CPU基础
简介
- CPU(Center Process Unit, 中央处理单元)是计算机的核心部件,在冯诺依曼体系架构中,位于中心位置,负责进行算术运算。
冯诺依曼架构
冯诺依曼架构对通用图灵模型的一种工程架构;
冯诺依曼架构由以下5个部分:
控制器:控制计算指令的运行;
运算器:按指令执行运算;
存储器:存储运算所需数据和结果;
输入设备:接收输入数据;
输出设备:输出运算结果;
冯诺依曼体系架构的中心是由控制器、运算器组成的计算核心(即CPU),数据围绕着计算核心依次流动,进行计算;
控制器、运算器都是由基本的逻辑门电路组成的,由时钟脉冲进行驱动;
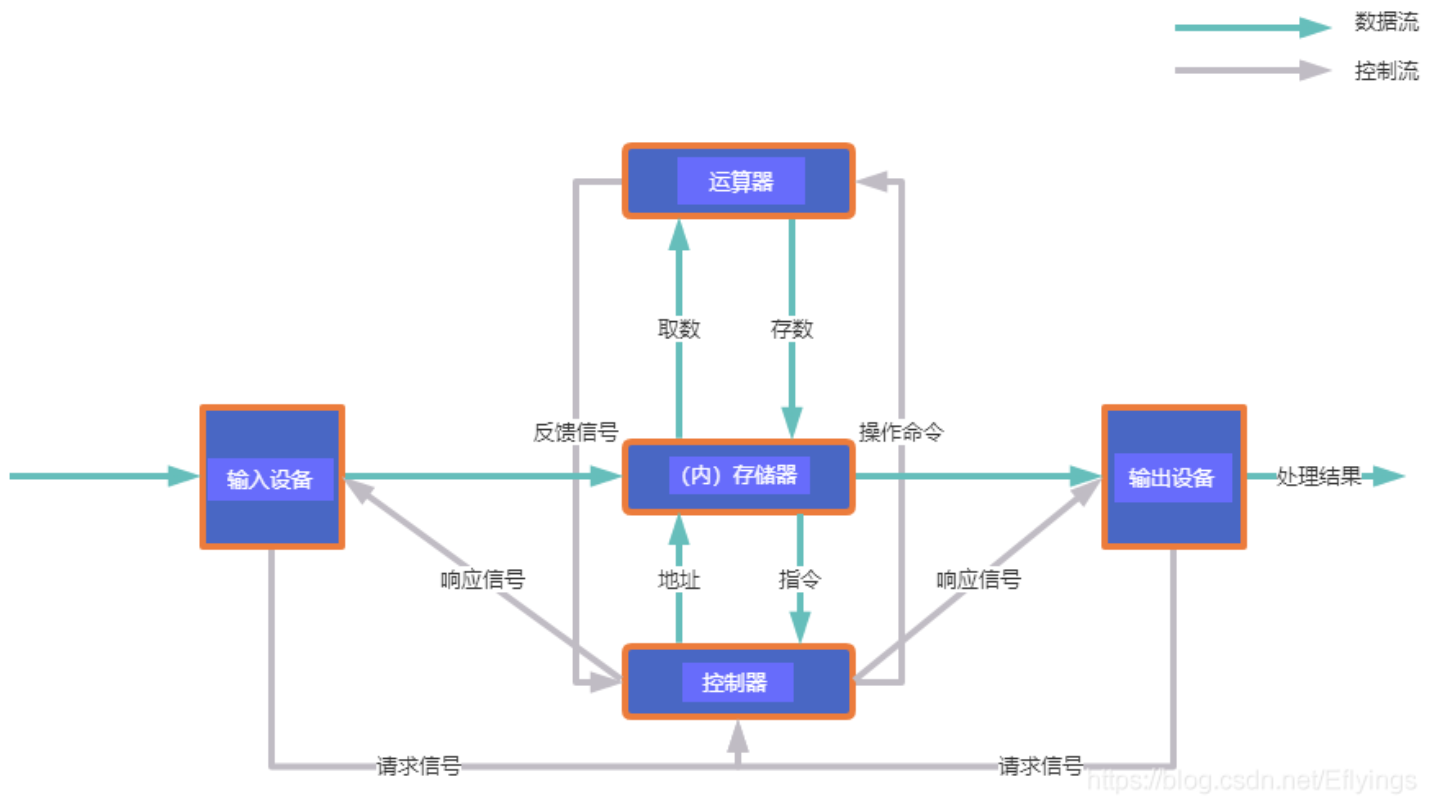
单核CPU架构
单核CPU由控制器、运算器、寄存器(存储器的一种)组成;
控制器从寄存器中取得输入数据输入到运算器(有时没有输入,无须读取寄存器),运算器计算的结果也会输出到寄存器中;
寄存器也是有简单的逻辑电路组成的,其存取周期也是一个CPU时钟周期;
寄存器中的数据是从内存中载入的;

CPU缓存
由于CPU和执行速度(时钟周期);
内存由大量的存储部件组成(由逻辑门组成),由于涉及到大量的逻辑部件操作和寻址等相关操作,所以访问速度和CPU之间存在较大差距,为此CPU内部引入了多级的缓存,以提高CPU运行效率
CPU分为三级缓存: 每个CPU都有L1,L2缓存,但是L3缓存是多核公用的。
L1 Cache (一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。它是封装在CPU芯片内部的高速缓存,用于暂时存储CPU运算时的部分指令和数据,存取速度与CPU主频相近。内置的L1高速缓存的容量和结构对CPU的性能影响较大,一级缓存容量越大,则CPU处理速度就会越快,对应的CPU价格也就越高。一般服务器的CPU的L1缓存的容量通常在32-4096K
L2 Cache (二级缓存)是CPU外部的高速缓存,由于L1高速缓存的容量限制,为了再次提高CPU的运算速度,在CPU外部放置一高速存储器,即二级缓存。像一级缓存一样,二级缓存越大,则CPU处理速度就越快,整台计算机性能也就越好。一级缓存和二级缓存都位于CPU和内存之间,用于缓解高速CPU与慢速内存速度匹配问题。
L3 Cache (三级缓存) 都是内置的,它的作用是进一步降低内存延迟,同时提升大数据量计算时处理器的性能。具有较大L3缓存的处理器,能提供更有效的文件系统缓存行为及较短的消息和队列长度。一般多核共享一个L3缓存
CPU查找数据的顺序为: CPU -> L1 -> L2 -> L3 -> 内存 -> 硬盘
多核CPU内存架构
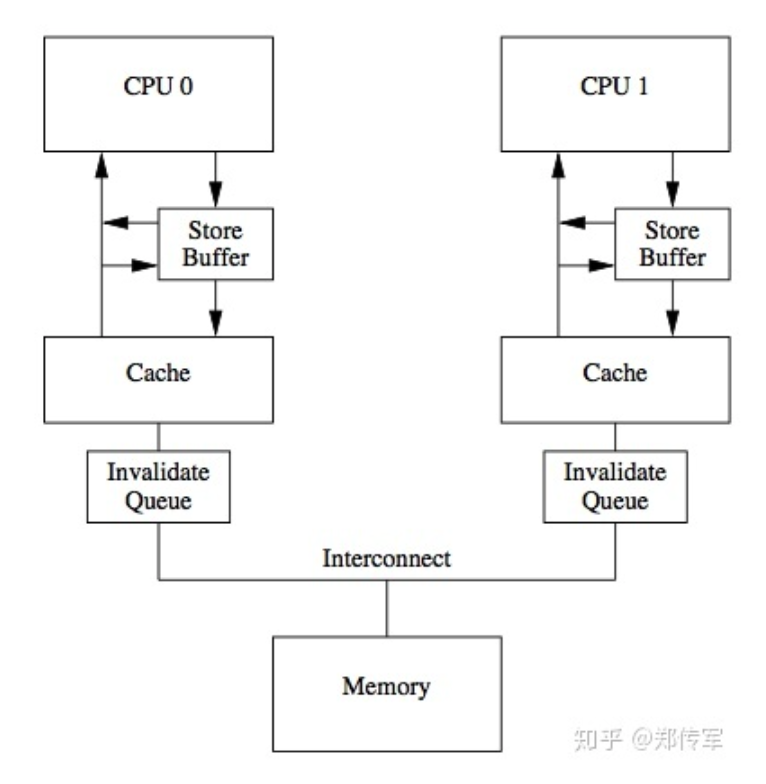
- 多核cpu中,每个cpu core都拥有独占的控制器、运算器、寄存器、L1-Cache、L2-Cahce;

多处理器系统中,各个核心共享主存,可同时访问主存。但是CPU和物理主存之间的通信速度相对于CPU的处理速度来说是相当慢的,为了能够减少这种消耗,每个CPU都有自己的内部缓存,根据一些额规则将主存中的数据读取到内部缓存中,以加快频繁的读取的速度。寄存器、缓存和主内存构建了内存体系。
寄存器:在每个核心里面,都有寄存器,访问寄存器只需一个时钟周期,编译器会将本地变量以及函数参数分配在寄存器上面,当使用超线程技术( hyperthreading)时,这些寄存器可以在超线程协同下共享
写缓存(store buffer):写缓存位于核心和L1 cache之间,是一个FIFO的队列。有store buffer的cpu不会去执行写指令,而是把写指令交给store buffer去操作,cpu接着执行后面的指令(下面会讲到)。
L1缓存:L1缓存是核心本地的一个缓存,被分为32k数据缓存和32k指令缓存,访问需要3个时钟周期
L2缓存:L2缓存也是cpu核心的本地缓存,位于L1和L3缓存之间,其大小为256k,数据和指令同时存储。其主要功能是为L1和L3缓存提供高效的内存队列。L2缓存的延迟需要12个时钟周期
L3缓存:位于同一插槽的核心共享L3缓存,L3拥有L1和L2缓存的数据,虽然浪费了空间,但是拦截了访问核心的L1和L2缓存,减轻了L1和L2的压力
CacheLine
Cache Line。缓存基本上来说就是把后面的数据加载到离自己近的地方,对于CPU来说,它是不会一个字节一个字节的加载的,因为这非常没有效率,一般来说都是要一块一块的加载的,对于这样的一块一块的数据单位,术语叫“Cache Line”,一般来说,一个主流的CPU的Cache Line 是 64 Bytes(也有的CPU用32Bytes和128Bytes),64Bytes也就是16个32位的整型,这就是CPU从内存中捞数据上来的最小数据单位。
缓存一致性协议(MESI协议)
多核时代下并发操作是很正常的现象,操作系统必须要有一些机制和原语来保证某些基本操作的原子性,例如想要保证读写一个字节是原子的,那么就可以有两种机制实现:总线锁定和缓存一致性
- 总线锁:前端总线(CPU总线)是所有CPU与芯片组连接的主干道,负责CPU与外界所有部件的通信,包括高速缓存、内存、北桥,其控制总线向各个部件发送控制信号,如LOCK#信号,这时,其他CPU就不能操作缓存了该共享变量内存地址的缓存,也就是阻塞了其他CPU,使该处理器可以独享此共享内存。总线锁的开销很大;
缓存一致性协议给缓存行(cache line,通常是64字节)定义了一个状态,用了描述该缓存行是否被多处理器共享、是否修改。所以缓存一致性也被称为MESI协
独占(exlcusive):仅当前处理器拥有该缓存行,并且没有修改过,是最新值。
共享(share):有多个处理器拥有该缓存行,每个处理器都没有修改过缓存,是最新的值。
修改(modified):缓存行被修改过了,需要写回主存,并通知其他拥有者该缓存已失效。
失效(invalid):缓存行被其他处理器修改过,该值不是最新的值,需要读取主存上最新的值。
当CPU需要读取数据时,如果其缓存行的状态是I的,则需要从内存中读取,并把自己状态变成S,如果不是I,则可以直接读取缓存中的值,但在此之前,必须要等待其他CPU的监听结果,如其他CPU也有该数据的缓存且状态是M,则需要等待其把缓存更新到内存之后,再读取。
当CPU需要写数据时,只有在其缓存行是M或者E的时候才能执行,否则需要发出特殊的RFO指令(Read Or Ownership,这是一种总线事务),通知其他CPU置缓存无效(I),这种情况下性能开销是相对较大的。在写入完成后,修改其缓存状态为M。

一个Cache加载一个变量的时候,是Exclusive状态,
当这个变量被第二个Cache加载,更改状态为Shared;
这时候一个CPU要修改变量, 就把状态改为Modified,并且Invalidate其他的Cache,
其他的Cache再去读这个变量,达到一致。
内存屏障
大部分处理器都会提供以下3种内存屏障:
store barrier:用来保证写操作会被其他core看到,保证写操作,以阻塞的方式
load barrier:用于保证读到最新的数据,仅仅保存读操作,以阻塞的方式
full barrier:保证指令之后的读写操作不会重排序到指令之前,以阻塞的方式
读屏障,清空本地的invalidate queue,保证之前的所有load都已经生效;
写屏障,清空本地的store buffer,使得之前的所有store操作都生效。
阻止编译器重排,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
C++内存屏障
| 枚举值 | 定义规则 |
|---|---|
| memory_order_relaxed | 不对执行顺序做任何保证 |
| memory_order_acquire | 本线程中,所有后续的读操作必须在本条原子操作完成后执行 |
| memory_order_release | 本线程中,所有之前的写操作完成后才能执行本条原子操作 |
| memory_order_acq_rel | 同时包含 memory_order_acquire 和 memory_order_release标记 |
| memory_order_consume | 本线程中,所有后续的有关本原子类型的操作,必须在本条原子操作完成之后执行 |
| memory_order_seq_cst | 全部存取都按顺序执行 |
volatile 关键字
声明为volatile变量编译器会强制要求读内存,相关语句不会直接使用上一条语句对应的的寄存器内容,而是重新从内存中读取;