第3部分小结
整个第三部分,我们用前四回的内容讲述了进程调度机制,又用后三回内容讲述了 fork 函数的全部细节。先看进程调度机制。
进程调度机制
前四回内容循序渐进地讲述了进程调度机制的设计思路和细节。
进程调度的始作俑者,就是那个每 10ms 触发一次的定时器滴答。
而这个滴答将会给 CPU 产生一个时钟中断信号。
而这个中断信号会使 CPU 查找中断向量表,找到操作系统写好的一个时钟中断处理函数 do_timer。
do_timer 会首先将当前进程的 counter 变量 -1,如果 counter 此时仍然大于 0,则就此结束。
但如果 counter = 0 了,就开始进行进程的调度。
进程调度就是找到所有处于 RUNNABLE 状态的进程,并找到一个 counter 值最大的进程,把它丢进 switch_to 函数的入参里。
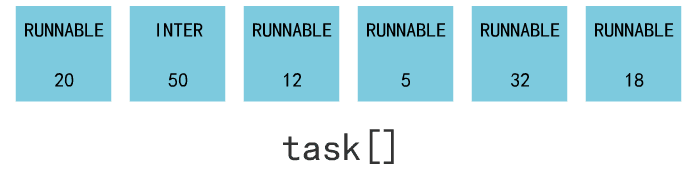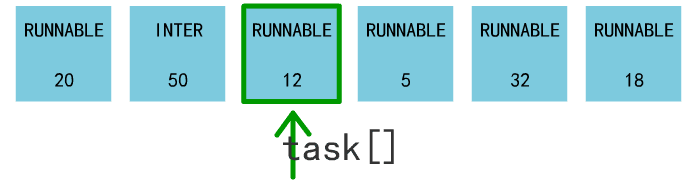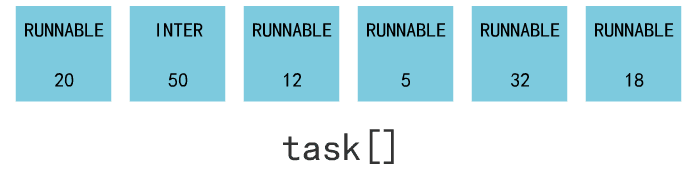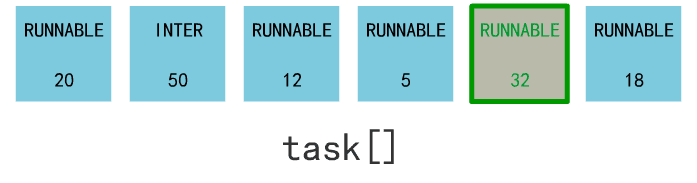
switch_to 这个终极函数,会保存当前进程上下文,恢复要跳转到的这个进程的上下文,同时使得 CPU 跳转到这个进程的偏移地址处。
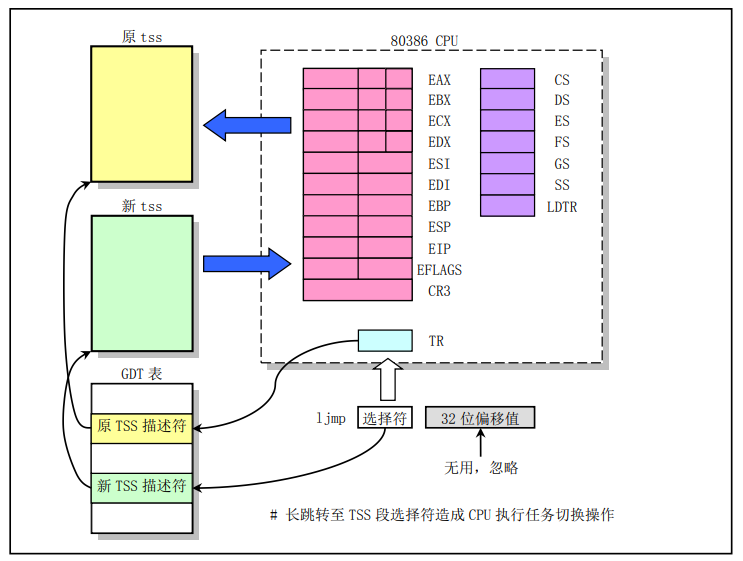
上图来源于《Linux内核完全注释V5.0》
接着,这个进程就舒舒服服地运行了起来,等待着下一次时钟中断的来临。
聊完进程调度机制,我们再看看 fork 函数的原理。
fork
后三回内容讲述了 fork 函数的全部细节。
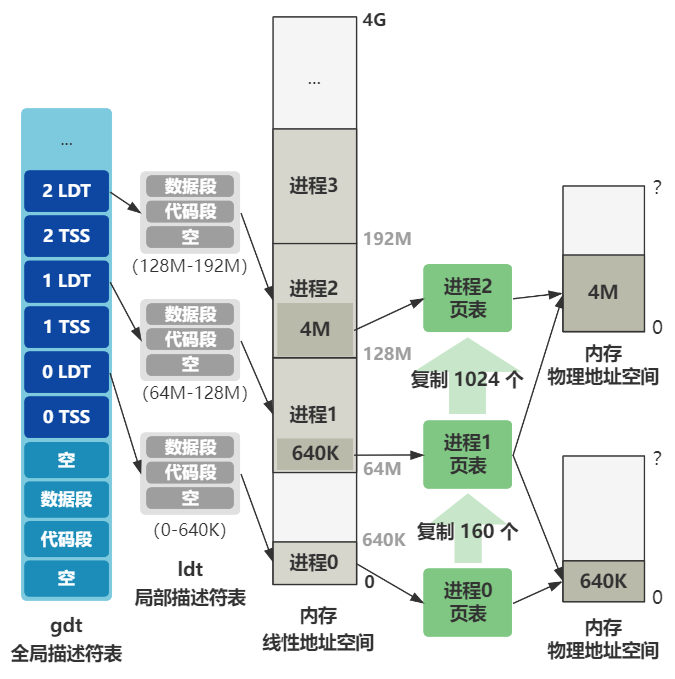
用一张图来表示的话,就是。
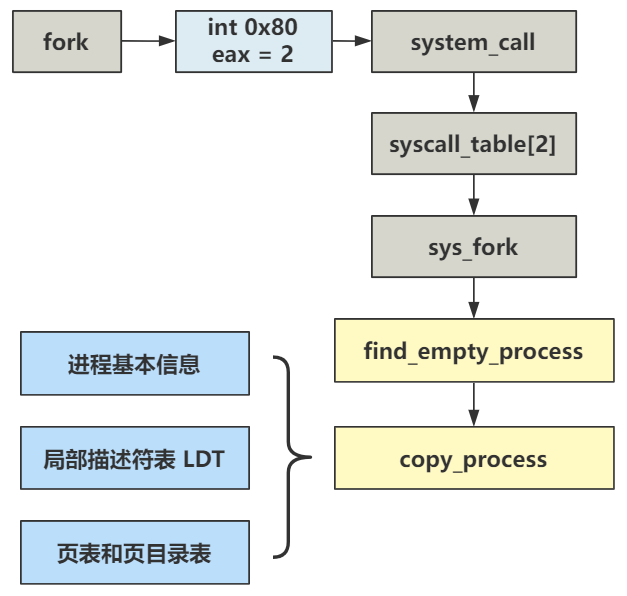
其中 copy_process 是复制进程的关键,总共分三步来。
第一,原封不动复制了一下 task_struct。
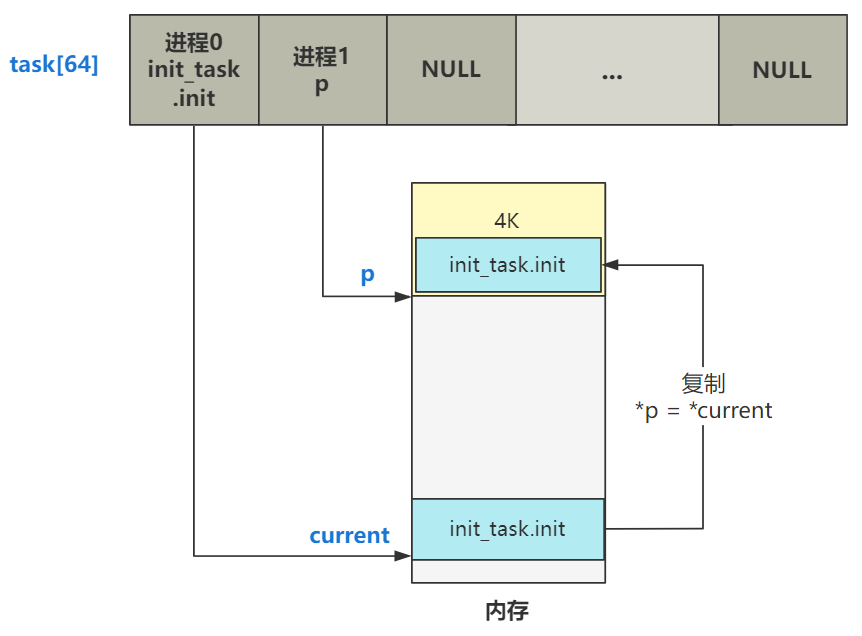
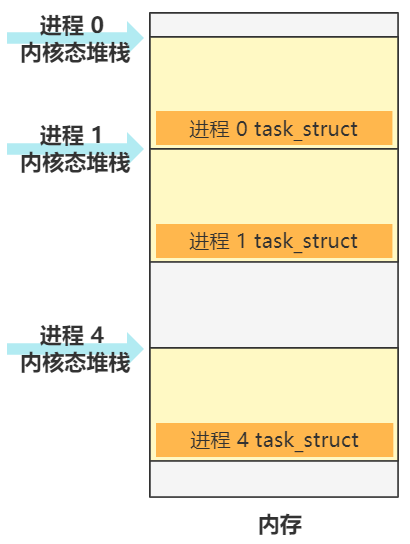
并且覆盖了一些基本信息,包括元信息和一些寄存器的信息。其中比较重要的是将内核态堆栈栈顶指针的指向了自己进程结构所在 4K 内存页的最顶端。
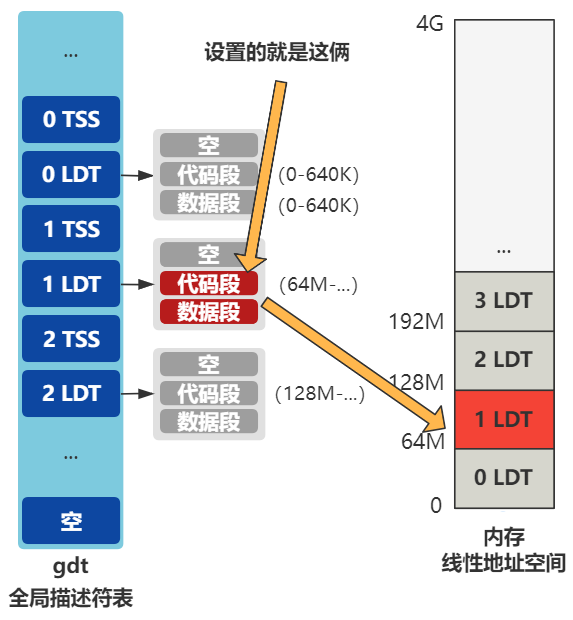
第二,LDT 的复制和改造,使得进程 0 和进程 1 分别映射到了不同的线性地址空间。
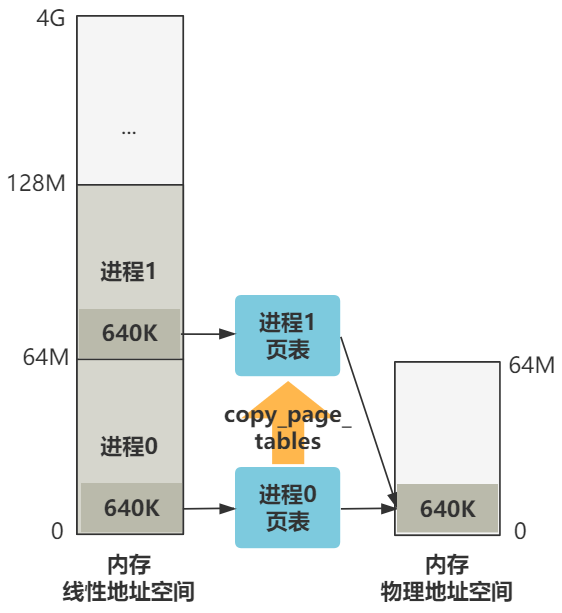
第三,页表的复制,使得进程 0 和进程 1 又从不同的线性地址空间,被映射到了相同的物理地址空间。
最后,将新老进程的页表都变成只读状态,为后面写时复制的缺页中断做准备。
这一部分的 fork 函数只用于进程 0 创造进程 1 的过程,而之后的新进程创建,比如进程 1 里 fork 创建进程 2,也都是这样的套路。
整个核心函数 copy_process 的代码如下。
| |
注意图中的两个标黄的代码。
开始复制进程信息的时候,由于进程 1 的结构还没弄好,此时如果进程调度到了进程 1,那就坏事了。
所以一开始把进程 1 的状态先设置为 TASK_UNINTERRUPTIBLE,使得其不会被进程调度算法选中。
而所有复制工作完成后,进程 1 就拥有了运行的内容,进程基本信息也有了,进程的内存规划也完成了。
此时就把进程设置为 TASK_RUNNING,允许被 CPU 调度。
看到这行代码,其实我们也可以很自信地认为,到这里进程 1 的初步建立工作已经圆满结束,可以达到运行在 CPU 上的标准了。
第四部分的展望
那我们此时又该回到之前的 main 方法,是不是都忘了最初的目的了?哈哈。
| |
看,下一行代码,是 init。
fork 只是把进程 1 搞成可以在 CPU 中运行的进程,之后创建新进程,都可以用这个 fork 方法。
不过进程 1 具体要做什么事情呢?那就是 init 这个函数的故事了。
虽然就一行代码,但这里的事情可多了去了,我们先看一下整体结构。我已经把单纯的日志打印和错误校验逻辑去掉了。
| |
是不是看着还挺复杂?
不过还好,我们几乎已经把计算机体系结构,和操作系统的设计思想,通过前面的源码阅读,不知不觉建立起来了。
接下来的工作,就是基于这些建立好的能力,站在巨人的肩膀上,做些更伟大的事情!
说伟大其实也没什么伟大的,就是最终建立好一个人机交互的 shell 程序,无限等待用户输入的命令。