大数据技术总览
全貌
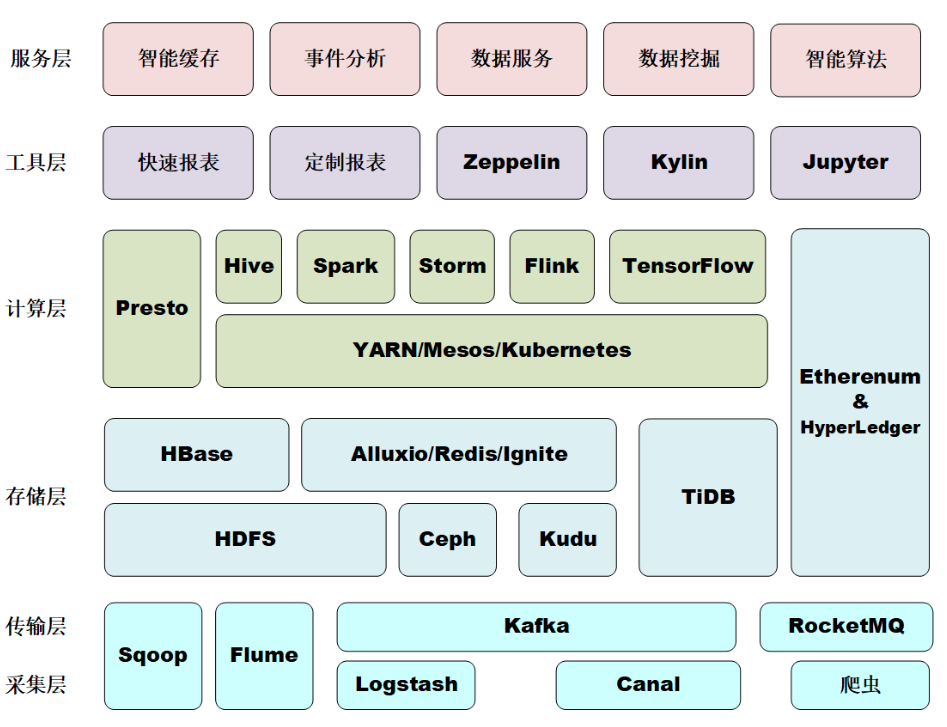
- 机器学习:Tensorflow,PyTorch,caffeine, mxnet
- 区块链:Etherenum,HyperLedger
- 图计算:Neo4j, Orientdb, thinkerpop, janusgraph
- 分析:Hive,Presto,kylin,impala,drill, phoniex
- 计算: Pig, Tez, Storm, Spark, Flink, Ray, Fluent
- 调度: Yarn, Mesos, k8s
- 检索:ElasticSearch, Bleve, Luence, Sphinx
- 消息: ZeroMQ, Rabbitmq, Kafka, Pulsar
- 数据湖: DeltaLake, hudi, iceberg
- 数据库:
- SQL: MySQL, PostgreSQL
- NoSQL: Mongodb,HBase, ClickHouse,
- NewSQL: Spanner, Aurora, TiDB, cockroachdb, YugabyteDB, dynamoDB,Cassandra, kudu, OceanBase, CrateDB, Pegasus, spanner, accumulo
- 存储引擎:RocksDB,LevelDB, Badger
- 协调服务:zookeeper, chubby, etcd
- 缓存: Redis, hazelcast, Alluxio, ignite, arrow, anna
- 存储: GFS, GlusterFS, hdfs, ceph, minio, chubaofs,ozone, Colossus
- 数据采集:sqoop, flume, canal, logstash, distributedlog, filebeat
- 数据格式:Parquet, Orc, Avro
- RPC: Grpc, thrift, Dubbo, rDSN,
- 一致性协议:
- 一致性算法:paxos,raft,zabxos, qjm,PacificA,quotum,hermers
- 共识算法:PBFT,PoW,PoS,DPos,epow
理论
- CAP理论: 分布式系统中 Availablity, Consistency, Partition 三者无法同时实现,最多只能实现其中的两个。
- FLP不可能定理:在完全异步的分布式网络中,故障容错问题无法被解决。
- ACID: 关系型数据库( 如 MySQL)多采用 ACID(Atomicity, Consistency, Isolation, Durability)理论,通过同步事务操作保证了强一致性;因节点较少(一般只有主从),可用性也比较一般;网络拓扑较为简单,而弱化了分区容错性。
- BASE: NoSQL 存储系统如 HBase 等多采用 BASE(Basically Available、Soft state、Eventually consistent)理论,通过多节点多副本保证了较高的可用性;另外因节点数增多、网络环境也更复杂,也考虑了网络分区容错性;但一致性较弱,只能保证最终一致性。
- CALM:
数据处理
- OLTP: 联机事务处理(On-Line Transaction Processing), 是事件驱动、面向应用的,也称为面向交易的处理过程。其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作的快速响应。例如银行类、电子商务类的交易系统就是典型的 OLTP 系统。
- OLAP: 联机实时分析(On-Line Analytical Processing), 面向数据分析的,也称为面向信息分析处理过程。它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。其特征是应对海量数据,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果,例如数据仓库是其典型的 OLAP 系统。
- HTAP: 混合事务和分析处理(Hybrid Transaction and Analytical Process),既可以应用于事务型数据库场景,亦可以应用于分析型数据库场景,实现实时业务决策。
| |
一致性算法
一致性算法用于分布式系统中用于保证数据一致性的算法。
一致性协议:
- Paxos:乱序提交
- Raft:Quorum 协议, Raft 顺序提交,etcd/tidb
- PacificA:主从复制协议, 顺序提交,
- QJM:
共识协议:
- PBFT :
大数据处理技术
- MPP (Massively Parallel Processing),即大规模并行处理,将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
- MapReduce:
- RDD:
存储格式
- Parquet:一种列式存储格式, 语言和平台无关,可以兼容 Hadoop 生态圈中大多数计算框架(Mapreduce、Spark 等),被多种查询引擎支持(Hive、Impala、Drill 等)。
- ORC:一种自描述的列式存储格式,产生自 Apache Hive,用于降低 Hadoop 数据存储空间和加速 Hive 查询速度。根据行组分割整个表,在每一个行组内进行按列存储。元数据使用 Protocol Buffers 序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被 Spark SQL、Presto 等查询引擎支持;
数据库存储类型
- 行存(Row-based): 数据按行为基础逻辑存储单元进行存储的,一行中的数据在存储介质中以连续存储形式存在。
- 列存(Column-based): 数据按列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。
存储
- GFS:google 第 1 代分布式文件系统,大文件,追加写。
- HDFS:GFS 的开源实现;
- GlusterFS: 开源分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数 PB 存储容量和处理数千客户端。GlusterFS 借助 TCP/IP 或 InfiniBand RDMA 网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS 基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
- Ceph:
- Minio:
- chubaofs:
缓存
- Redis: 内存 kv 缓存;
- Alluxio:开源的基于内存的分布式存储系统, 使应用程序能够通过一个公共接口连接到许多存储系统。
- Hazelcast: 分布式网格内存计算框架,提供了高效的、可扩展的分布式数据存储、数据缓存。
- Ignite:一个高性能、集成和分布式的内存计算和事务平台
- Arrow:跨平台的内存数据交换格式,解决系统到系统之间的数据传输问题。
协调服务
- ZooKeeper:
- Etcd:
- Consul:
调度
- Yarn
- Mesos
- K8S
数据库
- MySQL:
- MongoDB: 文档数据库;
- HBase:列式数据库
- Cassandra:
- kudu:由 Cloudera 开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu 支持水平扩展,使用 Raft 协议进行一致性保证,并且与 Cloudera Impala 和 Apache Spark 等当前流行的大数据查询和分析工具结合紧密。
- CrateDB:
- Pegasus: 米云存储团队开发的一个分布式 Key-Value 存储系统,Server 端完全采用 C++ 语言开发,使用 [PacificA](协议支持强一致性,使用 RocksDB作为单机存储引擎。
消息
- Kafka:
- zeromq:
- rabbitmq:
- Pulsar:
RPC
- rDSN: 高可用分布式系统核心,旨在提供一个健壮的、易于扩展、易于维护运营的分布式软件架构
- gRPC:
计算
- MapReduce:第一代大数据计算框架;
- Spark:基于内存的大数据计算框架
- Storm:
- Flink:流式计算引擎;
- Fluent: 一个数据驱动的计算框架。
分析
- Hive:数据仓库,基于HBase;
- Presto:OLTP分析数据库;
- Kylin:开源分布式分析引擎,提供 Hadoop 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,采用“预计算”的模式,用户只需要提前定义好查询维度,Kylin 将帮助我们进行计算,并将结果存储到 HBase 中,为海量数据的查询和分析提供亚秒级返回能力。
- Drill:低延迟的分布式海量数据(涵盖结构化、半结构化以及嵌套数据)交互式查询引擎,使用 ANSI SQL 兼容语法,支持本地文件、HDFS、HBase、MongoDB 等后端存储,支持 Parquet、JSON、CSV、TSV、PSV 等数据格式。本质上 Apache Drill 是一个分布式的 mpp(大规模并行处理)查询层。Drill 的目的在于支持更广泛的数据源,数据格式,以及查询语言。受 Google 的 Dremel 启发,Drill 满足上千节点的 PB 级别数据的交互式商业智能分析场景。
- Impala: