CPU异常
原文:https://os.phil-opp.com/cpu-exceptions/
原作者:@phil-opp
译者:倪广野
触发CPU异常的情况多种多样,例如:访问非法内存地址或执行非法指令(除以零)等。为了应对CPU异常,我们需要建立中断描述符表(interrupt descriptor table),它列举了不同异常所对应的处理函数(handler functions)。在博文的最后,我们的内核(kernel)可以捕获断点异常(breakpoint exceptions)并且恢复CPU的正常运行。
[TOC]
概述
异常的发生标志着当前正在执行的指令出现了问题。例如:指令试图除以0的时候,CPU会抛出一个异常。当异常发生,CPU会中断(interrupt)它当前的流程,并立即调用该类型异常对应的处理函数。
在x86体系结构中,有大约20种不同的CPU 异常类型。常见的如下:
-
缺页错误(Page Fault):缺页错误发生在非法的内存访问操作中。例如:当前指令试图访问没有映射的内存页或试图写入只读的内存页。
-
非法操作码(Invalid Opcode):非法操作码发生在当前指令不正确的情况下。例如:试图在不支持 SSE 指令集 的老旧CPU上使用该指令集。
-
通用保护错误(General Protection Fault):这是一个触发原因相对宽泛的异常。试图在用户态程序中执行特权指令或试图写入配置寄存器的保留位等非法访问操作均会触发该异常。
-
双重异常(Double Fault):异常发生后,CPU会调用对应的异常处理函数。在调用过程中如果发生另一个异常,CPU会触发双重异常。双重异常也会在找不到对应的异常处理函数的情况下发生。
-
三重异常(Triple Fault):如果异常发生在CPU调用双重异常处理函数的过程中,这会导致严重的三重异常。我们不能捕获或者处理三重异常。大多数处理器会选择复位并重启操作系统。
你可以在这里找到所有的CPU异常列表。
中断描述符表(interrupt descriptor table)
为了捕获并处理CPU异常,我们需要建立所谓的中断描述符表(interrupt descriptor table,IDT)。在IDT中,我们可以为每种异常指定一个处理函数。硬件会直接使用这张表,所以我们需要遵循提前约定好的格式。IDT的每一项(entry)必须是16字节的结构:
| Type | Name | Description |
|---|---|---|
| u16 | 函数指针 [0:15] | 处理函数(handler function)指针的低16位 |
| u16 | GDT 选择子 | global descriptor table 代码段的选择子 |
| u16 | 选项参数 | 参见下文 |
| u16 | 函数指针 [16:31] | 处理函数(handler function)指针的中间16位 |
| u32 | 函数指针 [32:63] | 处理函数(handler function)指针剩下的32位 |
| u32 | 保留位 |
选项参数必须是下面的结构:
| Bits | Name | Description |
|---|---|---|
| 0-2 | 中断栈表索引 | 0: 不切换栈, 1-7:当处理函数被调用时,切换到中断栈表(Interrupt Stack Table)的第n个栈 |
| 3-7 | 保留位 | |
| 8 | 0: 中断门, 1: 陷阱门 | 如果这个bit被设置为0,处理函数被调用的时候,中断会被禁用。 |
| 9-11 | 必须为1 | |
| 12 | 必须为0 | |
| 13‑14 | 特权等级描述符 (DPL) | 允许调用该处理函数的最小特权等级。 |
| 15 | Present |
每个异常都拥有提前约定好的IDT索引。例如:非法操作码的表索引是6,而缺页错误的的表索引是14。因此,硬件可以找到每种异常对应的中断描述符表的条目(interrupt descriptor table entry, IDT entry)。OSDev wiki页面的Exception Table的“Vector nr.”列展示了所有异常的IDT索引。
当异常发生时,CPU大致遵循下面的流程:
-
将一些寄存器的内容压入栈中,包括当前指令的指针和RFLAGS寄存器的内容(我们会在文章的后续部分用到这些值)。
-
读取中断描述符表(IDT)中对应的条目。例如:缺页错误发生时,CPU会读取IDT的第十四个条目。
-
检查这个条目是否存在,如果没有则升级为双重错误(double fault)。
-
如果条目是一个中断门(第40个bit没有被设置为1),则禁用硬件中断。
-
装载指定的GDT 选择子到CS段。
-
跳转到指定的处理函数。
现在不要担心第四、五步,我们会在未来的文章中研究GDT和硬件中断。
一个IDT类型(An IDT Type)
我们选择使用x86_64 crate中的 InterruptDescriptorTable 结构体,而不是创建自己的 IDT 类型:
|
|
InterruptDescriptorTable结构体的字段都是idt::Entry类型,这种类型是一种代表IDT条目字段的结构体(见上面的示例)。类型参数F定义了预期的处理函数类型。我们可以发现上面的条目字段需要 HandlerFunc 或 HandlerFuncWithErrCode 参数。缺页错误甚至拥有它独有的处理函数类型:PageFaultHandlerFunc 。
首先,我们探讨一下 HandlerFunc 类型:
|
|
HandlerFunc 是 extern "x86-interrupt" fn 的类型别名。extern 关键字定义了一个外部调用约定( foreign calling convention ),它经常被用于链接C语言代码(extern "C" fn)。那么,x86-interrupt调用约定是什么呢?
中断调用约定( The Interrupt Calling Convention)
CPU异常与函数调用非常相似:CPU跳转到调用函数的第一条指令并执行它。然后,CPU跳转到返回地址并继续执行函数的调用者函数(parent function)。
然而,异常和函数调用有一个重要的区别:函数调用是被编译器生成的 call 指令主动发起,而
异常可以发生在所有指令的执行过程中。为了理解这个区别的重要性,我们需要更进一步地研究函数调用。
调用约定 Calling conventions 明确规定了函数调用的细节。例如,它规定了函数参数的位置( 寄存器还是函数栈)和结果的返回方式。在x86_64 Linux体系中,C语言函数调用适用下面的规则(在System V ABI中规定):
- 前六个整数参数会被放在寄存器中传递:
rdi,rsi,rdx,rcx,r8,r9 - 剩下的参数被放在栈中传递
- 结果被放在
rax和rdx中返回
Rust 没有遵顼C ABI (事实上,Rust甚至没有规定的ABI),所以这些规则仅仅适用于声明了 extern "C" fn 的函数。
Preserved and Scratch 寄存器
调用约定( calling convention)将寄存器分为两个部分: preserved 和 scratch 寄存器。
在函数调用的过程中,preserved寄存器的值必须保持不变。所以,被调用的函数(callee)必须保证会在返回以前会主动复原这些寄存器的原始值,才可以修改这些寄存器的值。因此,这些寄存器被称为被调用者保存寄存器(callee-saved,译者注:也就是AKA非易失性寄存器)。通行的模式是在函数的开始保存这些寄存器的值到函数栈中,并在函数马上返回的时候复原他们。
相比之下,被调用的函数(callee)可以无约束地修改 scratch寄存器。如果调用者函数希望在函数调用的过程中保留 scratch寄存器的值,它需要在调用函数之前备份和复原 scratch寄存器的值(例如将这些值压入栈中)。所以,这些寄存器被称为调用者寄存器(caller-saved,译者注:也就是AKA易失性寄存器)。
在x86_64架构中,C语言调用约定明确规定了下面的 preserved and scratch 寄存器:
| preserved 寄存器 | scratch 寄存器 |
|---|---|
rbp, rbx, rsp, r12, r13, r14, r15 |
rax, rcx, rdx, rsi, rdi, r8, r9, r10, r11 |
| callee-saved | caller-saved |
编译器遵顼这些规定生成二进制字节码。例如:绝大多数函数地字节码开始于push rbp指令,这个指令会备份rbp寄存器地值到函数栈中(因为这是一个callee-saved寄存器)。
保存所有寄存器
与函数调用形成鲜明对比的是,异常可以发生在所有指令的执行过程中。大多数情况下,我们甚至不能识别出编译器生成的代码是否会引起异常。例如,编译器不能预见到一个指令是否会引起栈溢出或缺页错误。
既然不能预见到异常的发生时机,我们自然也无法做到提前备份任何寄存器的值。这意味着我们不能使用依赖于 caller-saved 寄存器的调用约定去处理异常。然而,我们需要一个会保存所有寄存器值的调用约定。x86-interrupt调用约定恰恰能够保证所有寄存器会在函数调用结束以前复原到原始值。
这并不意味着所有寄存器的值会在函数开始时被保存到函数栈中。相反,编译器(生成的代码)只会备份被函数覆盖的寄存器的值。在这种方式下,较短的函数编译生成的二进制字节码会非常高效,也就是只使用尽可能少的寄存器。
中断栈帧( The Interrupt Stack Frame)
在寻常的函数调用(call指令执行)中,CPU跳转到相应的函数之前会将返回地址压入到函数栈中。在函数返回(ret指令执行)的时候,CPU会弹出并跳转到这个返回地址。所以,寻常的函数调用栈帧会如下图所示:

然而,异常和中断处理函数并不能将返回地址压入到函数栈中,因为中断处理函数往往运行在不同的上下文(栈指针,CPU flags等)中。相反,在异常发生的时候,CPU会执行以下步骤:
- 对齐栈指针:中断可以发生在任何指令的执行过程中,栈指针自然也可能是任何值。然而,一些CPU指令集(e.g. 一些 SSE指令集)需要栈指针在16字节边界上对齐,因此CPU会在中断之后靠右对齐栈指针。
- 切换栈(在某种情况下):CPU特权等级发生改变的时候,栈会被切换,例如CPU 异常发生在用户态程序的时候。用所谓的中断栈表( Interrupt Stack Table , 下篇文章解释 )配置特定中断的栈切换也是可行的。
- 压入原来的栈指针:在中断发生的时候(对齐栈指针发生之前),CPU将栈指针(
rsp)和栈段(ss)寄存器压入栈中。如此一来,中断处理函数返回时就可以复原栈指针的原始值。 - 压入并更新
RFLAGS寄存器:RFLAGS寄存器保存了多种控制和状态位。进入中断函数时,CPU修改一些位并压入旧的值。 - 压入指令指针:跳转到中断处理函数之前,CPU压入指令指针(
rip)和代码段(cs)。这类似于寻常的函数调用压入返回地址的过程。 - 压入错误码(对于部分异常):对于缺页错误等特定的异常,CPU会压入解释异常原因的错误码。
- 调用中断处理函数:CPU从IDT对应的字段中读取中断处理函数的地址和段描述符。然后通过加载这些值到
rip和cs寄存器中,调用中断处理函数。
所以,中断调用栈帧会如下图所示:

在Rust的x86_64库中,中断调用栈帧被抽象为InterruptStackFrame结构体。它会被作为&mut传递给中断处理函数,并被用来获取更多的关于异常原因的信息。由于只有小部分异常会压入错误码,所以InterruptStackFrame并没有设置error_code字段。这些异常会另外使用HandlerFuncWithErrCode函数来处理,这个函数有一个error_code参数用来保存错误码。
幕后工作
x86-interrupt调用约定作为一个优秀的抽象,它几乎隐藏了异常处理过程中所有繁杂的细节。然而,理解幕布后的工作在某些时候是有益的。下面简要概述了x86-interrupt调用约定所处理的事情:
- 抽取参数:大多数调用约定希望参数被放在寄存器中传递。这对于异常处理函数是不可能的,因为我们不能在保存寄存器的值之前覆盖这些寄存器。然而,
x86-interrupt调用约定明白这些参数早就被放在栈的某个位置上了。 - 使用
iretq返回:既然中断栈帧和寻常函数调用的栈帧是不同的,我们不能使用ret指令从中断处理函数中返回。但是可以使用iretq指令。 - 处理错误码:部分特定异常压入的错误码是事情变得更加复杂。它改变了栈对齐(见对齐栈部分)并且需要在返回之前从栈中弹出。
x86-interrupt调用约定处理了所有难题。但是,它无法获得每种异常对应的处理函数,所以,它需要从函数的参数中推断这些信息。这意味着,程序员有责任使用正确的函数类型处理每种异常。幸运的是,x86_64库的InterruptDescriptorTable可以确保这一过程不会出错。 - 对齐栈:一些指令集(尤其是SSE指令集)使用16字节的栈对齐。在异常发生的时候,CPU会确保栈对齐。但是在压入错误码后,栈对齐会再次被破坏。
x86-interrupt调用约定会通过再次对齐栈解决这个问题。
如果你对更多的细节感兴趣:我们也有一系列文章解释了如何使用 naked functions处理异常。
实现
现在我们理解了这些理论,是时候在我们的内核中实现CPU异常处理了。我们首先在src/interrupts.rs中创建一个新的interrupts 模块,其中init_idt函数创建了一个新的InterruptDescriptorTable:
|
|
现在我们可以增加更多的处理函数。我们首先创建断点异常(breakpoint exception)的处理函数。断点异常是一个绝佳的测试处理异常过程的示例。它唯一的用途是在断点指令int3执行的时候暂停整个程序。
断点异常通常被用于调试程序(debugger):当用户设置了断点,调试程序会使用int3指令覆盖对应位置的指令,当CPU执行到这一位置的时候会抛出断点异常。当用户希望继续执行程序时,调试程序将int3指令替换回原来的指令并继续执行。可以从 "How debuggers work" 系列获取更多的细节。
我们无需覆盖任何指令。因为我们只希望程序在异常指令执行的时候打印一条消息,然后继续执行。让我们创建一个简单的断点异常处理函数(breakpoint_handler)并添加到IDT:
|
|
处理函数只输出了一条消息并美观的打印了中断栈帧。
当我们试图编译程序的时候,错误出现了:
|
|
这个错误是因为 x86-interrupt 中断调用约定仍然不稳定。我们需要明确地在lib.rs顶部增加#![feature(abi_x86_interrupt)]去激活它。
加载IDT
为了让CPU使用我们新的中断描述符表,我们需要使用 lidt 指令去加载它。x86_64 库的InterruptDescriptorTable 结构体提供了一个 load 方法去实现这个操作:
|
|
当我们试图编译程序的时候,下面的错误出现了:
|
|
load 方法期望一个 &'static self,以确保 idt 引用在整个程序生命周期中可用。因为CPU会在每个异常发生的时候访问这张表,直到我们加载了其它的InterruptDescriptorTable对象。所以,使用比 'static 短的生命周期会导致 use-after-free bug。
事实上,情况很明白。我们的 idt 在栈上创建,所以它只在 init 函数的生命周期中有效。一旦这个栈内存被其它函数重用,CPU会把随机的栈内存当作IDT。幸运的是, InterruptDescriptorTable::load 在函数定义中明确要求了必要的生命周期条件(译者注:也就是必须使用 'static 生命周期)。所以,Rust 编译器可以在编译期就阻止这个潜在的 bug 。
为了解决这个问题,我们需要保存我们的 idt 对象到拥有 'static 生命周期的地方。我们可以使用 Box 把 IDT 分配到堆上,并转换为 'static 引用,但是我们是在开发操作系统内核,所以并不会有堆这个概念。
作为代替,我们可以把 IDT 保存为 常量(static):
|
|
但是,这有一个问题:常量是不可变的,所以我们不能修改来自 init 函数的IDT中的断点条目。我们可以使用 static mut 解决这个问题:
|
|
这种变体不会出现编译错误,但是并不符合优雅的编程风格。 static mut 非常容易造成数据竞争,所以在每一次访问中都需要使用 unsafe 代码块。
懒加载常量
lazy_static 宏的存在令人庆幸。它可以让常量在被第一次使用的时候被初始化,而不是在编译期。因此,我们可以在初始化代码块中做几乎所有的事情,甚至读取常量在运行时的值。
我们已经在 created an abstraction for the VGA text buffer 引用了 lazy_static 库。所以我们可以直接使用 lazy_static! 宏去创建静态的IDT:
|
|
这种方法不需要 unsafe 代码块,因为 lazy_static! 宏在底层使用了 unsafe 代码块,但是抽象出了一个安全接口。
运行
让内核种的异常处理工作的最后一步是在 main.rs 中调用 init_idt 函数。在 lib.rs 中抽象一个总体的 init 函数而不是直接调用:
|
|
这个函数用来放置可以被 main.rs , lib.rs中的 _start 函数和集成测试所共享的初始化代码。
在 main.rs 中的 _start 函数中调用 init 函数,并触发一个断点异常。
|
|
使用 cargo run 命令在QEMU中运行程序:
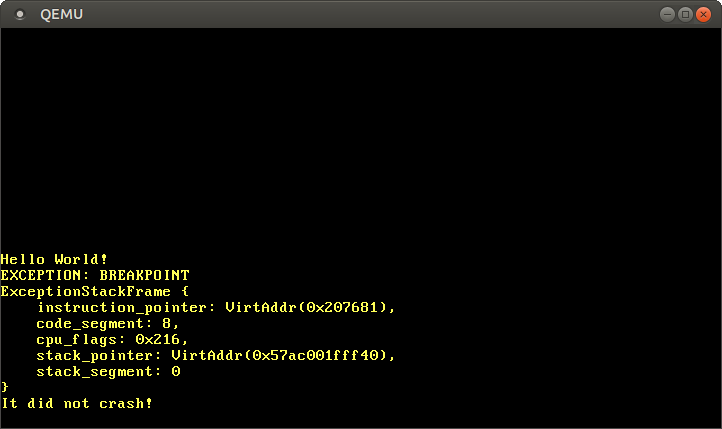
CPU成功调用了断点异常处理函数,并打印了一些消息,然后返回 _start 函数继续打印了 It did not crash! 消息。
可以发现,中断栈帧显示了中断发生时的指令和栈指针地址。这有助于调试不该发生的异常。
增加Test
增加一个确认上文中CPU继续工作的测试。首先,让 lib.rs 的 _start 函数同样调用 init 函数:
|
|
既然 lib.rs 中的测试完全独立于 main.rs ,必须使用命令 cargo test --lib 来指定运行 lib.rs 中的 _start 函数。在lib.rs 中的测试运行以前,我们需要调用 init 函数去建立IDT。
现在,创建一个 test_breakpoint_exception 测试:
|
|
这个测试调用了 x86_64 库的 int3 函数去触发断点异常。通过检查异常处理后程序继续执行,可以验证断点异常处理函数正常工作。
使用 cargo test (所有测试)或 cargo test --lib(只限于 lib.rs 和它的子模块中的测试)命令运行新的测试,应当可以看见:
|
|
过于抽象?( Too much Magic?)
x86-interrupt 调用约定和 InterruptDescriptorTable 让异常处理流程变得相当简单愉快。如果你觉得太过抽象或有兴趣学习异常处理更硬核的细节,“Handling Exceptions with Naked Functions” 系列会告诉你如何在不使用 x86-interrupt 调用约定的情况下处理异常并建立自己的IDT类型。在 x86-interrupt 调用约定和 x86_64 库问世以前,这个系列可以说是最主流的异常处理主体相关的博客。不得不提的是,这些文章基于第一版本的 Writing an OS in Rust ,所以可能会有些过时。
接下来?
我们成功地触发了第一个异常并从中返回!下一步是确保可以捕获所有异常,因为未被捕获地异常会引发严重的 triple fault ,继而导致系统复位。下一篇文章解释了如何通过捕获 双重异常 double faults 来避免这些问题。