Accumulo
简介
Apache Accumulo 由 NSA 开源一个可靠、可伸缩、高性能的排序分布式的 Key-Value 数据库。基于单元访问控制以及可定制的服务器端处理。Accumulo 使用 Google BigTable 设计思路,基于 Apache Hadoop、Zookeeper 和 Thrift 构建。它与 HBase 很像,但也有不少创新点,比如基于 cell 的访问控制,称为 iterator 的服务器端编程机制,可以在整个流程中对各种函数编码。Accumulo 设有自动负载平衡和分区,数据压缩和细粒度的安全标签。
特性
- BigTable 的复制品,也是跑在 Hadoop 的上层;
- 单元级安全保证;
- 允许使用比内存容量更大的数据列;
- 通过 C++ 的 STL 可保持数据从 JAVA 环境的内存映射出来;
- 使用 Hadoop 的 Map/reduce 模型;
- 支持在服务器端编程;
- 支持 multi-volume;
和 HBase 对比
- 安全性方面都支持 cell 级别的安全控制;
- hbase 使用 coprocessor,accumulo 使用的 iterator 来提供服务端定制功能;
- hbase 可跨数据中心复制,对灾难的恢复支持更好;
- 一致性模型:hbase 使用的日志复制,accumulo 使用的 mvcc;
- accumulo 可支持附加索引,hbase 只支持 row key 索引;
- accumulo 的 cf 不用事先制定,hbase 需要事先制定;
- accumulo 支持 locality group,hbase 不支持;
- accumulo 支持多 cf,hbase 的 cf 尽量少;
BigTable vs Accumulo vs HBase
| Bigtable | Accumulo | Hbase |
|---|---|---|
| Tablet | Tablet | Region |
| Tablet Server | Tablet Server | Region Server |
| Minor Compaction | Minor Compaction | Flush |
| Merging Compaction | Major Compaction | Minor Compaction |
| Major Compaction | (Full) Majro Compaction | Major Compaction |
| Commit Log | WAL | WAL |
| GFS | HDFS | HDFS |
| MemTable | MemTable | MemStore |
| SSTable | RFile | HFile |
| Chubby | ZooKeeper | ZooKeeper |
| MapReduce | Hadoop MapReduce | Hadoop MapReduce |
应用生态
Accumulo 最早由 NSA 2007 年开始开发,于 2011 年 9 月提交 Apache 基金会成为开源项目,Accumulo 数据库系统是 NSA 架构的核心(PRISM 棱镜项目的核心),大多数 NSA 的关键分析应用都运行在 Accumulo 上。NSA 开发 Accumulo 的工程师 2012 年离开 NSA,创办了基于 accumulo 的网络安全软件公司 Sqrrl,并于 2017 年 12 月被 Amazon 收购。
Accumulo 基于 Hadoop 生态,是 bigtable 的一种安全增加实现,因此很适合用于政府及大公司的大规模数据分析中。到 2014 年,已经有几十家不同类型的美国企业安装了 Accumulo 技术系统,其中,美国 20 强企业中已有 3 家安装,50 强企业中有 5 家安装,还有不少企业已表示对此有兴趣。国内公司使用的 accumulo 较少;
Accumulo 和 hbase 的重合度较高,彼此基本可以相互替代。想较于 hbase,其社区活跃度较低,文档较少,github: stark:384, fork:205 (hbase: star:2K, fork 1.5K );
使用场景
Accumulo 源于 NSA,因此很适用用于构建安全、实时的大数据应用系统,包括[^1]:
- 实时检测分析;
- 图数据;
- 物联网应用;
- Sessionization;
典型应用
- Sqrrl 威胁追踪平台:基于 accumulo 的可靠、安全、 多租户、 近实时数据分析系统,支持机构对几十 PB 级的数据分析,被很多美国政府和军方机构使用。
- Apache Fluo: Twitter Google Percolator的开源实现,允许用户对存储在 Apache Accumulo 中的大型数据集进行增量更新,而无需重新处理所有的数据。与批处理和流处理框架不同的是,Fluo 提供了更低的延迟,并且可以在极大的数据集上运行。在将新数据与现有数据相结合时,与批处理框架(例如 Spark,MapReduce)相比,Fluo 可明显减少延迟。其增量更新是使用事务实现的,允许数千个更新同时发生而不会破坏数据。
架构
一个典型的 Accumulo 系统包括一套 ZK 系统,多个 client,多个 TabletServers,一台 master 服务器,一个或多个 gc 收集进程,若干 monitor 进程,一个或多个 Tracer 进程。底层数据存储于 hadoop 的 hdfs 中。
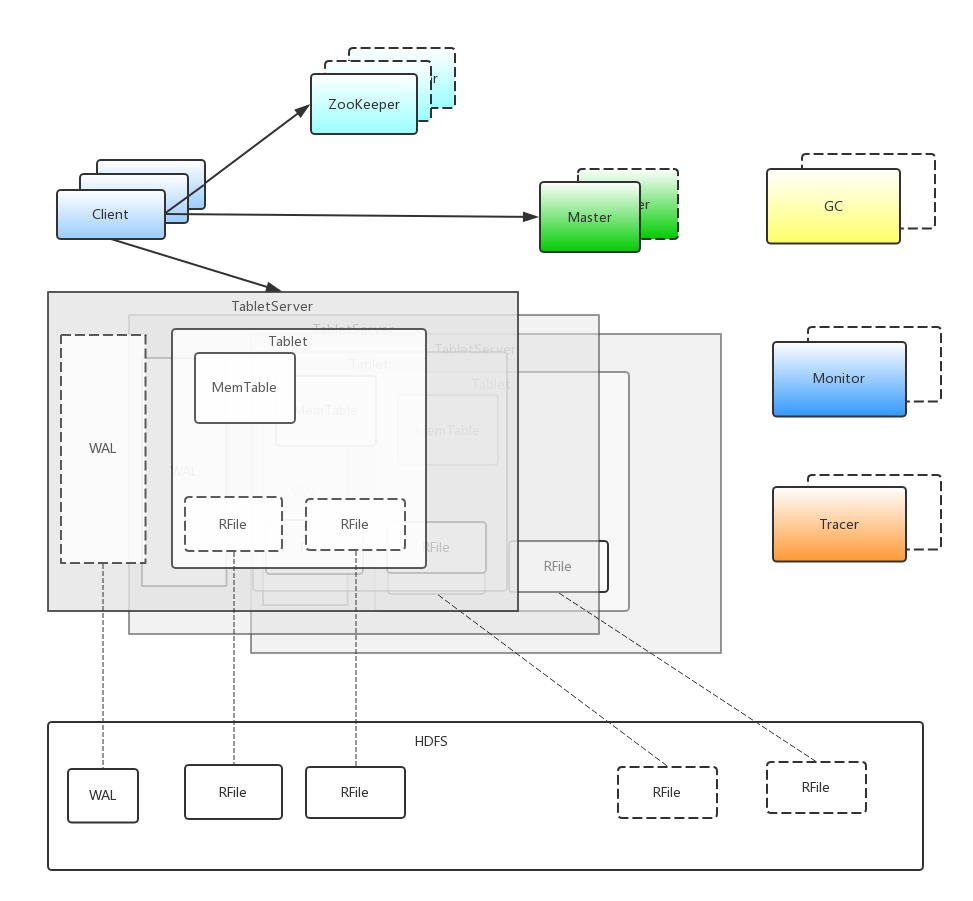
组件包括:
- Client:Accumulo includes a client library that is linked to every application. The client library contains logic for finding servers managing a particular tablet, and communicating with TabletServers to write and retrieve key-value pairs.
- zookeeper:检测进程的存活、任务的协调、灾备和配置的存储;
- Master:主服务,主要保存元数据的存储,分区分配,动态迁移及表操作;
- Tablet Server:提供数据读写的入口;
- Garbage Collector:对 RFile 进行合并清理;
- Tracer:追踪组件。支持分布式时间 API;
- Monitor:提供实例状态健康监控信息;
- hdfs:用于数据存储;
数据模型(Data Model)
Accumulo 提供比简单键值存储更丰富的数据模型,但不是完全关系数据库。数据表示为键值对,其中键和值由以下元素组成:

Key 和 Value 的所有元素都以字节数组表示,除了 Timestamp,它是一个 Long。 Accumulo 按照元素排序键,按字典顺序升序排列。时间戳按降序排列,以便相同 Key 的更高版本首先出现在顺序扫描中。表格由一组排序的键值对组成。
数据管理
Accumulo 数据存储在表中,划分成多个 tablet。tablet 基于行边界进行划分,一行的所有列数据都在同一个 tablet 中。Master 将 tablet 分配到一个 Tablet Sever 中。
相关图数据库
Gaffer
- Gaffer 是一个图形数据库框架。
- 它允许在节点和边上存储包含丰富属性的非常大的图。有多种存储选项可供选择,包括 Accumulo,Hbase 和 Parquet。(Gaffer is a graph database framework. It allows the storage of very large graphs containing rich properties on the nodes and edges. Several storage options are available, including Accumulo, Hbase and Parquet.)
- 最新版本:1.5.2(2018-6-7),社区活跃度较高(github:start 1419,fork:302)
- https://github.com/gchq/Gaffer
特性:
- 巨大节点/边上的快速查询;
- 快速持续摄取数据;
- 边和节点上存储任意 Java 对象;
- 内在提供的自动,可配置的聚合统计属性(比如:count,histograms,sketches)
- 丰富的时间汇总、数据过滤和转换功能;
- 良好的数据访问控制;
- 查询支持 hook ;
- 自动、基于规则的数据删除(用于过期数据删除);
- 使用 spark 提供更快速、灵活的数据分析;
- REST API
Graphulo
- MIT 开源项目;
- Apache Accumulo 数据库的 Java 库工具,用来支持数据库内的图算法分析;
- 提供服务器端稀疏矩阵数学原语,支持更高级别的图算法和分析。
- https://github.com/Accla/graphulo/
lumify
- 基于 accumulo 的开源大数据集成、分析、可视化平台;
- http://www.altamiracorp.com/index.php/lumify/
AccumuloGraph
以[Apache Accumulo]作为后端的 TinkerPop 图数据库 Blueprints Api 的实现,最新版本 0.2.1,已停更;
关键流程
写流程
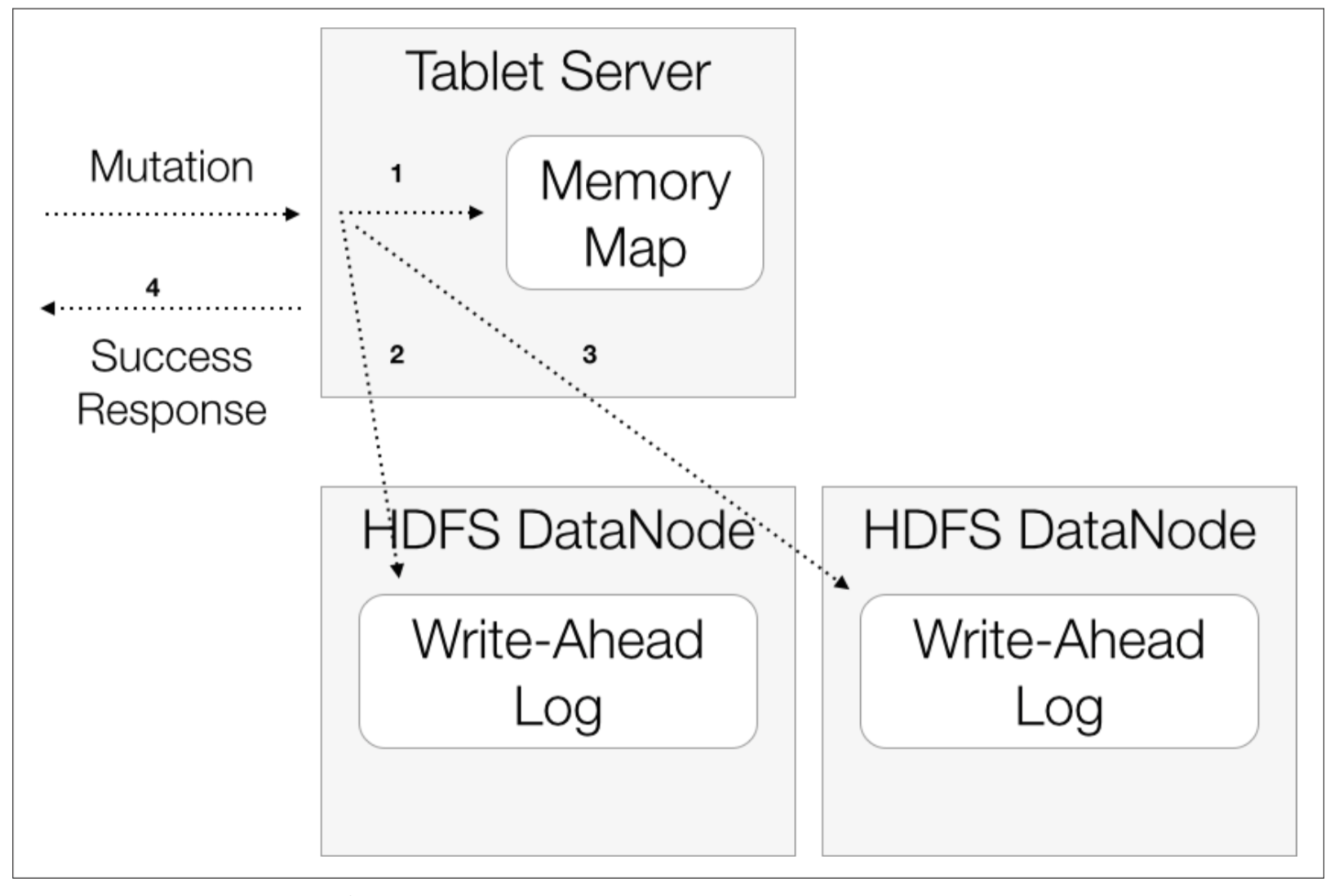
- 写 Memory Map;
- 写 WAL;
- 写返回;
读流程
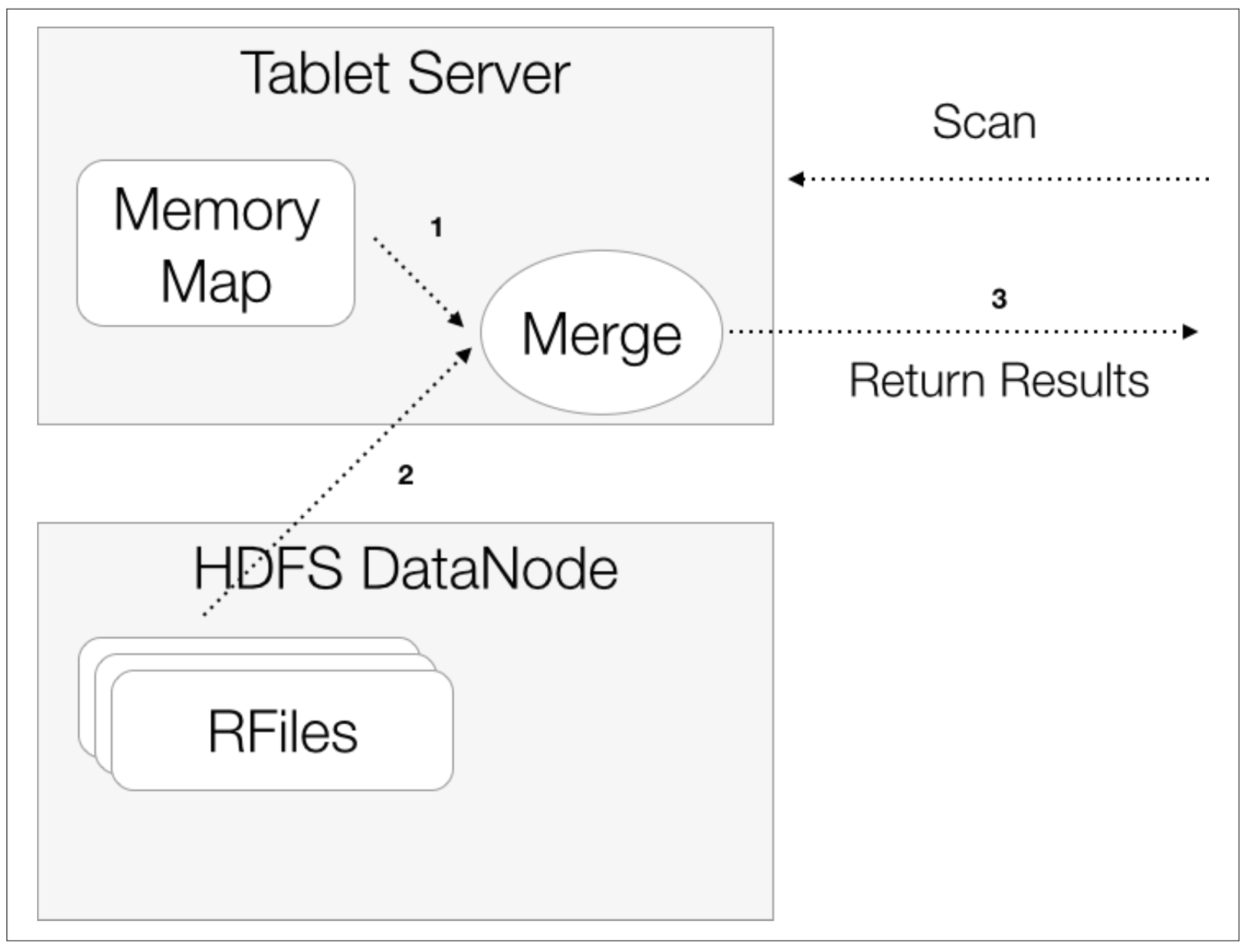
性能对比(Accumulo vs HBase)
吞吐量
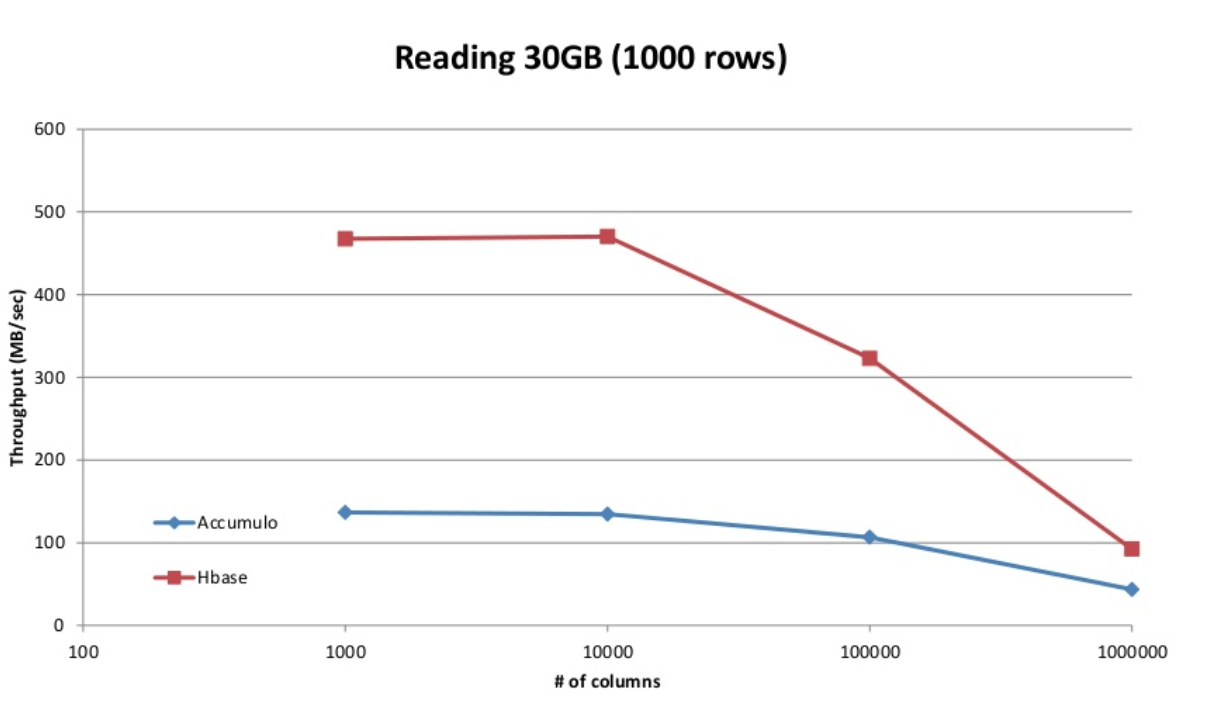
- 读
写
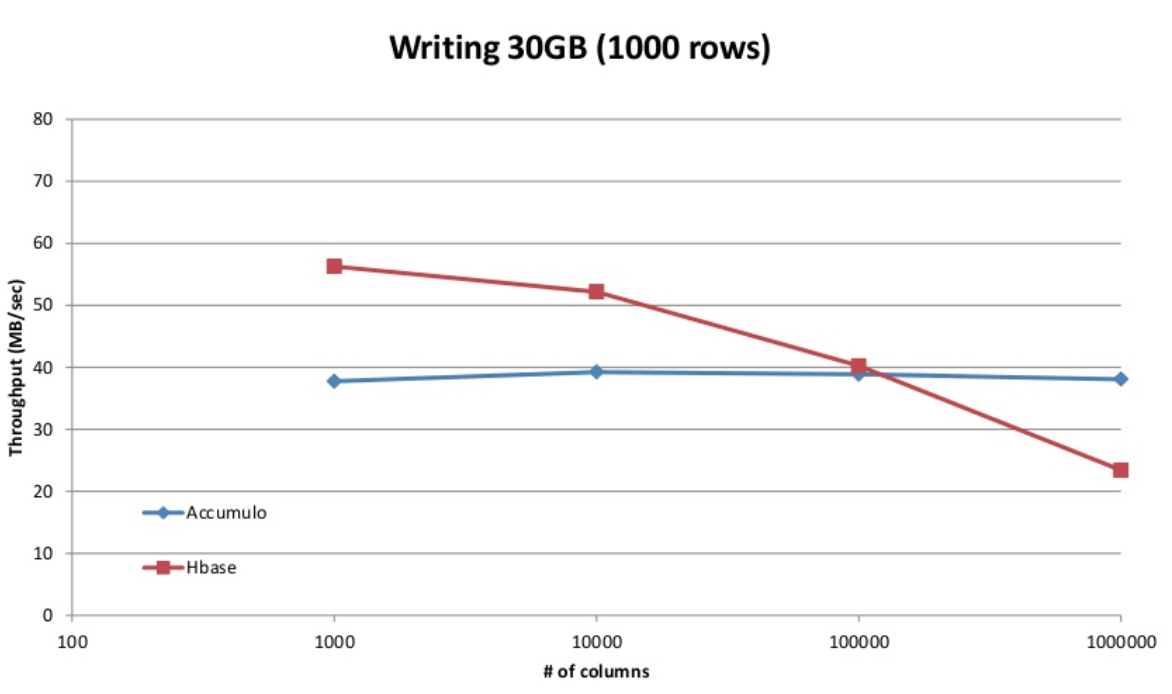
accumulo 支持 bigtable 的 locality group 特性,读写性能受 column 的数量影响较小,hbase 在列较少时读写性能优于 accumulo,但当列增大时,读写性能均有下降
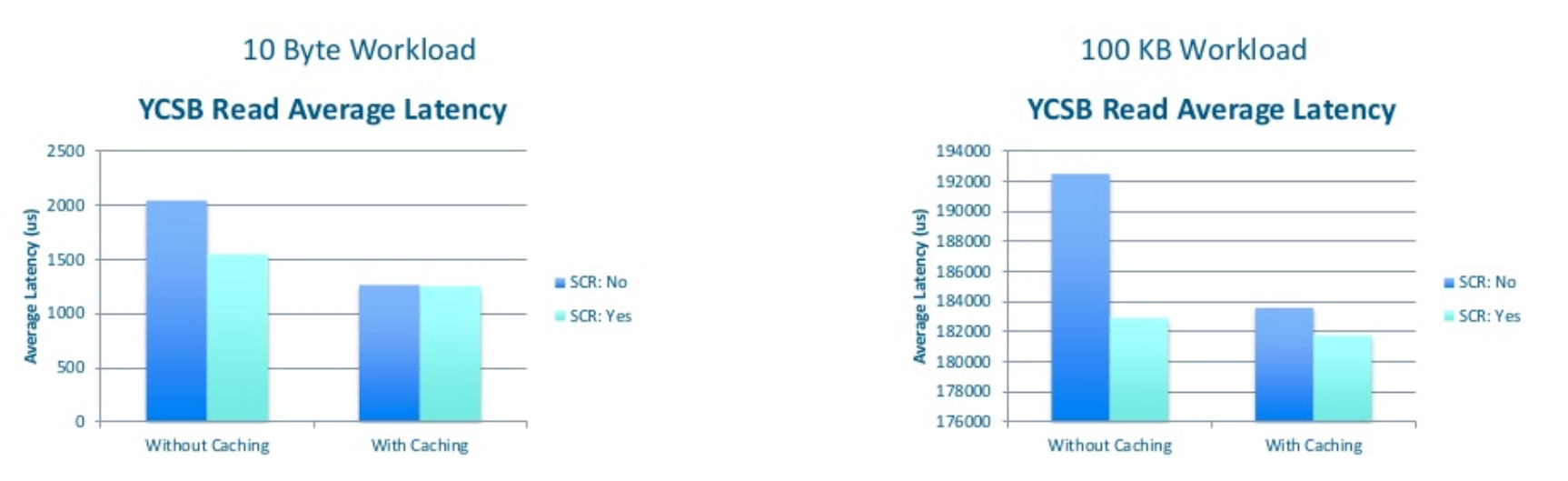
延迟
- accumulo

hbase
快速入门
安装
| |
配置
| |
参考
- The agency needed a scalable, secure database with which to store and analyze the never-ending stream of data it collects as part of its mandate “to understand the secret communications of our foreign adversaries.1” BigTable was the best database it could find to meet its requirements, but even it lacked cell-level security. As such, engineers at the NSA developed and natively incorporated cell-level security capabilities into its reverse-engineered version of BigTable, and Accumulo was born.
- http://bigdata-guide.blogspot.com/2014/01/hbase-versus-cassandra-versus-accumulo.html
- https://github.com/apache/accumulo-wikisearch
- http://www.pdl.cmu.edu/SDI/2013/slides/big_graph_nsa_rd_2013_56002v1.pdf
- https://quabase.sei.cmu.edu/mediawiki/index.php/Accumulo_Data_Model_Features
- https://quabase.sei.cmu.edu/mediawiki/index.php/Accumulo
- https://arstechnica.com/information-technology/2013/06/what-the-nsa-can-do-with-big-data/2/
- http://accumulosummit.com/2015/program/talks/hdfs-short-circuit-local-read-performance-benchmarking-with-apache-accumulo-and-apache-hbase/
- https://cloud.tencent.com/developer/article/1063206
- https://gigaom.com/2013/06/07/under-the-covers-of-the-nsas-big-data-effort/
- http://www.cena.com.cn/ia/20140919/56653.html
- http://www.cbdio.com/BigData/2016-09/01/content_5199203.htm
- NSA 向 Apache 提交安全的 NoSQL 資料庫
- https://blog.ippon.tech/use-cassandra-mongodb-hbase-accumulo-mysql/
- https://www.cloudera.com/products/open-source/apache-hadoop/apache-accumulo.htmlh
- http://wikibon.org/blog/breaking-analysis-accumulo-why-the-world-needs-another-nosql-database/