ClickHouse
简介
clickhouse是2016年由俄罗斯Yandex开源的一个OLAP列存数据库,拥有原生的向量化执行引擎
特性
- 列式数据库。 没有任何内容与值一起存储;
- 线性扩展。 可以通过添加服务器来扩展集群;
- 容错性。 系统是一个分片集群,其中每个分片都是一组副本。ClickHouse使用异步多主复制。数据写入任何可用的副本,然后分发给所有剩余的副本。Zookeeper用于协调进程,但不涉及查询处理和执行。
- PB级数据支持。能够存储和处理数PB的数据。
- SQL支持。 Clickhouse支持类似SQL的扩展语言,包括数组和嵌套数据结构、近似函数和URI函数,以及连接外部键值存储的可用性。
- *高性能。
- 数据压缩。
- HDD优化。 该系统可以处理不适合内存的数据。
- 用于数据库(DB)连接的客户端。
不足
- 不支持事务;
- 默认情况下,在执行聚合时,查询中间状态必须适合单个服务器上的RAM。但是,在这种情况下,可以将ClickHouse配置为溢出到磁盘上;
- 缺乏完整的
UPDATE/DELETE实现;
架构
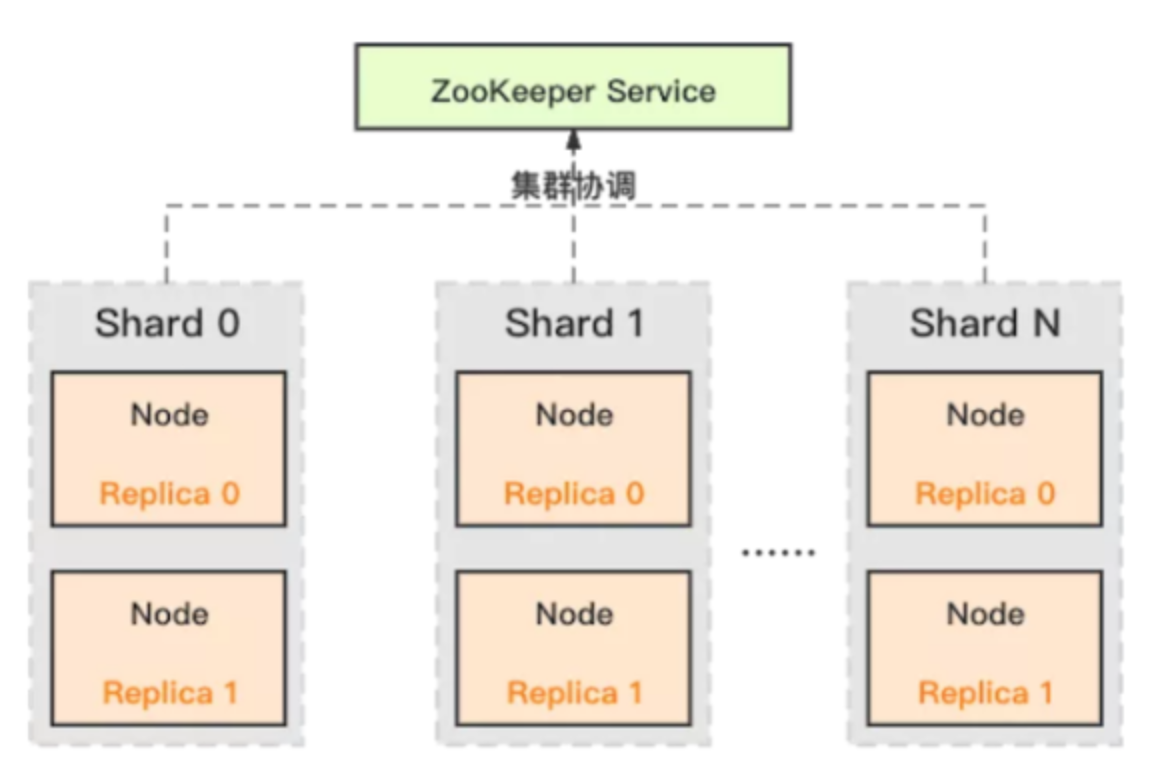
ClickHouse 采用典型的分组式的分布式架构,具体集群架构如上图所示:
- Shard:集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard 的线性扩展能力,支持海量数据的分布式存储计算。
- Node:每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
- ZooKeeper Service:集群所有节点对等,节点间通过 ZooKeeper 服务进行分布式协调。
常用场景
Clickhouse是为OLAP查询而设计的。
- 它可以处理少量包含大量字段的表。
- 查询可以使用从数据库中提取的大量行,但只用一小部分字段。
- 查询相对较少(通常每台服务器大约100个RPS)。
- 对于简单的查询,允许大约50毫秒的延迟。
- 列值相当小,通常由数字和短字符串组成(例如每个URL,60字节)。
- 处理单个查询时需要高吞吐量(每台服务器每秒数十亿行)。
- 查询结果主要是过滤或聚合的。
- 数据更新使用简单的场景(通常只是批量处理,没有复杂的事务)。
ClickHouse的一个常见情况是服务器日志分析。在将常规数据上传到ClickHouse之后(建议将数据每次1000条以上批量插入),就可以通过即时查询分析事件或监视服务的指标,如错误率、响应时间等。
ClickHouse还可以用作内部分析师的内部数据仓库。ClickHouse可以存储来自不同系统的数据(比如Hadoop或某些日志),分析人员可以使用这些数据构建内部指示板,或者为了业务目的执行实时分析。