BookKeeper
简介
BookKeeper是一个可靠的日志流记录系统,用于将系统产生的日志(也可以是其他数据)记录在BookKeeper集群上,由BookKeeper这个第三方Storage保证数据存储的可靠和一致性。
典型场景是系统写write-ahead log,即先把log写到BookKeeper上,BookKeeper诞生于Hadoop2.0的namenode HA,由yahoo于2009年创建,并在2011年开源。
架构

复制
BookKeeper对所有数据都会复制和存储相同的多份拷贝——一般是三份或是五份——到不同的机器上,可以是同一数据中心,也可以是跨数据中心。
不像其他使用主/从或是管道复制算法在副本之间复制数据的分布式系统(例如Apache HDFS、Ceph、Kafka),Apache BookKeeper使用一种多数投票并行复制算法在确保可预测的低延时的基础上复制数据。
BookKeeper复制基于以下核心思想:
日志流的原子结构是记录而不是字节。也就是说,数据总是以不可分割的记录形式(包括了元数据)存放的,而不是一个个字节组成的数组。
日志流中记录的顺序与实际记录的实际存储是解耦的。
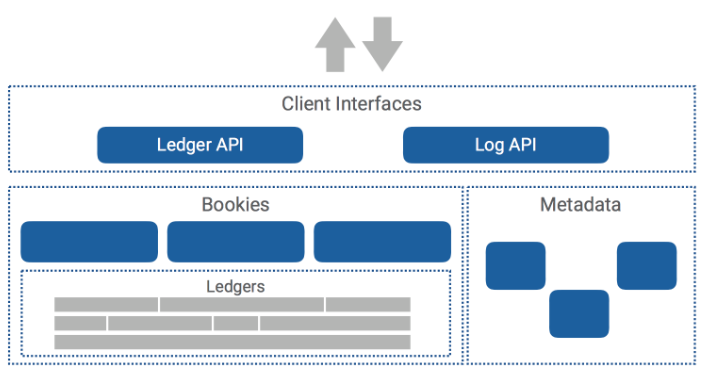
一个 BookKeeper 集群包括:
Bookies:一组独立的存储服务器
元数据存储系统:用于服务发现和元数据管理
BookKeeper 客户端可以使用较高级别的 DistributedLog API(也称为日志流 API)或较低级别的** ledger API**。Ledger API 允许用户直接与 bookies 交互。下图即为 BookKeeper 安装的典型示例。
典型的 BookKeeper 安装(通过多个 API 连接的应用程序)
流存储要求
在上篇文章中已经提到,实时存储平台应该同时满足以下要求:
即使在强持久性条件下,客户端也能够以极低的延迟(小于 5 毫秒)读写 entry 流
能够持久、一致、容错地存储数据
在写入时,客户端能够进行流式传输或追尾传输
有效存储数据,支持访问历史数据与实时数据
BookKeeper 通过提供以下保证来同时满足上述各项要求:
多副本
BookKeeper 在一个数据中心内的多个机器上,或是多个数据中心之间,复制每条数据记录并存储多个副本(通常是 3 个或 5 个副本)。
一些分布式系统使用主/从或管道复制算法在副本之间复制数据(例如,Apache HDFS、Ceph、Kafka 等),BookKeeper 的不同之处在于使用 quorum-vote 并行复制算法来复制数据,以确保可预测的低延迟。下图即为 BookKeeper 集成中的多副本。
BookKeeper 多副本中的 ensemble、写入、ack quorum
在上图中:
从 BookKeeper 集群中(自动)选择一组 bookies(图例中为 bookies 1-5)。这一组 bookies 即为给定 **ledger **上用于存储数据记录的 ensemble。
Ledger 中的数据分布在 bookies 的 ensemble 中。也就是说,每条记录都存有多个副本。用户可以在客户端级别配置副本数,即写入 quorum 大小。在上图中,写入 quorum 大小为 3,即记录写入到 bookie 2、bookie 3 与 bookie 4。
客户端向 ensemble 中写入数据记录时,需要等待直至有指定数量的副本发送确认(ack)。副本数即为 ack quorum 大小。接收到指定数量的 ack 后,客户端默认写入成功。在上图中,ack quorum 大小为 2,也就是说,比如 bookie 3 和 bookie 4 存储数据记录,则向客户端发送一条确认。
当 bookie 发生故障时,ensemble 的组成会发生变化。正常的 bookies 会取代终止的 bookies,这种取代可能只是暂时的。例如:如果 Bookie 5 终止,Bookie x 可能会取代它。
多副本:核心理念
BookKeeper 多副本基于以下核心理念:
日志流面向记录而不是面向字节。这意味着,数据总是存储为不可分割的记录(包括元数据),而不是存储为单个字节数组。
日志(流)中记录的顺序与记录副本的实际存储顺序分离。
这两个核心理念确保 BookKeeper 多副本能够实现以下几项功能:
为向 bookies 写入记录提供多种选择,从而确保即使集群中多个 bookies 终止或运行缓慢,写入操作仍然可以完成(只要有足够的容量来处理负载)。可以通过改变 ensemble 来实现。
通过增加 ensemble 大小来最大化单个日志(流)的带宽,以使单个日志不受一台或一小组机器的限制。可以通过将 ensemble 大小配置为大于写入 quorum 大小来实现。
通过调整 ack quorum 大小来改善追加时的延迟。这对于确保 BookKeeper 的低延迟十分重要,同时还可以提供一致性与持久性保证。
通过多对多副本恢复提供快速再复制(再复制为复制不足的记录创建更多副本,例如:副本数小于写入 quorum 大小)。所有的 bookies 都可以作为记录副本的提供者与接受者。
持久性
保证复制每条写入 BookKeeper 的数据记录,并持久化到指定数量的 bookies 中。可以通过使用磁盘 fsync 和写入确认来实现。
在单个 bookie 上,将确认发送给客户端之前,数据记录已明确写入(启用 fsync)磁盘,以便在发生故障时能够持久保存数据。这样可以保证数据写入到持久化存储中不依赖电源,可以被重新读取使用。
在单个集群内,复制数据记录到多个 bookies,以实现容错。
仅当客户端收到指定数量(通过 ack quorum 大小指定)的 bookies 响应时,才 ack 数据记录。
最新的 NoSQL 类型数据库、分布式文件系统和消息系统(例如:Apache Kafka)都假定:保证最佳持久化的有效方式是将数据复制到多个节点的内存中。但问题是,这些系统允许潜在的数据丢失。
BookKeeper 旨在提供更强的持久性保证,完全防止数据丢失,从而满足企业的严格要求。
一致性
保证一致性是分布式系统中的常见问题,尤其是在引入多副本以确保持久性和高可用时。BookKeeper 为存储在日志中的数据提供了简单而强大的一致性保证(可重复读取的一致性):
如果记录已被引用程序 ack,则必须立即可读。
如果记录被读取一次,则必须始终可读。如果记录 R 成功写入,则在 R 之前的所有记录都已成功提交/保存,并且将始终可读。
在不同读者之间,存储记录的顺序必须完全相同且可重复。
这种可重复读取的一致性由 BookKeeper 中的 LastAddConfirmed(LAC)协议实现。
高可用
在 CAP(Consistency:一致性、Availability:高可用、Partition tolerance:分区容错)条件下,BookKeeper 是一个 CP 系统。
但实际上,即使存在硬件、网络或其他故障,Apache BookKeeper 仍然可以提供高可用性。为保证写入与读取的高可用性能,BookKeeper 采用了以下机制:
低延迟
强持久性和一致性是分布式系统的复杂问题,特别是当分布式系统还需要满足企业级低延迟时。BookKeeper 通过以下方式满足这些要求:
在单个 bookie 上,bookie 服务器旨在用于不同工作负载(写入、追尾读、追赶读/随机读)之间的I/O 隔离。在 journal 上部署 group-committing 机制以平衡延迟与吞吐量。
采用 quorum-vote 并行复制 schema 缓解由于网络故障、JVM 垃圾回收暂停和磁盘运行缓慢引起的延迟损失。这样不仅可以改善追尾延迟,还能保证可预测的 p99 低延迟。
采用长轮询机制在 ack 并确认新记录后,立刻向追尾的写入者发出通知并发送记录。
最后,值得一提的是,明确 fsync 和写入确认的持久性与可重复的读取一致性对于状态处理(尤其是流应用程序的 effectively-once 处理)非常重要。