apache arrow
简介
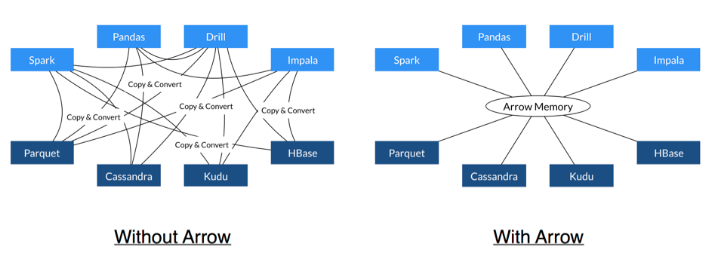
Apache Arrow 是一种基于内存的列式数据格式;
为了解决系统到系统之间的数据传输问题,
2016 年 2 月 Arrow 被提升为 Apache 的顶级项目。
和protobuf相比,protobuf主要是序列化structured data,有很多的键值对和非常深的nested structure。arrow序列化的对象主要还是表格状数据。
主要技术
- 适配器模式
列式存储
SIMD
即单指令流多数据流(SingleInstruction Multiple Data),是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元。
对于 Apache Arrow 的期望:
- 列式存储:大数据系统几乎都是列式存储的,类似于 Apache Parquet 这样的列式数据存储技术自从诞生起就是大家的期望。
- 内存式:SAP HANA 是第一个利用内存加速分析流程的组件,随着 Apache Spark 的出现,进一步提升了利用内存加速流程的技术可能性落地。
- 复杂数据和动态模式:当我们通过继承和内部数据结构呈现数据的时候,一开始有点麻烦,后来就有了 JSON 和基于文档的数据库。
Arrow 的列式存储有着 O(1) 的随机访问速度,并且可以进行高效的 Cache,同时还允许 SIMD 指令的优化。由于很多大数据系统都是在 JVM 上运行的,Arrow 对于 Python 和 R 的社区来说显得格外重要。
Apache Arrow 是基于 Apache Drill 中的 Value Vector 来实现的,而使用 Value Vector 可以减少运算时重复访问数据带来的成本。
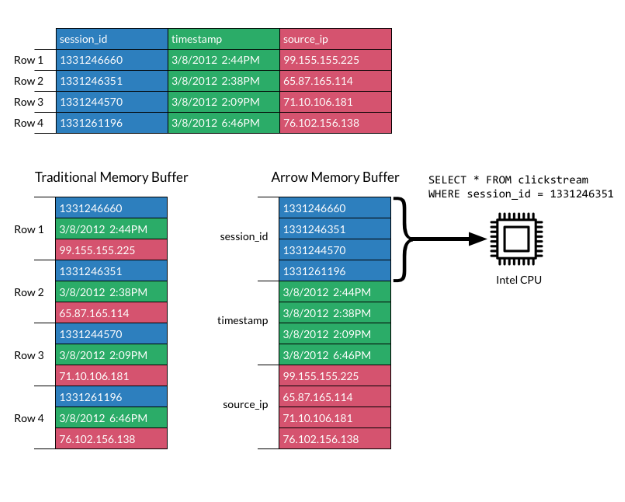
内存表示
arrow在内存中表示数据的最基本单元是array,它代表了一连串长度已知、类型相同的数据。而多个长度相同、类型相同或者不同的array就可以用来表示结果集(或者一部分的结果集)。举一个简单的例子:一个如下图所示的结果集(或者table)
| |
就可以表示成一个大小为2的有序集合,集合中的array(DoubleArray 和 StringArray)长度为3。arrow限制了array的最大长度,当结果集(或者表)的大小超过了array的最大长度,就需要把结果集水平切分成多个有序集合。
Arrow Flight
近段时间Arrow最大的变化就是添加了Flight,一个通用C/S架构的高性能数据传输框架。Flight基于gRPC开发,从最开始重点就是优化Arrow格式数据。
Flight的具体细节请看官方文档。这里只介绍它的优势:
- 无序列化/反序列化:Flight会直接将内存中的Arrow发送,不进行任何序列化/反序列化操作
- 批处理:Flight对record batch的操作无需访问具体的列、记录或者元素
- 高并发:Flight的吞吐量只收到客户端和服务端的吞吐量以及网络的限制
- 网络利用率高:Flight使用基于HTTP/2的gRPC,不仅是快
官方给出的数据是Flight的传输大约是标准ODBC的20-50倍。