AF_XDP
简介
AF_XDP是一种用于高性能包处理的地址簇(Address Family)。
使用XDP程序中的XDP_REDIRECT操作,可以使用bpf_redirect_map()函数将入口帧重定向到其他启用XDP的网络设备。 AF_XDP套接字使XDP程序可以将帧重定向到用户空间应用程序中的内存缓冲区。
可以通过socket()系统调用创建AF_XDP socket (XSK)。每个XSK涉及两个ring:RX ring和TX ring。一个socket可以从RX ring上接收报文,并发送到TX ring。这两个rings分别通过socket选项XDP_RX_RING 和XDP_TX_RING进行注册。每个socket必须至少具有其中一个ring。RX或TX ring描述符指向内存域中的data buffer,称为UMEM。RX和TX可以共享相同的UMEM,这样一个报文无需在RX和TX之间进行拷贝。此外,如果一个报文由于重传需要保留一段时间,则指向该报文的描述符可以指向另外一个报文,这样就避免了数据的拷贝。基本流程如下:
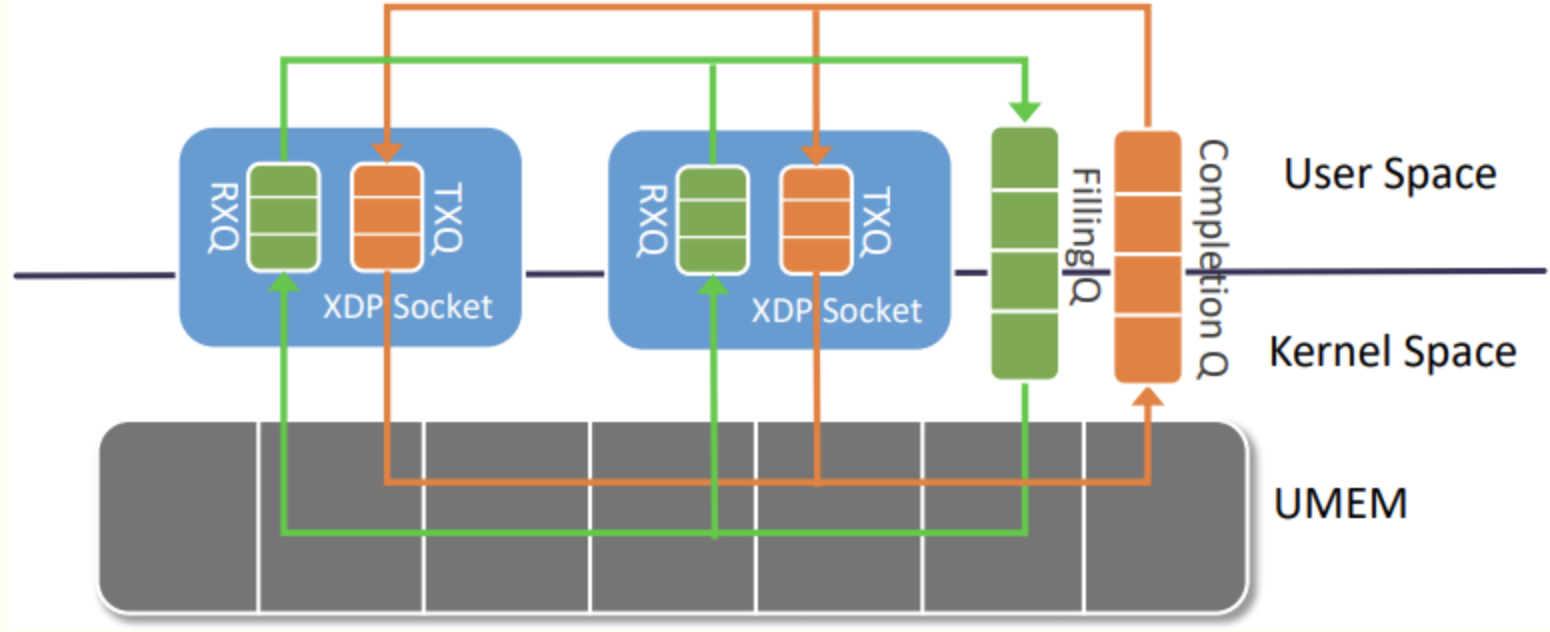
UMEM包含一系列大小相同的chunks,ring中的描述符通过引用帧的地址来引用该帧,该地址为整个UMEM域的偏移量。用户空间会使用合适的方式(malloc,mmap,大页内存等)为UMEM分配内存,然后使用使用新的socket选项XDP_UMEM_REG将内存域注册到内核中。UMEM也包含两个ring:FILL ring和COMPLETION ring。应用会使用FILL ring下发addr,让内核填写RX包数据。一旦接收到报文,RX ring会引用这些帧。COMPLETION ring包含内核传输完的帧地址,且可以被用户空间使用,用于TX或RX。因此COMPLETION ring中的帧地址为先前使用TX ring传输的地址。总之,RX和FILL ring用于RX路径,TX和COMPLETION ring用于TX路径。
最后会使用bind()调用将socket绑定到一个设备以及该设备指定的队列id上,绑定没有完成前无法传输流量。
最后会使用bind()调用将socket绑定到一个设备以及该设备指定的队列id上,绑定没有完成前无法传输流量。
可以在多个进程间共享UMEM 。如果一个进程需要更新UMEM,则会跳过注册UMEM和其对应的两个ring的过程。在bind调用中设置XDP_SHARED_UMEM 标志,并提交该进程期望共享UMEM的XSK,以及新创建的XSK socket。新进程会在其共享UMEM的RX ring中接收到帧地址引用。注意,由于ring的结构是单生产者/单消费者的,新的进程的socket必须创建独立的RX和TX ring。同样的原因,每个UMEM也只能有一个FILL和COMPLETION ring。每个进程都需要正确地处理好UMEM。
那么报文是怎么从XDP程序分发到XSKs的呢?通过名为XSKMAP(完整名为BPF_MAP_TYPE_XSKMAP`) BPF map。用户空间的应用可以将一个XSK放到该map的任意位置,然后XDP程序就可以将一个报文重定向到该map中指定的索引中,此时XDP会校验map中的XSK确实绑定到该设备和ring号。如果没有,则会丢弃该报文。如果map中的索引为空,也会丢弃该报文。因此,当前的实现中强制要求必须加载一个XDP程序(以及保证XSKMAP存在一个XSK),这样才能通过XSK将流量传送到用户空间。
AF_XDP可以运行在两种模式上:XDP_SKB和XDP_DRV。如果驱动不支持XDP,则在加载XDP程序是需要明确指定使用XDP_SKB,XDP_SKB模式使用SKB和通用的XDP功能,并将数据复制到用户空间,是一种适用于任何网络设备的回退模式。 如果驱动支持XDP,将使用AF_XDP代码提供更好的性能,但仍然会将数据拷贝到用户空间的操作。
术语
UMEM: UMEM是一个虚拟的连续内存域,分割为相同大小的帧。
一个UMEM会关联一个netdev以及该netdev的队列id。通过XDP_UMEM_REG socket选项进行创建和配置(chunk大小,headroom,开始地址和大小)。通过bind()系统调用将一个UMEM绑定到一个netdev和队列id。umem的基本结构如下:
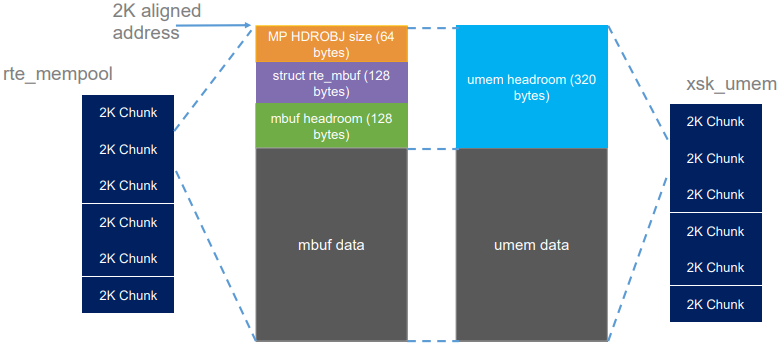
一个AF_XDP为一个链接到一个独立的UMEM的socket,但一个UMEM可以有多个AF_XDP socket。为了共享一个通过socket A创建的UMEM,socket B可以将结构体sockaddr_xdp中的成员sxdp_flags设置为XDP_SHARED_UMEM,并将A的文件描述符传递给结构体sockaddr_xdp的成员sxdp_shared_umem_fd。
UMEM有两个单生产者/单消费者ring,用于在内核和用户空间应用程序之间转移UMEM帧。
Rings
有4类不同类型的ring:FILL, COMPLETION, RX 和TX,所有的ring都是单生产者/单消费者,因此用户空间的程序需要显示地同步对这些rings进行读/写的多进程/线程。
UMEM使用2个ring:FILL和COMPLETION。每个关联到UMEM的socket必须有1个RX队列,1个TX队列或同时拥有2个队列。如果配置了4个socket(同时使用TX和RX),那么此时会有1个FILL ring,1个COMPLETION ring,4个TX ring和4个RX ring。
ring是基于首(生产者)尾(消费者)的结构。一个生产者会在结构体xdp_ring的producer成员指出的ring索引处写入数据,并增加生产者索引;一个消费者会结构体xdp_ring的consumer成员指出的ring索引处读取数据,并增加消费者索引。
可以通过_RING setsockopt系统调用配置和创建ring,使用mmap(),并结合合适的偏移量,将其映射到用户空间
ring的大小需要是2次幂。
UMEM Fill Ring
FILL ring用于将UMEM帧从用户空间传递到内核空间,同时将UMEM地址传递给ring。例如,如果UMEM的大小为64k,且每个chunk的大小为4k,那么UMEM包含16个chunk,可以传递的地址为0到64k。
传递给内核的帧用于ingress路径(RX rings)。
用户应用也会在该ring中生成UMEM地址。注意,如果以对齐的chunk模式运行应用,则内核会屏蔽传入的地址。即,如果一个chunk大小为2k,则会屏蔽掉log2(2048) LSB的地址,意味着2048, 2050 和3000都将引用相同的chunk。如果用户应用使用非对其的chunk模式运行,那么传入的地址将保持不变。
UMEM Completion Ring
COMPLETION Ring用于将UMEM帧从内核空间传递到用户空间,与FILL ring相同,使用了UMEM索引。
已经发送的从内核空间传递到用户空间的帧还可以被用户空间使用。
用户应用会消费该ring种的UMEM地址。
RX Ring
RX ring位于socket的接收侧,ring中的每个表项都是一个xdp_desc 结构的描述符。该描述符包含UMEM偏移量(地址)以及数据的长度。
如果没有帧从FILL ring传递给内核,则RX ring中不会出现任何描述符。
用户程序会消费该ring中的xdp_desc描述符。
TX Ring
TX Ring用于发送帧。在填充xdp_desc(索引,长度和偏移量)描述符后传递给该ring。
如果要启动数据传输,则必须调用sendmsg(),未来可能会放宽这种限制。
用户程序会给TX ring生成xdp_desc 描述符。
XSKMAP / BPF_MAP_TYPE_XSKMAP
在XDP侧会用到类型为BPF_MAP_TYPE_XSKMAP 的BPF map,并结合bpf_redirect_map()将ingress帧传递给socket。
用户应用会通过bpf()系统调用将socket插入该map。
注意,如果一个XDP程序尝试将帧重定向到一个与队列配置和netdev不匹配的socket时,会丢弃该帧。即,如果一个AF_XDP socket绑定到一个名为eth0,队列为17的netdev上时,只有当XDP程序指定到eth0且队列为17时,才会将数据传递给该socket。参见samples/bpf/获取例子
配置标志位和socket选项
XDP_COPY 和XDP_ZERO_COPY bind标志
当绑定到一个socket时,内核会首先尝试使用零拷贝进行拷贝。如果不支持零拷贝,则会回退为使用拷贝模式。即,将所有的报文拷贝到用户空间。但如果想强制指定一种特定的模式,则可以使用如下标志:如果给bind调用传递了XDP_COPY,则内核将强制进入拷贝模式;如果没有使用拷贝模式,则bind调用会失败,并返回错误。相反地,XDP_ZERO_COPY 将强制socket使用零拷贝或调用失败。
XDP_SHARED_UMEM bind 标志
该表示可以使多个socket绑定到系统的UMEM,但仅能使用系统的队列id。这种模式下,每个socket都有其各自的RX和TX ring,但UMEM只能有一个FILL ring和一个COMPLETION ring。为了使用这种模式,需要创建第一个socket,并使用正常模式进行绑定。然后创建第二个socket,含一个RX和一个TX(或二者之一),但不会创建FILL 或COMPLETION ring(与第一个socket共享)。在bind调用中,设置XDP_SHARED_UMEM选项,并在sxdp_shared_umem_fd中提供初始socket的fd。以此类推。
那么当接收到一个报文后,应该上送到那个socket呢?答案是由XDP程序来决定。将所有的socket放到XDP_MAP中,然后将报文发送给数组中索引对应的socket。下面展示了一个简单的以轮询方式分发报文的例子:
| |
注意,由于只有一个FILL和一个COMPLETION ring,且是单生产者单消费者的ring,需要确保多处理器或多线程不会同时使用这些ring。libbpf没有提供原子同步功能。
当多个socket绑定到相同的umem时,libbpf会使用这种模式。然而,需要注意的是,需要在xsk_socket__create调用中提供XSK_LIBBPF_FLAGS__INHIBIT_PROG_LOAD libbpf_flag,然后将其加载到自己的XDP程序中(因为libbpf没有内置路由流量功能)。
XDP_USE_NEED_WAKEUP bind标志
该选择支持在FILL ring和TX ring中设置一个名为need_wakeup的标志,用户空间作为这些ring的生产者。当在bind调用中设置了该选项,如果需要明确地通过系统调用唤醒内核来继续处理报文时,会设置need_wakeup 标志。
如果将该标志设置给FILL ring,则应用需要调用poll(),以便在RX ring上继续接收报文。如,当内核检测到FILL ring中没有足够的buff,且NIC的RX HW RING中也没有足够的buffer时会发生这种情况。此时会关中断,这样NIC就无法接收到任何报文(由于没有足够的buffer),由于设置了need_wakeup,这样用户空间就可以在FILL ring上增加buffer,然后调用poll(),这样内核驱动就可以将这些buffer添加到HW ring上继续接收报文。
如果将该标志设置给TX ring,意味着应用需要明确地通知内核发送位于TX ring上的报文。可以通过调用poll(),或调用sendto()完成。
可以在samples/bpf/xdpsock_user.c中找到例子。在TX路径上使用libbpf辅助函数的例子如下:
| |
建议启用该模式,由于减少了TX路径上的系统调用的数目,因此可以在应用和驱动运行在同一个(或不同)core的情况下提升性能。
XDP_{RX|TX|UMEM_FILL|UMEM_COMPLETION}_RING setsockopts
这些socket选项分别设置RX, TX, FILL和COMPLETION ring的描述符数量(必须至少设置RX或TX ring的描述符大小)。如果同时设置了RX和TX,就可以同时接收和发送来自应用的流量;如果仅设置了其中一个,就可以节省相应的资源。如果需要将一个UMEM绑定到socket,需要同时设置FILL ring和COMPLETION ring。如果使用了XDP_SHARED_UMEM标志,无需为除第一个socket之外的socket创建单独的UMEM,所有的socket将使用共享的UMEM。注意ring为单生产者单消费者结构,因此多进程无法同时访问同一个ring。参见XDP_SHARED_UMEM章节。
使用libbpf时,可以通过给xsk_socket__create函数的rx和tx参数设置NULL来创建Rx-only和Tx-only的socket。
如果创建了一个Tx-only的socket,建议不要在FILL ring中放入任何报文,否则,驱动可能会认为需要接收数据(但实际上并不是这样的),进而影响性能。
XDP_UMEM_REG setsockopt
该socket选项会给一个socket注册一个UMEM,其对应的区域包含了可以容纳报文的buffer。该调用会使用一个指向该区域开始处的指针,以及该区域的大小。此外,还有一个UMEM可以切分的chunk大小参数(目前仅支持2K或4K)。如果一个UMEM区域的大小为128K,且chunk大小为2K,意味着该UMEM域最大可以有128K / 2K = 64个报文,且最大的报文大小为2K。
还有一个选项可以在UMEM中设置每个buffer的headroom。如果设置为N字节,意味着报文会从buffer的第N个字节开始,为应用保留前N个字节。最后一个选项为标志位字段,会在每个UMEM标志中单独处理。
XDP_STATISTICS getsockopt
获取一个socket丢弃信息,用于调试。支持的信息为:
| |
XDP_OPTIONS getsockopt
获取一个XDP socket的选项。目前仅支持XDP_OPTIONS_ZEROCOPY,用于检查是否使用了零拷贝。
从AF_XDP的特性上可以看到其局限性:不能使用XDP将不同的流量重定向的多个AF_XDP socket上,原因是每个AF_XDP socket必须绑定到物理接口的TX队列上。大多数的物理和仿真HW的每个接口仅支持一个RX/TX队列,因此当该接口上绑定了一个AF_XDP后,后续的绑定操作都将失败。仅有少数HW支持多RX/TX队列,且通常仅有2/4/8个队列,无法扩展给cloud中的上百个容器使用。
TC
除了XDP,BPF还可以在网络数据路径的内核tc(traffic control)层之外使用。上文已经给出了XDP和TC的区别。
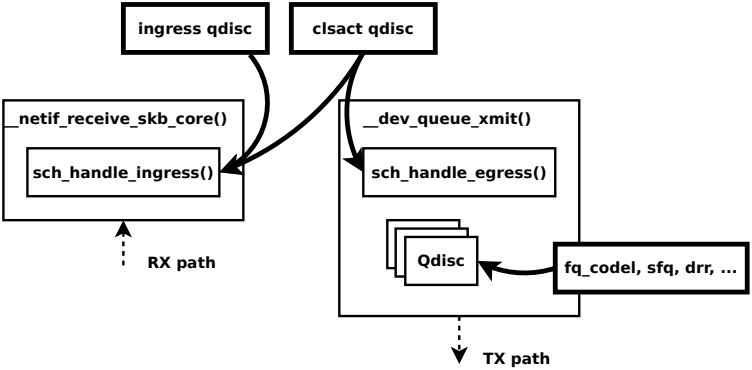
ingresshook:__netif_receive_skb_core() -> sch_handle_ingress()egresshook:__dev_queue_xmit() -> sch_handle_egress()
运行在tc层的BPF程序使用的是 cls_bpf (cls即Classifiers的简称)分类器。在tc中,将BPF的附着点描述为一个"分类器",这个词有点误导,因此它少描述了cls_bpf的所支持的功能。即一个完整的可编程的报文处理器不仅可以读取skb的元数据和报文数据,还可以对其进行任意修改,最后终止tc的处理,并返回裁定的action(见下)。cls_bpf可以认为是一个自包含的,可以管理和执行tc BPF程序的实体。
cls_bpf可以包含一个或多个tc BPF程序。通常,在传统的tc方案中,分类器和action模块是分开的,每个分类器可以附加一个或多个action,一旦匹配到分类器时就会执行action。但在现代软件数据路径中使用这种模式的tc处理复杂的报文时会遇到扩展性问题。由于附加到cls_bpf的tc BPF程序是完全自包含的,因此可以有效地将解析和操作过程融合到一个单元中。幸好有了cls_bpf的direct-action模式,该模式下,仅需要返回tc action裁定结果并立即结束处理流即可,可以在网络数据流中实现可扩展的可编程报文处理流程,同时避免了action的线性迭代。cls_bpf是tc层中唯一能够实现这种快速路径的“分类器”模块。
与XDP BPF程序类似,tc BPF程序可以在运行时通过cls_bpf自动更新,而不会中断任何网络流或重启服务。
cls_bpf可以附加的tc ingress和egree钩子都通过一个名为sch_clsact的伪qdisc进行管理。由于该伪qdisc可以同时管理ingress和egress的tc钩子,因此它是ingress qdisc的超集(也可直接替换)。对于__dev_queue_xmit()中的tc的egress钩子,需要注意的是,它不是在内核的qdisc root锁下运行的。因此,tc ingress和egress钩子都以无锁的方式运行在快速路径中,且这两个钩子都禁用了抢占,并运行在RCU读取侧。
通常在egress上会存在附着到网络设备上的qdisc,如sch_mq,sch_fq,sch_fq_codel或sch_htb,其中有些是可分类的qdisc(包含子类),因此会要求一个报文分类机制来决定在哪里解复用数据包。该过程通过调用tcf_classify()进行处理,进而调用tc分类器(如果存在)。cls_bpf也可以附加并用于如下场景:一些在qdisc root锁下的操作可能会收到锁竞争的影响。sch_clsact qdisc的egress钩子出现在更早的时间点,但它不属于这个锁的范围,因此作完全独立于常规的egress qdiscs。因此,对于sch_htb这样的情况,sch_clsact qdisc可以通过qdisc root锁之外的tc BPF执行繁重的包分类工作,通过在这些 tc BPF 程序中设置 skb->mark 或 skb->priority ,这样 sch_htb 只需要一个简单的映射即可,不需要在root锁下执行代价高昂的报文分类工作,通过这种方式可以减少锁竞争。
在sch_clsact结合cls_bpf的场景下支持offloaded tc BPF程序,这种情况下,先前加载的BPF程序是从SmartNIC驱动程序jit生成的,以便在NIC上以本机方式运行。只有在direct-action模式下运行的cls_bpf程序才支持offloaded。cls_bpf仅支持offload一个单独的程序(无法offload多个程序),且只有ingress支持offload BPF程序。
一个cls_bpf实例可以包含多个tc BPF程序,如果是这种情况,那么TC_ACT_UNSPEC程序返回码可以继续执行列表中的下一个tc BPF程序。然而,这样做的缺点是,多个程序需要多次解析相同的报文,导致性能下降。
返回码
tc的ingress和egress钩子共享相同的action来返回tc BPF程序使用的裁定结果,定义在 linux/pkt_cls.h系统头文件中:
| |
系统头文件中还有一些以TC_ACT_*开头的action变量,可以被两个钩子使用。但它们与上面的语义相同。即,从tc BPF的角度来看TC_ACT_OK和TC_ACT_RECLASSIFY的语义相同,三个TC_ACT_stelled、TC_ACT_QUEUED和TC_ACT_TRAP操作码的语义也是相同的。因此,对于这些情况,我们只描述 TC_ACT_OK 和 TC_ACT_STOLEN 操作码。
从TC_ACT_UNSPEC开始,表示"未指定的action",用于以下三种场景:i)当一个offloaded tc程序的tc ingress钩子运行在cls_bpf的位置,则该offloaded程序将返回TC_ACT_UNSPEC;ii)为了在多程序场景下继续执行cls_bpf中的下一个BPF程序,后续的程序需要与步骤i中的offloaded tc BPF程序配合使用,但出现了一个非offloaded场景下运行的tc BPF程序;iii)TC_ACT_UNSPEC还可以用于单个程序场景,用于告诉内核继续使用skb,不会产生其他副作用。TC_ACT_UNSPEC与TC_ACT_OK类似,两者都会将skb通过ingress向上传递到网络栈的上层,或者通过egress向下传递到网络设备驱动程序,以便在egress进行传输。与TC_ACT_OK的唯一不同之处是,TC_ACT_OK基于tc BPF程序设定的classid来设置skb->tc_index,而 TC_ACT_UNSPEC 是通过 tc BPF 程序之外的 BPF上下文中的 skb->tc_classid 进行设置。
TC_ACT_SHOT通知内核丢弃报文,即网络栈上层将不会在ingress的skb中看到该报文,类似地,这类报文也不会在egress中发送。TC_ACT_SHOT和TC_ACT_STOLEN本质上是相似的,仅存在部分差异:TC_ACT_SHOT会通知内核已经通过kfree_skb()释放skb,且会立即给调用者返回NET_XMIT_DROP;而TC_ACT_STOLEN会通过consume_skb()释放skb,并给上层返回NET_XMIT_SUCCESS,假装传输成功。perf的报文丢弃监控会记录kfree_skb()的操作,因此不会记录任何因为TC_ACT_STOLEN丢弃的报文,因为从语义上说,这些 skb 是被消费或排队的而不是被丢弃的。
最后TC_ACT_REDIRECT action允许tc BPF程序通过bpf_redirect()辅助函数将skb重定向到相同或不同的设备ingress或egress路径上。通过将报文导入其他设备的ingress或egress方向,可以最大化地实现BPF的报文转发功能。使用该方式不需要对目标网络设备做任何更改,也不需要在目标设备上运行另外一个cls_bpf实例。
加载tc BPF程序
假设有一个名为prog.o的tc BPF程序,可以通过tc命令将该程序加载到网络设备山。与XDP不同,它不需要依赖驱动将BPF程序附加到设备上,下面会用到一个名为em1的网络设备,并将程序附加到em1的ingress报文路径上。
| |
第一步首先配置一个clsact qdisc。如上文所述,clsact是一个伪造的qdisc,与ingress qdisc类似,仅包含分类器和action,但不会提供实际的队列功能,它是附加bpf分类器所必需的。clsact 提供了两个特殊的钩子,称为ingress和egress,分类器可以附加到这两个钩子上。ingress和egress钩子都位于网络数据路径的中央接收和发送位置,每个经过设备的报文都会经过此处。ingees钩子通过内核的__netif_receive_skb_core() -> sch_handle_ingress()进行调用,egress钩子通过__dev_queue_xmit() -> sch_handle_egress()进行调用。
将程序附加到egress钩子上的操作为:
| |
clsact qdisc以无锁的方式处理来自ingress和egress方向的报文,且可以附加到一个无队列虚拟设备上,如连接到容器的veth设备。
在钩子之后,tc filter命令选择使用bpf的da(direct-action)模式。推荐使用并指定da模式,基本上意味着bpf分类器不再需要调用外部tc action模块,所有报文的修改,转发或其他action都可以通过附加的BPF程序来实现,因此处理速度更快。
到此位置,已经附加bpf程序,一旦有报文传输到该设备后就会执行该程序。与XDP相同,如果不使用默认的section名称,则可以在加载期间进行指定,例如,下面指定的section名为foobar:
| |
iptables2的BPF加载器允许跨程序类型使用相同的命令行语法。
附加的程序可以使用如下命令列出:
| |
prog.o:[ingress]的输出说明程序段ingress通过文件prog.o进行加载,且bpf运行在direct-action模式下。上面两种情况附加了程序id和tag,其中后者表示对指令流的hash,该hash可以与目标文件或带有堆栈跟踪的perf report等相关。最后,id表示系统范围内的BPF程序的唯一标识符,可以使用bpftool来查看或dump附加的BPF程序。
tc可以附加多个BPF程序,它提供了其他可以链接在一起的分类器。但附加一个BPF程序已经可以完全满足需求,因为通过da(direct-action)模式可以在一个程序中实现所有的报文操作,意味着BPF程序将返回tc action裁定结果,如TC_ACT_OK, TC_ACT_SHOT等。为了获得最佳性能和灵活性,推荐使用这种方式。
在上述show命令中,在BPF的相关输出旁显示了pref 49152 和handle 0x1。如果没有通过命令行显式地提供,会自动生成的这两个输出。perf表明了一个优先级数字,即当附加了多个分类器时,将会按照优先级上升的顺序执行这些分类器。handle表示一个标识符,当一个perf加载了系统分类器的多个实例时起作用。由于在BPF场景下,一个程序足矣,perf和handle通常可以忽略。
只有在需要自动替换附加的BPF程序的情况下,才会推荐在初始化加载前指定pref和handle,这样在以后执行replace操作时就不必在进行查询。创建方式如下:
| |
对于原子替换,可以使用(来自文件prog.o中的foobar section的BPF程序)如下命令来更新现有的ingress钩子上的程序
| |
最后,为了移除所有ingress和egress上附加的程序,可以使用如下命令:
| |
为了移除网络设备上的整个clsact qdisc,即移除掉ingress和egress钩子上附加的所有程序,可以使用如下命令:
| |
如果NIC和驱动也像XDP BPF程序一样支持offloaded,则tc BPF程序也可以是offloaded的。Netronome的nfp同时支持两种类型的BPF offload。
| |
如果出现了如上错误,则表示首先需要通过ethtool的hw-tc-offload来启动tc硬件offload:
| |
in_hw标志表示程序已经offload到了NIC中。
注意不能同时offload tc和XDP BPF,必须且只能选择其中之一。