最大版本号V2,如果versionMap中没有,则从Segment或者TransLog中读取,这里基本都会从versionMap中获取到。
- 检查版本是否冲突(V1==V2),如果冲突,则回退到开始的“Update doc”阶段,重新执行。如果不冲突,则执行最新的Add请求。
- 在Index Doc阶段,首先将Version + 1得到V3,再将Doc加入到Lucene中去,Lucene中会先删同id下的已存在doc id,然后再增加新Doc。写入Lucene成功后,将当前V3更新到versionMap中。
- 释放锁,部分更新的流程就结束了。
介绍完部分更新的流程后,大家应该从整体架构上对Elasticsearch的写入有了一个初步的映象,接下来我们详细剖析下写入的详细步骤。
Elasticsearch写入请求类型
Elasticsearch中的写入请求类型,主要包括下列几个:Index(Create),Update,Delete和Bulk,其中前3个是单文档操作,后一个Bulk是多文档操作,其中Bulk中可以包括Index(Create),Update和Delete。
在6.0.0及其之后的版本中,前3个单文档操作的实现基本都和Bulk操作一致,甚至有些就是通过调用Bulk的接口实现的。估计接下来几个版本后,Index(Create),Update,Delete都会被当做Bulk的一种特例化操作被处理。这样,代码和逻辑都会更清晰一些。
下面,我们就以Bulk请求为例来介绍写入流程。
Elasticsearch写入流程图
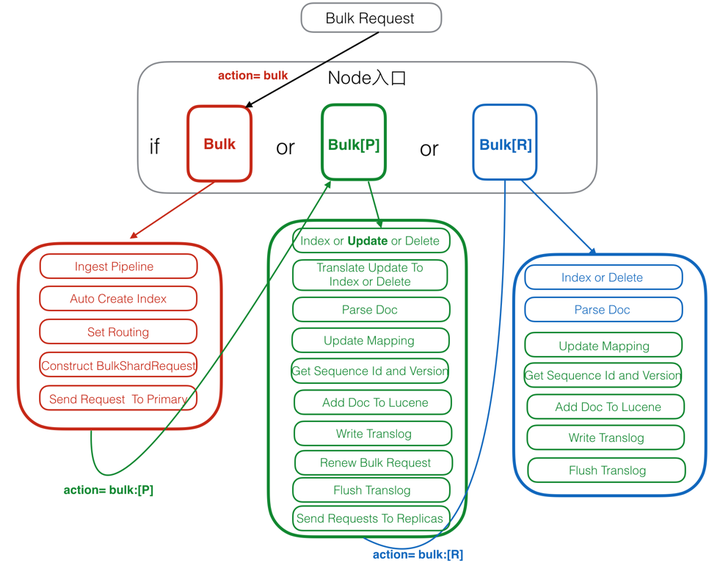
写入流程图
- 红色:Client Node。
- 绿色:Primary Node。
- 蓝色:Replica Node。
注册Action
在Elasticsearch中,所有action的入口处理方法都是注册在ActionModule.java中,比如Bulk Request有两个注册入口,分别是Rest和Transport入口:


如果请求是Rest请求,则会在RestBulkAction中Parse Request,构造出BulkRequest,然后发给后面的TransportAction处理。
TransportShardBulkAction的基类TransportReplicationAction中注册了对Primary,Replica等的不同处理入口:

这里对原始请求,Primary Node请求和Replica Node请求各自注册了一个handler处理入口。
Client Node
Client Node 也包括了前面说过的Parse Request,这里就不再赘述了,接下来看一下其他的部分。
1. Ingest Pipeline
在这一步可以对原始文档做一些处理,比如HTML解析,自定义的处理,具体处理逻辑可以通过插件来实现。在Elasticsearch中,由于Ingest Pipeline会比较耗费CPU等资源,可以设置专门的Ingest Node,专门用来处理Ingest Pipeline逻辑。
如果当前Node不能执行Ingest Pipeline,则会将请求发给另一台可以执行Ingest Pipeline的Node。
2. Auto Create Index
判断当前Index是否存在,如果不存在,则需要自动创建Index,这里需要和Master交互。也可以通过配置关闭自动创建Index的功能。
3. Set Routing
设置路由条件,如果Request中指定了路由条件,则直接使用Request中的Routing,否则使用Mapping中配置的,如果Mapping中无配置,则使用默认的_id字段值。
在这一步中,如果没有指定id字段,则会自动生成一个唯一的_id字段,目前使用的是UUID。
4. Construct BulkShardRequest
由于Bulk Request中会包括多个(Index/Update/Delete)请求,这些请求根据routing可能会落在多个Shard上执行,这一步会按Shard挑拣Single Write Request,同一个Shard中的请求聚集在一起,构建BulkShardRequest,每个BulkShardRequest对应一个Shard。
5. Send Request To Primary
这一步会将每一个BulkShardRequest请求发送给相应Shard的Primary Node。
Primary Node
Primary 请求的入口是在PrimaryOperationTransportHandler的messageReceived,我们来看一下相关的逻辑流程。
1. Index or Update or Delete
循环执行每个Single Write Request,对于每个Request,根据操作类型(CREATE/INDEX/UPDATE/DELETE)选择不同的处理逻辑。
其中,Create/Index是直接新增Doc,Delete是直接根据_id删除Doc,Update会稍微复杂些,我们下面就以Update为例来介绍。
2. Translate Update To Index or Delete
这一步是Update操作的特有步骤,在这里,会将Update请求转换为Index或者Delete请求。首先,会通过GetRequest查询到已经存在的同_id Doc(如果有)的完整字段和值(依赖_source字段),然后和请求中的Doc合并。同时,这里会获取到读到的Doc版本号,记做V1。
3. Parse Doc
这里会解析Doc中各个字段。生成ParsedDocument对象,同时会生成uid Term。在Elasticsearch中,_uid = type # _id,对用户,_Id可见,而Elasticsearch中存储的是_uid。这一部分生成的ParsedDocument中也有Elasticsearch的系统字段,大部分会根据当前内容填充,部分未知的会在后面继续填充ParsedDocument。
4. Update Mapping
Elasticsearch中有个自动更新Mapping的功能,就在这一步生效。会先挑选出Mapping中未包含的新Field,然后判断是否运行自动更新Mapping,如果允许,则更新Mapping。
5. Get Sequence Id and Version
由于当前是Primary Shard,则会从SequenceNumber Service获取一个sequenceID和Version。SequenceID在Shard级别每次递增1,SequenceID在写入Doc成功后,会用来初始化LocalCheckpoint。Version则是根据当前Doc的最大Version递增1。
6. Add Doc To Lucene
这一步开始的时候会给特定_uid加锁,然后判断该_uid对应的Version是否等于之前Translate Update To Index步骤里获取到的Version,如果不相等,则说明刚才读取Doc后,该Doc发生了变化,出现了版本冲突,这时候会抛出一个VersionConflict的异常,该异常会在Primary Node最开始处捕获,重新从“Translate Update To Index or Delete”开始执行。
如果Version相等,则继续执行,如果已经存在同id的Doc,则会调用Lucene的UpdateDocument(uid, doc)接口,先根据uid删除Doc,然后再Index新Doc。如果是首次写入,则直接调用Lucene的AddDocument接口完成Doc的Index,AddDocument也是通过UpdateDocument实现。
这一步中有个问题是,如何保证Delete-Then-Add的原子性,怎么避免中间状态时被Refresh?答案是在开始Delete之前,会加一个Refresh Lock,禁止被Refresh,只有等Add完后释放了Refresh Lock后才能被Refresh,这样就保证了Delete-Then-Add的原子性。
Lucene的UpdateDocument接口中就只是处理多个Field,会遍历每个Field逐个处理,处理顺序是invert index,store field,doc values,point dimension,后续会有文章专门介绍Lucene中的写入。
7. Write Translog
写完Lucene的Segment后,会以keyvalue的形式写TransLog,Key是_id,Value是Doc内容。当查询的时候,如果请求是GetDocByID,则可以直接根据_id从TransLog中读取到,满足NoSQL场景下的实时性要去。
需要注意的是,这里只是写入到内存的TransLog,是否Sync到磁盘的逻辑还在后面。
这一步的最后,会标记当前SequenceID已经成功执行,接着会更新当前Shard的LocalCheckPoint。
8. Renew Bulk Request
这里会重新构造Bulk Request,原因是前面已经将UpdateRequest翻译成了Index或Delete请求,则后续所有Replica中只需要执行Index或Delete请求就可以了,不需要再执行Update逻辑,一是保证Replica中逻辑更简单,性能更好,二是保证同一个请求在Primary和Replica中的执行结果一样。
9. Flush Translog
这里会根据TransLog的策略,选择不同的执行方式,要么是立即Flush到磁盘,要么是等到以后再Flush。Flush的频率越高,可靠性越高,对写入性能影响越大。
10. Send Requests To Replicas
这里会将刚才构造的新的Bulk Request并行发送给多个Replica,然后等待Replica的返回,这里需要等待所有Replica返回后(可能有成功,也有可能失败),Primary Node才会返回用户。如果某个Replica失败了,则Primary会给Master发送一个Remove Shard请求,要求Master将该Replica Shard从可用节点中移除。
这里,同时会将SequenceID,PrimaryTerm,GlobalCheckPoint等传递给Replica。
发送给Replica的请求中,Action Name等于原始ActionName + [R],这里的R表示Replica。通过这个[R]的不同,可以找到处理Replica请求的Handler。
11. Receive Response From Replicas
Replica中请求都处理完后,会更新Primary Node的LocalCheckPoint。
Replica Node
Replica 请求的入口是在ReplicaOperationTransportHandler的messageReceived,我们来看一下相关的逻辑流程。
1. Index or Delete
根据请求类型是Index还是Delete,选择不同的执行逻辑。这里没有Update,是因为在Primary Node中已经将Update转换成了Index或Delete请求了。
2. Parse Doc
3. Update Mapping
以上都和Primary Node中逻辑一致。
4. Get Sequence Id and Version
Primary Node中会生成Sequence ID和Version,然后放入ReplicaRequest中,这里只需要从Request中获取到就行。
5. Add Doc To Lucene
由于已经在Primary Node中将部分Update请求转换成了Index或Delete请求,这里只需要处理Index和Delete两种请求,不再需要处理Update请求了。比Primary Node会更简单一些。
6. Write Translog
7. Flush Translog
以上都和Primary Node中逻辑一致。
最后
上面详细介绍了Elasticsearch的写入流程及其各个流程的工作机制,我们在这里再次总结下之前提出的分布式系统中的六大特性:
- 可靠性:由于Lucene的设计中不考虑可靠性,在Elasticsearch中通过Replica和TransLog两套机制保证数据的可靠性。
- 一致性:Lucene中的Flush锁只保证Update接口里面Delete和Add中间不会Flush,但是Add完成后仍然有可能立即发生Flush,导致Segment可读。这样就没法保证Primary和所有其他Replica可以同一时间Flush,就会出现查询不稳定的情况,这里只能实现最终一致性。
- 原子性:Add和Delete都是直接调用Lucene的接口,是原子的。当部分更新时,使用Version和锁保证更新是原子的。
- 隔离性:仍然采用Version和局部锁来保证更新的是特定版本的数据。
- 实时性:使用定期Refresh Segment到内存,并且Reopen Segment方式保证搜索可以在较短时间(比如1秒)内被搜索到。通过将未刷新到磁盘数据记入TransLog,保证对未提交数据可以通过ID实时访问到。
- 性能:性能是一个系统性工程,所有环节都要考虑对性能的影响,在Elasticsearch中,在很多地方的设计都考虑到了性能,一是不需要所有Replica都返回后才能返回给用户,只需要返回特定数目的就行;二是生成的Segment现在内存中提供服务,等一段时间后才刷新到磁盘,Segment在内存这段时间的可靠性由TransLog保证;三是TransLog可以配置为周期性的Flush,但这个会给可靠性带来伤害;四是每个线程持有一个Segment,多线程时相互不影响,相互独立,性能更好;五是系统的写入流程对版本依赖较重,读取频率较高,因此采用了versionMap,减少热点数据的多次磁盘IO开销。Lucene中针对性能做了大量的优化。后面我们也会有文章专门介绍Lucene中的优化思路。